
我们先看一下效果2023年最新版
yolo车距
行人识别yolov5和v7对比
yolo车距
其他步骤参考另外一篇文章:
最新代码:
(直接预测就好,已经是成品,无须看下文)商品详情![]() http://www.hedaoapp.com/goods/goodsDetails?pid=4132
http://www.hedaoapp.com/goods/goodsDetails?pid=4132
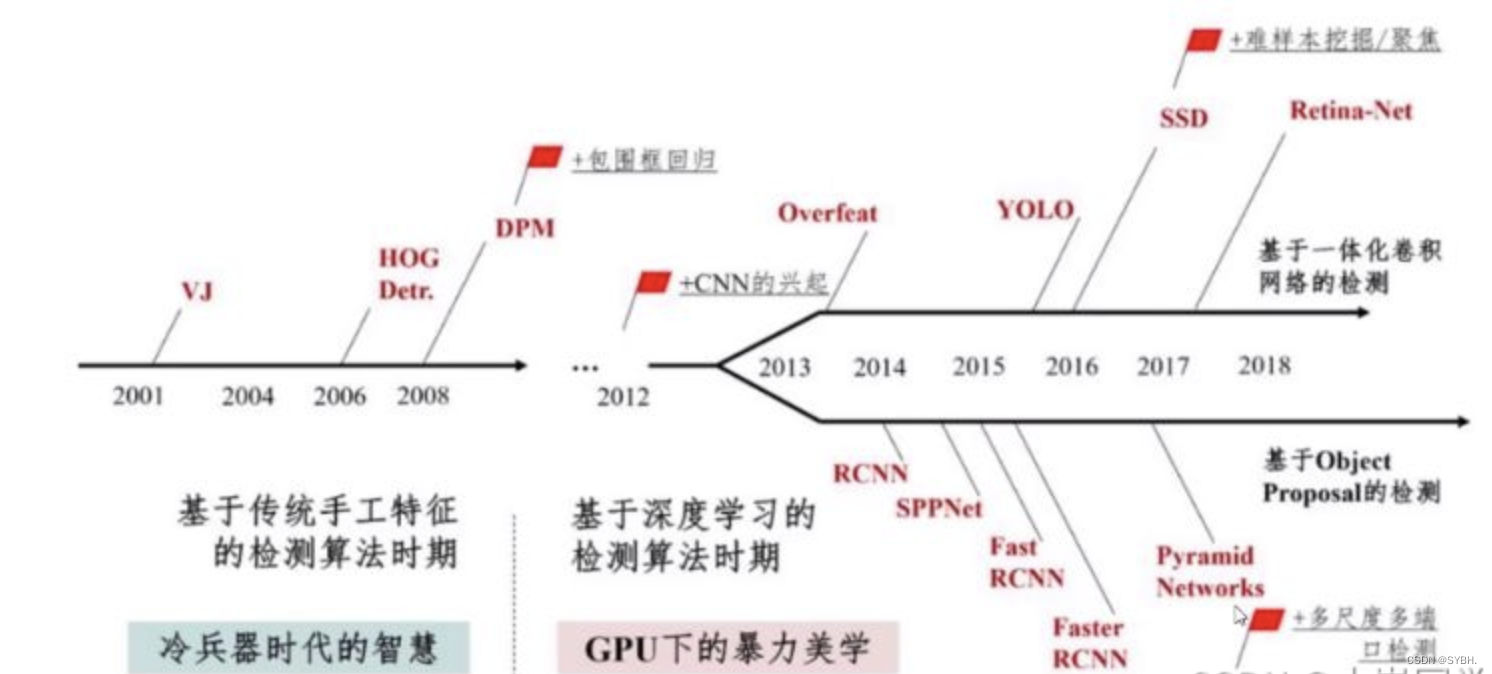
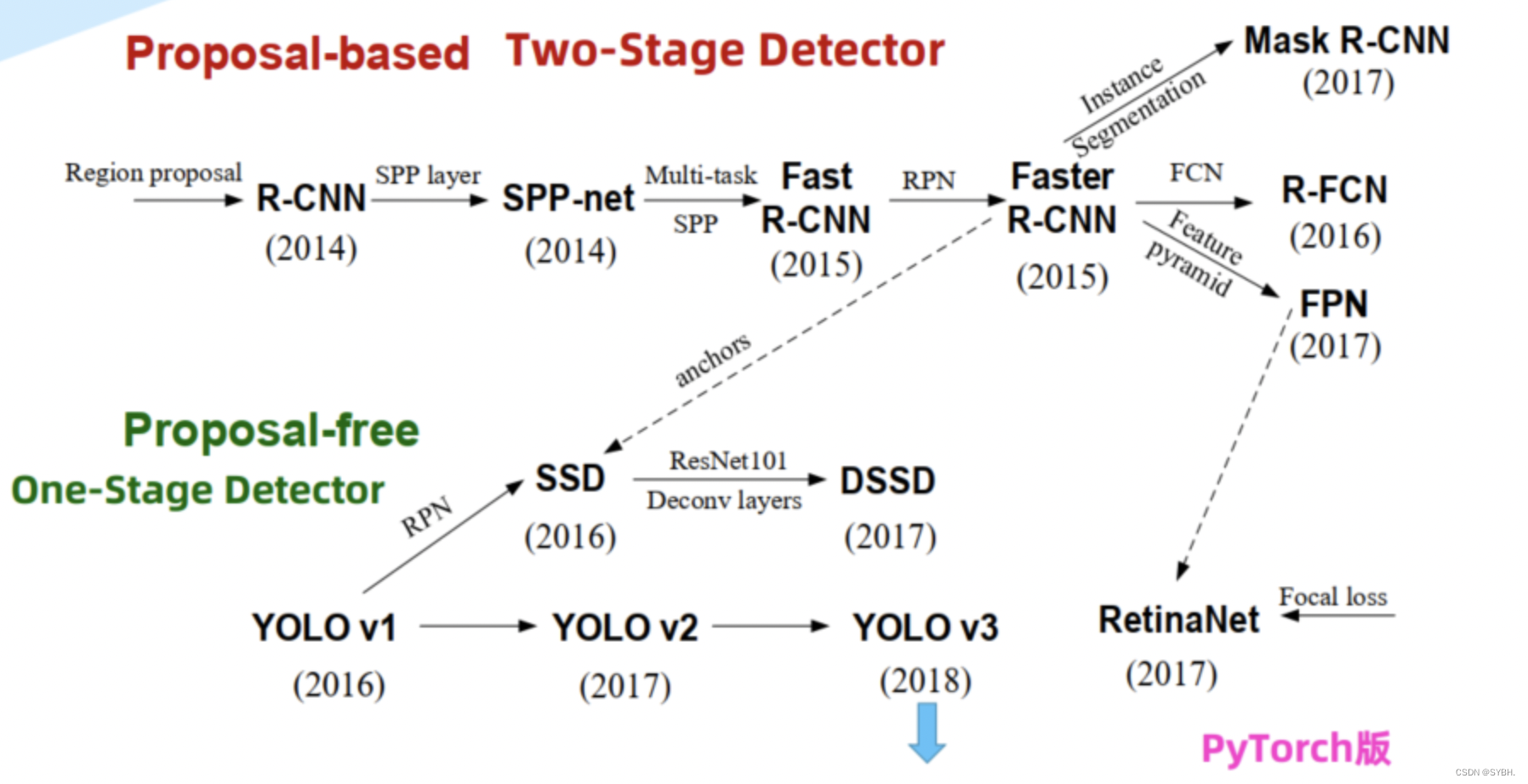
先看一下yolo发展史
二、单目测距原理
图中有一个车辆,且车辆在地面上,其接地点Q必定在地面上。那么Q点的深度便可以求解出来。具体求解步骤懒得打公式了,就截图了。在单目测距过程中,实际物体上的Q点在成像的图片上对应Q’点,Q’点距离o1点沿y轴的距离为o1p’。这个距离o1p’除以y轴像素焦距fy (单位为pixel) ,再求arctan即可得到角度b’。然后按图中步骤很容易理解了。
三、准备工作
参考我这篇文章:
第一步:将整个代码从github上下载下来,
网址:GitHub - ultralytics/yolov5: YOLOv5 🚀 in PyTorch > ONNX > CoreML > TFLite
也可以直接到GitHub上搜yolov5
主要是安装版本与配置声明中所需在库。
matplotlib>=3.2.2
numpy>=1.18.5
opencv-python>=4.1.2
Pillow
PyYAML>=5.3.1
scipy>=1.4.1
torch>=1.7.0
torchvision>=0.8.1
tqdm>=4.41.0
tensorboard>=2.4.1
seaborn>=0.11.0
pandas
pycocotools>=2.0 # COCO mAP
albumentations>=1.0.2
(1)安装pytorch(建议安装gpu版本cpu版本太慢)
这些库中可能就pytorch比较难安装,其他库用pip install 基本能实现。
可直接在Anaconda Prompt里输入:
pip install torch==1.7.0+cu101 torchvision==0.8.1+cu101 torchaudio===0.7.0 -f https://download.pytorch.org/whl/torch_stable.html
1.运行检测
下载完yolov5后,运行detect,可以帮助我们检查上面的环境是不是安装成功。
如果运行不报错,我们会在runs//detect//exp 文件夹下看到两张已经预测出的照片。
3.运行检测
下载完yolov5后,运行detect,可以帮助我们检查上面的环境是不是安装成功。
如果运行不报错,我们会在runs//detect//exp 文件夹下看到两张已经预测出的照片。
如果报错,问题也不大,看就是安装的环境版本比较低或者没安装,我们稍微调试一下就OK了。
