
🔝🔝🔝🔝🔝🔝🔝🔝🔝🔝🔝🔝
🥰 博客首页:knighthood2001
😗 欢迎点赞👍评论🗨️
❤️ 热爱python,期待与大家一同进步成长!!❤️
跟我一起来刷题吧
先上结果,已成习惯(以下只截取了一部分)
| 本篇文章主要分成四个部分。即 ①原始视频逐帧提取 ②逐帧合成新视频 ③原始视频音频提取 ④音视频合成最终有声完整视频 |
目录
前期准备
首先我们需要准备一个视频(最好是mp4格式的)
文件目录如下(ikun文件夹可要可不要,因为待会会生成)
①原始视频逐帧提取
首先,导入cv2
import cv2
cap = cv2.VideoCapture('ikun.mp4')
fps = cap.get(cv2.CAP_PROP_FPS)
width = cap.get(cv2.CAP_PROP_FRAME_WIDTH)
height = cap.get(cv2.CAP_PROP_FRAME_HEIGHT)
frames = cap.get(cv2.CAP_PROP_FRAME_COUNT)
print('fps:', fps)
print('width:', width)
print('height:', height)
print('frames:', frames)cv2.VideoCapture(0)中参数0表示默认为笔记本内置第一个摄像头,若想要读取已有的视频,则改为视频所在地址。如上面的cv2.VideoCapture('ikun.mp4')
接下来就是调用函数,查看视频的帧率、宽度、高度、以及视频中图片总数(一帧表示一张图片)
结果如下:注意(以下返回的结果,其数据类型都是float类型,而不是int类型)
fps: 25.01398992725238
width: 854.0
height: 480.0
frames: 1490.0接下来我们创建一个用来存放提取出来的帧的文件夹,用os模块判断是否应该创建
# 创建一个新的目录,用来存放修改后的每一帧
path = 'ikun'
if not os.path.exists(path):
os.mkdir(path)接下来我们采用opencv非常常见的canny边缘检测
i = 0
while True:
flag, frame = cap.read()
# 转换成灰度
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# 图像处理(平滑)平均
blur = cv2.blur(gray, (3, 3))
# 应用对数变换
img_log = (np.log(blur+1)/(np.log(1+np.max(blur))))*255
# 指定数据类型
img_log = np.array(img_log, dtype=np.uint8)
# 图像平滑:双边滤波器
bilateral = cv2.bilateralFilter(img_log, 5, 75, 75)
# 边缘检测
edges = cv2.Canny(bilateral, 100, 200)
# 形态闭合算子
kernel = np.ones((5, 5), np.uint8)
closing = cv2.morphologyEx(edges, cv2.MORPH_CLOSE, kernel)
# todo
# 创建特征检测方法,nfeatures参数0默认为500
orb = cv2.ORB_create(nfeatures=1500)
# 制作特色图片
keypoints, descriptors = orb.detectAndCompute(closing, None)
featuredImg = cv2.drawKeypoints(closing, keypoints, None)
filename = path + '/{}.jpg'.format(str(i))
print(filename)
# 保存图片
cv2.imwrite(filename, featuredImg)
i = i + 1
# 如果i大于图片总数,则退出
if i > int(frames):
break首先,检测边缘不需要彩色信息,因此转为灰度图,此外,边缘检测的算法对噪声很敏感,所以采用滤波器来改善边缘检测器的性能。
接着我们使用OpenCV的ORB角点检测,ORB算法是FAST算法和BRIEF算法的结合,ORB可以用来对图像中的关键点快速创建特征向量,并用这些特征向量来识别图像中的对象。当然你也可以采用其他方法。
①实例化ORB
orb = cv2.ORB_create(nfeatures=1500)参数:
- nfeatures:特征点的最大数量
②利用orb.detectAndCompute()检测关键点并计算
keypoints, descriptors = orb.detectAndCompute(closing, None)
③将关键点检测结果绘制在图像上
cv2.drawKeypoints(image, keypoints, outputimage, color, flags)参数:
- image: 原始图像
- keypoints:关键点信息,将其绘制在图像上
- outputimage:输出图片,可以是原始图像
- color:颜色设置,通过修改(b,g,r)的值,更改画笔的颜色,b=蓝色,g=绿色,r=红色。
- flags:绘图功能的标识设置
这里笔者搞得比较简单
featuredImg = cv2.drawKeypoints(closing, keypoints, None)④保存图片
filename = path + '/{}.jpg'.format(str(i))
# 保存图片
cv2.imwrite(filename, featuredImg)最后使用i判断是否将每张图都进行更改并保存。
②逐帧合成新视频
import cv2
size = (854, 480)
# todo
videowrite = cv2.VideoWriter('output_ikun.mp4', -1, 25, size)
# 'output_ikun.mp4'是视频保存的文件,25是帧数,size是图片尺寸
n = 1490
path = 'ikun'
'''1'''
# img_array = []
# for filename in ['ikun1/{0}.jpg'.format(i) for i in range(n)]:
# # print(filename)
# img = cv2.imread(filename)
# if img is None:
# print(filename + " is error!")
# continue
# img_array.append(img)
# for i in range(n):#把读取的图片文件写进去
# videowrite.write(img_array[i])
# videowrite.release()
# print('end!')
'''2'''
# img_arr = []
# for i in range(n):
# img = cv2.imread(path + "/{}.jpg".format(i))
# img_arr.append(img)
# for i in range(n):
# videowrite.write(img_arr[i])
# videowrite.release()
# print('end!')
'''3'''
for i in range(n):
img = cv2.imread(path + "/{}.jpg".format(i))
videowrite.write(img)
videowrite.release()
print('end!')代码如上
其中size为①原始视频逐帧提取中获取到的宽和高(注意:这里的size笔者尝试了,应该要和获取到的宽和高一样,否则报错)
n就是获取到的总图片数
#注释掉的代码由于比较复杂,笔者将其简化在下面了。
③原始视频音频提取
import moviepy.editor as mp
def extract_audio(videos_file_path):
# print(videos_file_path)
# print(videos_file_path.split('.')[0])
my_clip = mp.VideoFileClip(videos_file_path)
my_clip.audio.write_audiofile(f'{videos_file_path.split(".")[0]}.mp3')
extract_audio('ikun.mp4')
视频提取音频,这里笔者采用的是moviepy模块,这里就不细细道来了,之后有机会可以好好和大家讲一讲该模块。
这里的videos_file_path是原始视频地址。
④音视频合成最终有声完整视频
import moviepy.editor as mp
video = mp.VideoFileClip('output_ikun.mp4')
audio = mp.AudioFileClip('ikun.mp3')
video_merge = video.set_audio(audio)
video_merge.write_videofile('final_ikun.mp4')同上
video是我们新制作的无声音的mp4;
audio是我们从原视频分离出来的音频;
最终音视频合并在final_ikun.mp4中。
图片展示

呀,搞错了,这是下一期内容

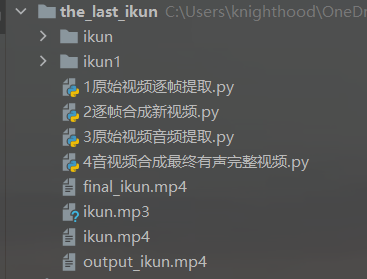
以下是最终目录
总结
学了以上内容,你会对opencv更加感兴趣,去尝试是否能调出更好的图片以及视频。
最重要的一点:本文仅探讨技术,采用上述的例子,只是希望你能对opencv更加感兴趣!!
下期预告:如上图的上图所示!
转载自CSDN-专业IT技术社区
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/knighthood2001/article/details/126046233

