
KNN:K nearest neighbor,是一种分类算法,其中的K是人工指定的邻居个数,K常用交叉验证法进行确定。也称为:K近邻算法,K个最近的邻居。
knn不需要训练模型或者模型中的任意参数,当拿到一个新的样本需要进行分类,那么之前所有的样本都会当作模型数据进行计算。
目录
一,K的确定
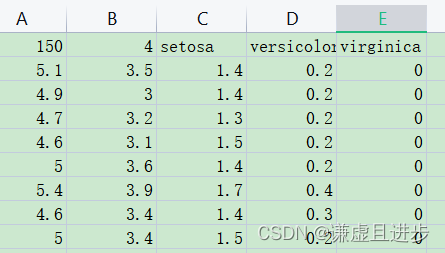
下面的代码来自:链接。令k依次等于1-30,看一下哪一个k造成的error最小。iris数据集是一个150×5的二维数据集,分类类别为3,如果是其他形式数据集的话下面代码可能不适用。数据集位于Lib\site-packages\sklearn\datasets\data。
iris数据集:
代码块:
from sklearn.datasets import load_iris
from sklearn.model_selection import cross_val_score
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsClassifier
#加载鸢尾花数据集
iris = load_iris()
x = iris.data
y = iris.target
k_range = range(1, 31) # 设置循环次数
k_error = []
#循环,取k从1~30,查看误差效果
for k in k_range:
knn = KNeighborsClassifier(n_neighbors=k)
#cv参数决定数据集划分比例,这里是按照5:1划分训练集和测试集
scores = cross_val_score(knn, x, y, cv=6, scoring='accuracy')
k_error.append(1 - scores.mean())
#画图,x轴为k值,y值为误差值
plt.plot(k_range, k_error)
plt.xlabel('Value of K in KNN')
plt.ylabel('Error')
plt.show()
二,knn原理
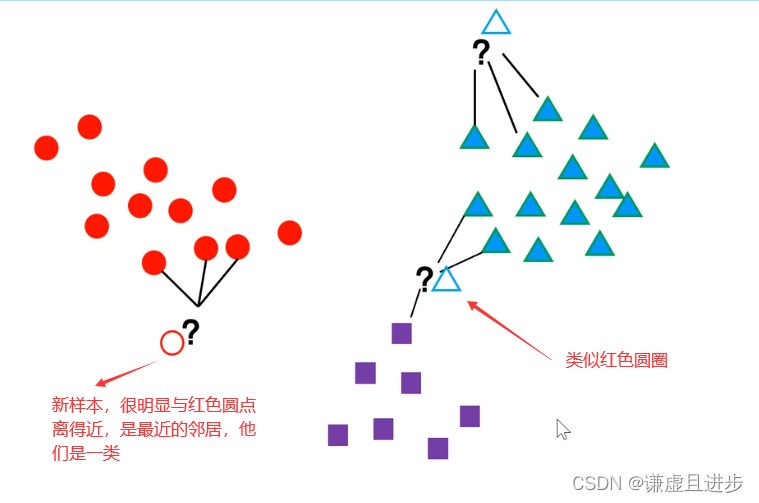
给定一个样本,具有n维特征。通过计算新样本与已知样本的欧氏距离,依据k来进行划分,如果新样本与这k个点之间的距离最近,则新样本与这k个点属于一个类别。
关键在于距离的计算,不同的问题往往这个距离的定义不一样。 很明显这里的距离不是指平面两点之间的距离,而是特征之间的某种联系。
k取值越小,则新样本的k个邻居与其最接近,造成过拟合。k取值越大,可能造成有的邻居其实是其他类别但是被当作了邻居,而且这些假邻居太多造成分类失败。
三,代码解析
最后k个邻居中属于某个类别的最多,则新样本属于该类别。
四,对iris数据集进行knn分类并计算准确度
4.1python代码
import numpy as np
import operator
'''
trainData - 训练集 N
testData - 测试 1
labels - 训练集标签
'''
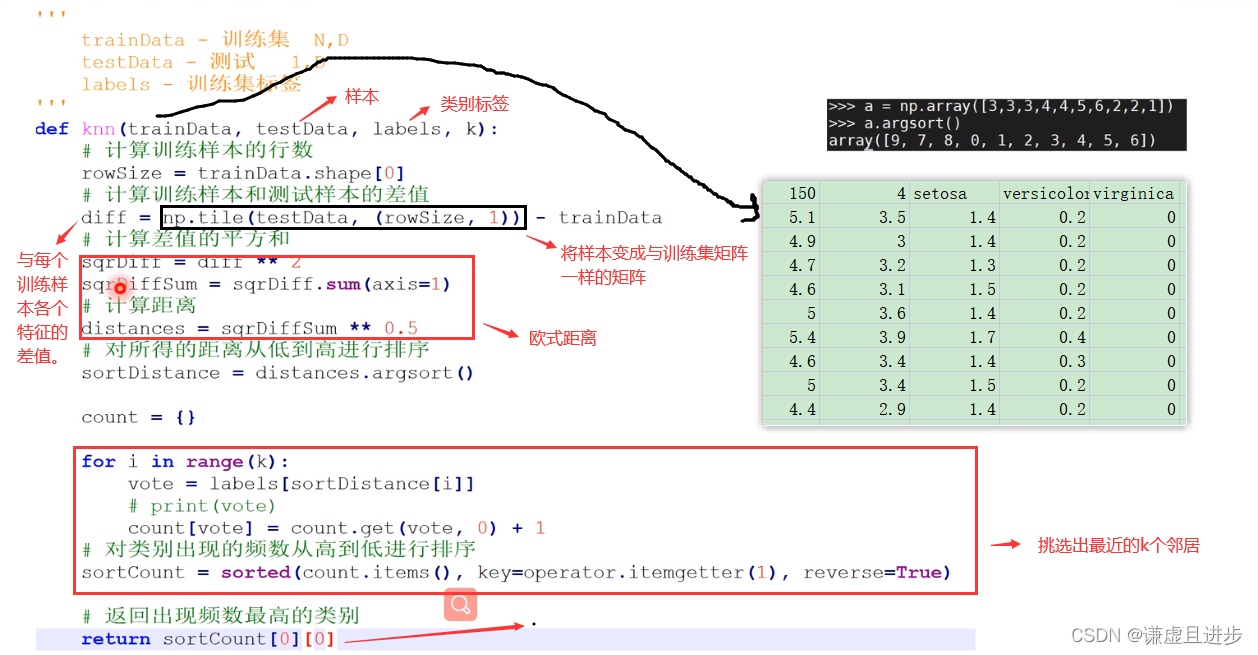
def knn(trainData, testData, labels, k):