五、数据集
我们先要创建几个文件夹用来存放数据和模型。
在yolov5-master如下图所示文件夹
1.制作标签
这里我是以穿越火线为例,提供100个已经标记好的数据(放在文末)。你也可以自己标记,一百张效果不是很好,可以多标记几张。
(1)安装labelme
在Anaconda Prompt里pip install labelme
(2)使用labelme
在Anaconda Prompt里输入labelme,会弹出一个窗口。
然后打开图片所在的文件夹
点击rectangle,标记想要识别的东西。
环境准备
Anaconda 4.10.3 Tensorflow 2.6.0 python3.7.8 coding: utf-8 pycharm解释器:D:\Anaconda\envs\tensorflow\python.exe 以及各种第三方库
思路流程
1、将图片通过opencv切割识别定位车牌,切割保存
2、识别省份简称、识别城市代号、识别车牌编号
功能描述
car_num_main.py :将图片转为灰度图像,灰度图像二极化,分割图像并分别保存为.jpg和.bmp文件 train-license-province.py : 省份简称训练识别 train-license-letters.py :城市代号训练识别 train-license-digits.py :车牌编号训练识别
细节阐述
1、图片切割后分别保存在两个文件夹./img_cut and ./img_cut_not_3240 2、识别车牌需进入终端,在命令行中进入脚本所在目录, 输入执行如下命令:python train-license-province.py train 进行省份简称训练 输入执行如下命令:python train-license-province.py predict 进行省份简称识别 输入执行如下命令:python train-license-letters.py train 进行城市代号训练 输入执行如下命令:python train-license-letters.py predict 进行城市代号识别 输入执行如下命令:python train-license-digits.py train 进行车牌编号训练 输入执行如下命令:python train-license-digits.py predict 进行车牌编号识别 3、将要识别的图片调为.jpg格式,大小调为像素600*413最佳,可依据代码酌情调试 4、具体可以准确识别的车牌号参见数据集中训练集
项目总体框架
capture_img :存放将要识别的车牌图片
img_cut:运行car_num_main.py后生成切割后的图片
img_cut_not_3240 :运行 car_num_main.py 后生成切割后的图片(对比度加强)
test_images:存放测试图片
train_images: 存放训练图片
train-saver: 训练模型
过程展示
