
https://github.com/ultralytics/ultralytics
环境配置
官方环境要求
Python>=3.7(我是python==3.8也是可以用的) environment with PyTorch>=1.7.
这是ultralytics
Command Line Interface命令行接口运行
输入参数的格式
yolo TASK MODE ARGS
逐个参数该写什么的解释
TASK (optional) is one of [detect, segment, classify]. If it is not passed explicitly YOLOv8 will try to guess the TASK from the model type.
这个参数一般是不写,让代码根据加载的模型的里面的设定,选择是使用 识别、分割、分类中的哪一个功能
MODE (required) is one of [train, val, predict, export]
ARGS (optional) are any number of custom arg=value pairs like imgsz=320 that override defaults. For a full list of available ARGS see the Configuration page and defaults.yaml GitHub source.
参数介绍列表: https://docs.ultralytics.com/cfg/
这个参数有很多,我挑出一个经常用的介绍给你
source,写图片或视频的路径+文件名;
Key | Value | Description |
source | ||
图片
在线图片
yolo predict model=yolov8n.pt source="https://ultralytics.com/images/bus.jpg"会输出里面有几辆车,几个人,各种object有多少个
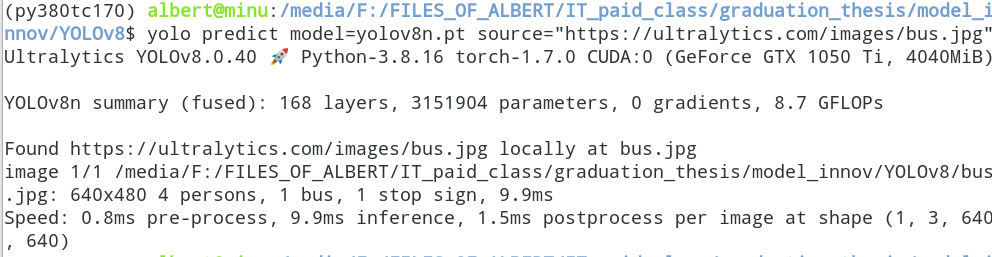