# 计算训练样本的行数
rowSize = trainData.shape[0]
# 计算训练样本和测试样本的差值
diff = np.tile(testData, (rowSize, 1)) - trainData
# 计算差值的平方和
sqrDiff = diff ** 2
sqrDiffSum = sqrDiff.sum(axis=1)
# 计算距离
distances = sqrDiffSum ** 0.5
# 对所得的距离从低到高进行排序
sortDistance = distances.argsort()
count = {}
for i in range(k):
vote = labels[sortDistance[i]]
# print(vote)
count[vote] = count.get(vote, 0) + 1
# 对类别出现的频数从高到低进行排序
sortCount = sorted(count.items(), key=operator.itemgetter(1), reverse=True)
# 返回出现频数最高的类别
return sortCount[0][0]
file_data = 'iris.data'
# 数据读取
data = np.loadtxt(file_data,dtype = float, delimiter = ',',usecols=(0,1,2,3))
lab = np.loadtxt(file_data,dtype = str, delimiter = ',',usecols=(4))
# 分为训练集和测试集
N = 150
N_train = 100
N_test = 50
perm = np.random.permutation(N)
index_train = perm[:N_train]
index_test = perm[N_train:]
data_train = data[index_train,:]
lab_train = lab[index_train]
data_test = data[index_test,:]
lab_test = lab[index_test]
# 参数设定
k= 11
n_right = 0
for i in range(N_test):
test = data_test[i,:]
det = knn(data_train, test, lab_train, k)
if det == lab_test[i]:
n_right = n_right+1
print('Sample %d lab_ture = %s lab_det = %s'%(i,lab_test[i],det))
# 结果分析
print('Accuracy = %.2f %%'%(n_right*100/N_test))
4.2数据集地址
地址。链接:https://pan.baidu.com/s/1z_4TfsFn-d2cOQvYKCv94g?pwd=i0ka 。
转载自CSDN-专业IT技术社区
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/weixin_44992737/article/details/127153739