PS D:\pycharm\pycharm_work> cd .\chepai\
PS D:\pycharm\pycharm_work\chepai> python train-license-province.py train
复制代码PS D:\pycharm\pycharm_work\chepai> python train-license-province.py predict
复制代码PS D:\pycharm\pycharm_work\chepai> python train-license-digits.py predict
复制代码技术简介
一、Tensorflow
TensorFlow是一个开放源代码软件库,用于进行高性能数值计算。借助其灵活的架构,用户可以轻松地将计算工作部署到多种平台(CPU、GPU、TPU)和设备(桌面设备、服务器集群、移动设备、边缘设备等)。
TensorFlow 是一个用于研究和生产的开放源代码机器学习库。TensorFlow 提供了各种 API,可供初学者和专家在桌面、移动、网络和云端环境下进行开发。
TensorFlow是采用数据流图(data flow graphs)来计算,所以首先我们得创建一个数据流流图,然后再将我们的数据(数据以张量(tensor)的形式存在)放在数据流图中计算。节点(Nodes)在图中表示数学操作,图中的边(edges)则表示在节点间相互联系的多维数据数组, 即张量(tensor)。训练模型时tensor会不断的从数据流图中的一个节点flow到另一节点。
二、OpenCV
OpenCV是一个基于BSD许可(开源)发行的跨平台计算机视觉和机器学习软件库,可以运行在Linux、Windows、Android和Mac OS操作系统上。它轻量级而且高效——由一系列 C 函数和少量 C++ 类构成,同时提供了Python、Ruby、MATLAB等语言的接口,实现了图像处理和计算机视觉方面的很多通用算法。
OpenCV提供的视觉处理算法非常丰富,并且它部分以C语言编写,加上其开源的特性,处理得当,不需要添加新的外部支持也可以完整的编译链接生成执行程序,所以很多人用它来做算法的移植,OpenCV的代码经过适当改写可以正常的运行在DSP系统和ARM嵌入式系统中。其应用领域诸如:人机互动,物体识别,图像分割,人脸识别,动作识别,运动跟踪,机器人,运动分析,机器视觉,结构分析,汽车安全驾驶等领域。
系统设计
车牌自动识别是以计算机视觉处理、数字图像处理、模式识别等技术为基础,对摄像机所拍摄的车辆图像或者视频图像进行处理分析,得到每辆车的车牌号码,从而完成识别的过程。在此基础上,可实现停车场出入口收费管理、盗抢车辆管理、高速公路超速自动化管理、闯红灯电子警察、公路收费管理等各种交通监管功能。
一、系统处理流程
车牌自动识别系统的设计包含车辆图像获取、车牌区域定位、车牌特征轮廓提取和车牌内容识别环节。
二、车牌获取
车牌图像获取是进行车牌识别的首要环节,车牌图像可以从摄像机拍摄的车辆图像或者视频图像中进行抽取,车牌图像的获取也可由用户手机拍摄后传入车牌识别系统。