jpg: 640x480 4 persons, 1 bus, 1 stop sign, 9.9ms本地图片
yolo predict model=yolov8n.pt source="./bus.jpg" 640x480 4 persons, 1 bus, 1 stop sign, 9.7ms不传参
source这个参数不传参,默认调用这张网络图片( https://ultralytics.com/images/bus.jpg ),进行识别
yolo predict model=yolov8n.pt imgsz=640 conf=0.25# .jpg: 640x480 4 persons, 1 bus, 1 stop sign, 9.2ms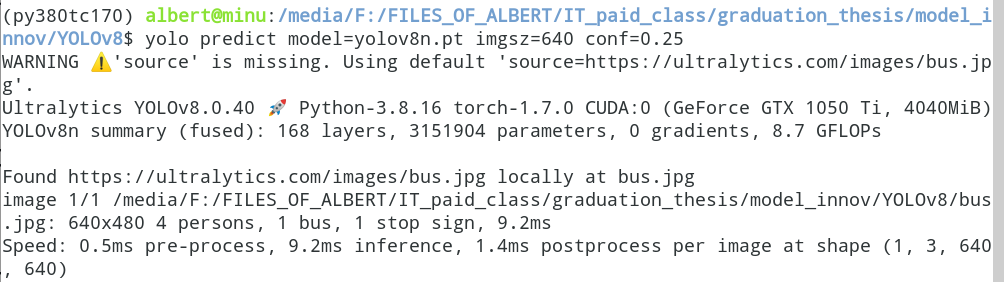
视频
yolo predict model=yolov8n.pt source="./dandong.mp4"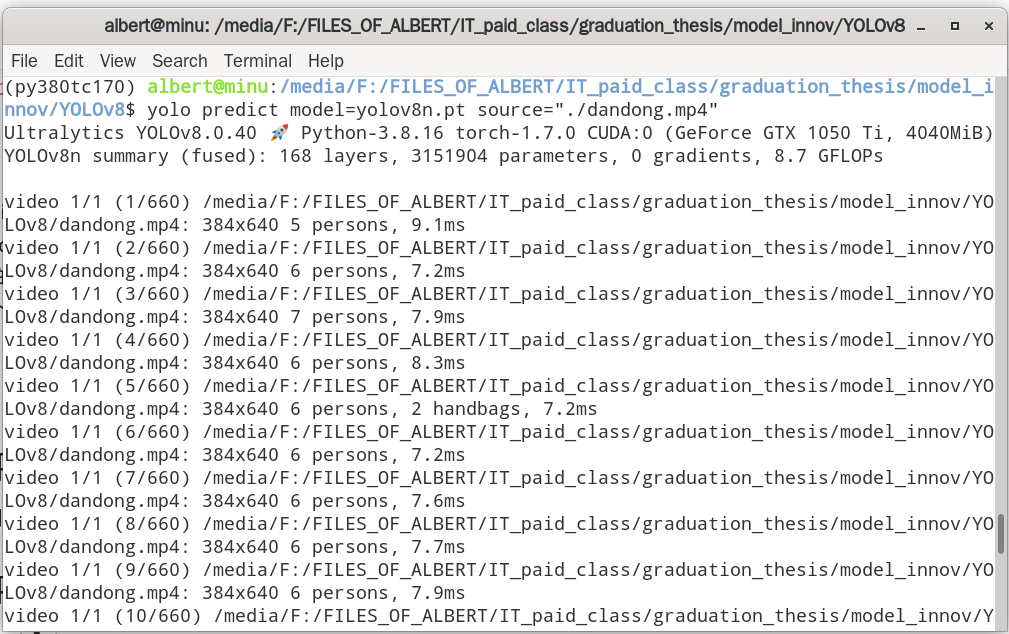
(1)我要求识别的过程(尤其是视频识别的过程),要在窗口显示(2)识别的结果要保存下来,以视频文件或图片文件的形式
命令行各种参数的列表https://docs.ultralytics.com/cfg/
多目标追踪的功能用一用,写一下教程——https://docs.ultralytics.com/tasks/tracking/
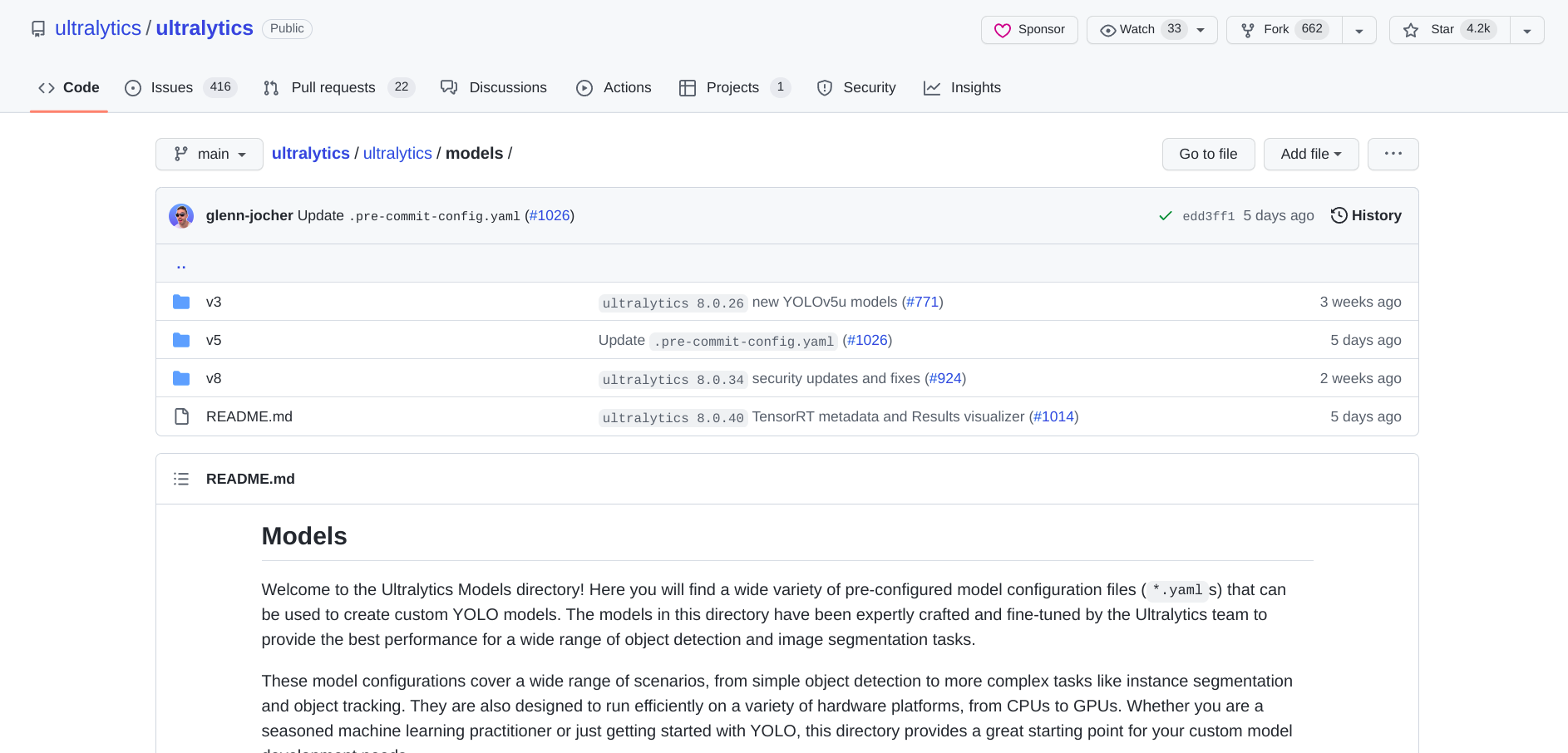
作者将v3 v5 v8都整合在Ultralytics这一个包里面了。那么请问我通过什么方式,什么参数,可以分别调用v3,v5,v7??
https://github.com/ultralytics/ultralytics/tree/main/ultralytics/models
转载自CSDN-专业IT技术社区
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/Albert233333/article/details/129464207