三、灰度图像生成
摄像机拍摄的含有车牌信息的车辆图像是彩色的,为了提高车牌识别的抗外界干扰的能力,先将彩色车辆图像生成二值的灰度图像,实现基于色调的车牌区域定位。由于国内的车牌往往是蓝底白字,因此,可以利用图像的色调或者色彩饱和度特征,生成二值灰度图像,从而实现更加准确地定位车牌位置。
四、车牌区域定位
车牌区域的定位采用基于形状的方法。由于车辆图像背景比较复杂,所以应该根据车牌的特征进行初次筛选。车牌的特征可以选择中国车牌的大小、比例特征,因为车牌都是固定的矩形形状,通过首先寻找图像上拥有矩形特征的区域,然后再抽取这些区域,再结合车牌的长宽的比例特征可以筛选出相应的矩形区域,从而实现对车牌的准确定位。
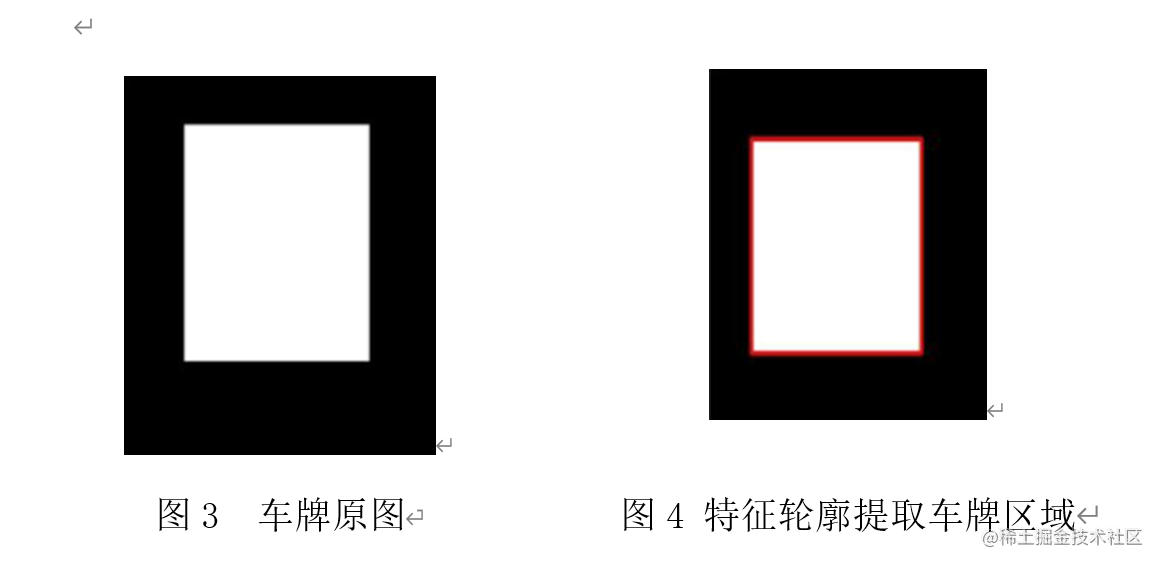
五、特征轮廓提取
OpenCV 与 Python 的接口中使用 cv2.fifindContours() 函数来查找检测物体的轮廓。
图3 和 图4 为特征轮廓提取前后的效果对比图 :
六、车牌内容识别
车牌内容识别时,通过计算候选车牌区域蓝色数值(均值)的最大值,确定最终的车牌区域。对于选定的车牌轮廓,首先进行粗定位,即对车牌进行左右边界回归处理,去除车牌两边多余的部分,然后进行精定位,即将车牌送入 CRNN 网络进行字符识别,利用左右边界回归模型,预测出车牌的左右边框,进一步裁剪,进行精定位。基于文字特征的方法是根据文字轮廓特征进行识别,经过相应的算法解析,得到结果。
项目实现
核心代码展现
一、检测车牌
def find_car_num_brod():
watch_cascade = cv2.CascadeClassifier('D:\pycharm\pycharm_work\chepai\cascade.xml')
# 先读取图片
image = cv2.imread("D:\pycharm\pycharm_work\chepai\capture_img\car1.jpg")
resize_h = 1000
height = image.shape[0]
scale = image.shape[1] / float(image.shape[0])
image = cv2.resize(image, (int(scale * resize_h), resize_h))
image_gray = cv2.cvtColor(image, cv2.COLOR_RGB2GRAY)
watches = watch_cascade.detectMultiScale(image_gray, 1.2, 2, minSize=(36, 9), maxSize=(36 * 40, 9 * 40))
print("检测到车牌数", len(watches))
for (x, y, w, h) in watches:
cv2.rectangle(image, (x, y), (x + w, y + h), (0, 0, 255), 1)
cut_img = image[y + 5:y - 5 + h, x + 8:x + w] # 裁剪坐标为[y0:y1, x0:x1]
cut_gray = cv2.cvtColor(cut_img, cv2.COLOR_RGB2GRAY)
cv2.imwrite("D:\pycharm\pycharm_work\chepai\num_for_car.jpg", cut_gray)
im = Image.open("D:\pycharm\pycharm_work\chepai\num_for_car.jpg")
size = 720, 180
mmm = im.resize(size, Image.ANTIALIAS)
mmm.save("D:\pycharm\pycharm_work\chepai\num_for_car.jpg", "JPEG", quality=90)
break
复制代码二、二值化图像
def cut_car_num_for_chart():
# 1、读取图像,并把图像转换为灰度图像并显示
img = cv2.imread("D:\pycharm\pycharm_work\chepai\num_for_car.jpg") # 读取图片
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 转换了灰度化
cv2.imshow('gray', img_gray) # 显示图片
cv2.waitKey(0)
# 2、将灰度图像二值化,设定阈值是100 转换后 白底黑字 ---》 目标黑底白字
img_thre = img_gray
# 灰点 白点 加错
# cv2.threshold(img_gray, 130, 255, cv2.THRESH_BINARY_INV, img_thre)
# 二值化处理 自适应阈值 效果不理想
# th3 = cv2.adaptiveThreshold(img_gray, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 11, 2)
# 高斯除噪 二值化处理
blur = cv2.GaussianBlur(img_gray, (5, 5), 0)
ret3, th3 = cv2.threshold(blur, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
cv2.imshow('threshold', th3)
cv2.imwrite('D:\pycharm\pycharm_work\chepai\wb_img.jpg', th3)
cv2.waitKey(0)
复制代码第一行imread(),由于flag设为1所以读的是彩图,采用cvtColor函数转化为灰度图。如果你读入就是灰度图可以省略第二行代码,然后转化为二值化函数,阈值180可以修改,后经过增强处理,效果如图所示:
三、单字符切割
单字符分割主要策略就是检测列像素的总和变化,因为没有字符的区域基本是黑色,像素值低;有字符的区域白色较多,列像素和就变大了!
列像素变化的阈值是个问题,看到很多博客是固定的阈值进行检测,除非你处理后的二值化图像非常完美,不然有的图片混入了白色区域就会分割错误!
考虑到车牌中只有7个字符,所以先判断得到宽度大小,如果小于总宽的七分之一视为干扰放弃;其实也可以加大到总宽的8分之一(因为车牌中间可能有连接符)。
n = 1
start = 1
end = 2
temp = 1
while n < width - 2:
n += 1
if (white[n] if arg else black[n]) > (0.05 * white_max if arg else 0.05 * black_max):
# 上面这些判断用来辨别是白底黑字还是黑底白字
# 0.05这个参数请多调整,对应上面的0.95
start = n
end = find_end(start, white, black, arg, white_max, black_max, width)
n = end
# 车牌框检测分割 二值化处理后 可以看到明显的左右边框 毕竟用的是网络开放资源 所以车牌框定位角度真的不准,
# 所以我在这里截取单个字符时做处理,就当亡羊补牢吧
# 思路就是从左开始检测匹配字符,若宽度(end - start)小与20则认为是左侧白条 pass掉 继续向右识别,否则说明是
# 省份简称,剪切,压缩 保存,还有一个当后五位有数字 1 时,他的宽度也是很窄的,所以就直接认为是数字 1 不需要再
# 做预测了(不然很窄的 1 截切 压缩后宽度是被拉伸的),
# shutil.copy()函数是当检测到这个所谓的 1 时,从样本库中拷贝一张 1 的图片给当前temp下标下的字符
if end - start > 5: # 车牌左边白条移除
print(" end - start" + str(end - start))
if temp == 1 and end - start < 20:
pass
elif temp > 3 and end - start < 20:
# 认为这个字符是数字1 copy 一个 32*40的 1 作为 temp.bmp
shutil.copy(
os.path.join("D:\pycharm\pycharm_work\chepai\fuzhi", "111.bmp"), # 111.bmp 是一张 1 的样本图片
os.path.join("D:\pycharm\pycharm_work\chepai\img_cut\", str(temp) + '.bmp'))
pass
else:
cj = th3[1:height, start:end]
cv2.imwrite("D:\pycharm\pycharm_work\chepai\img_cut_not_3240\" + str(temp) + ".jpg", cj)
im = Image.open("D:\pycharm\pycharm_work\chepai\img_cut_not_3240\" + str(temp) + ".jpg")
size = 32, 40
mmm = im.resize(size, Image.ANTIALIAS)
mmm.save("D:\pycharm\pycharm_work\chepai\img_cut\" + str(temp) + ".bmp", quality=95)
temp = temp + 1
复制代码车牌的切割效果如图所示:
四、单字符识别
max1 = 0
max2 = 0
max3 = 0
max1_index = 0
max2_index = 0
max3_index = 0
for j in range(NUM_CLASSES):
if result[0][j] > max1:
max1 = result[0][j]
max1_index = j
continue
if (result[0][j] > max2) and (result[0][j] <= max1):
max2 = result[0][j]
max2_index = j
continue
if (result[0][j] > max3) and (result[0][j] <= max2):
max3 = result[0][j]
max3_index = j
continue
license_num = license_num + LETTERS_DIGITS[max1_index]
print("概率: [%s %0.2f%%] [%s %0.2f%%] [%s %0.2f%%]" % (
LETTERS_DIGITS[max1_index], max1 * 100, LETTERS_DIGITS[max2_index], max2 * 100, LETTERS_DIGITS[max3_index],
max3 * 100))
print("车牌编号是: 【%s】" % license_num)
复制代码最终效果如图所示:
注:此图为以下三个程序的运行结果图,我将图片拼接到一块了。。
train-license-province.py : 省份简称训练识别 train-license-letters.py :城市代号训练识别 train-license-digits.py :车牌编号训练识别
最后
车牌识别做不到100%识别成功,但通过训练已经基本可以达到98%以上的识别度,可以将capture_img文件中的图片(注意图片格式与大小会间接影响识别度,车牌名改为 car1.jpg)替换为自己的车牌照通过训练进行识别车牌照。
转载自CSDN-专业IT技术社区
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/m0_68036862/article/details/128667487

