
前言
相关性分析算是很多算法以及建模的基础知识之一了,十分经典。关于许多特征关联关系以及相关趋势都可以利用相关性分析计算表达。其中常见的相关性系数就有三种:person相关系数,spearman相关系数,Kendall's tau-b等级相关系数。各有各自的用法和使用场景。当然关于这以上三种相关系数的计算算法和原理+代码我都会在我专栏里面写齐全。目前关于数学建模的专栏已经将传统的机器学习预测算法、维度算法、时序预测算法和权重算法写的七七八八了,有这个需求兴趣的同学可以去看看。
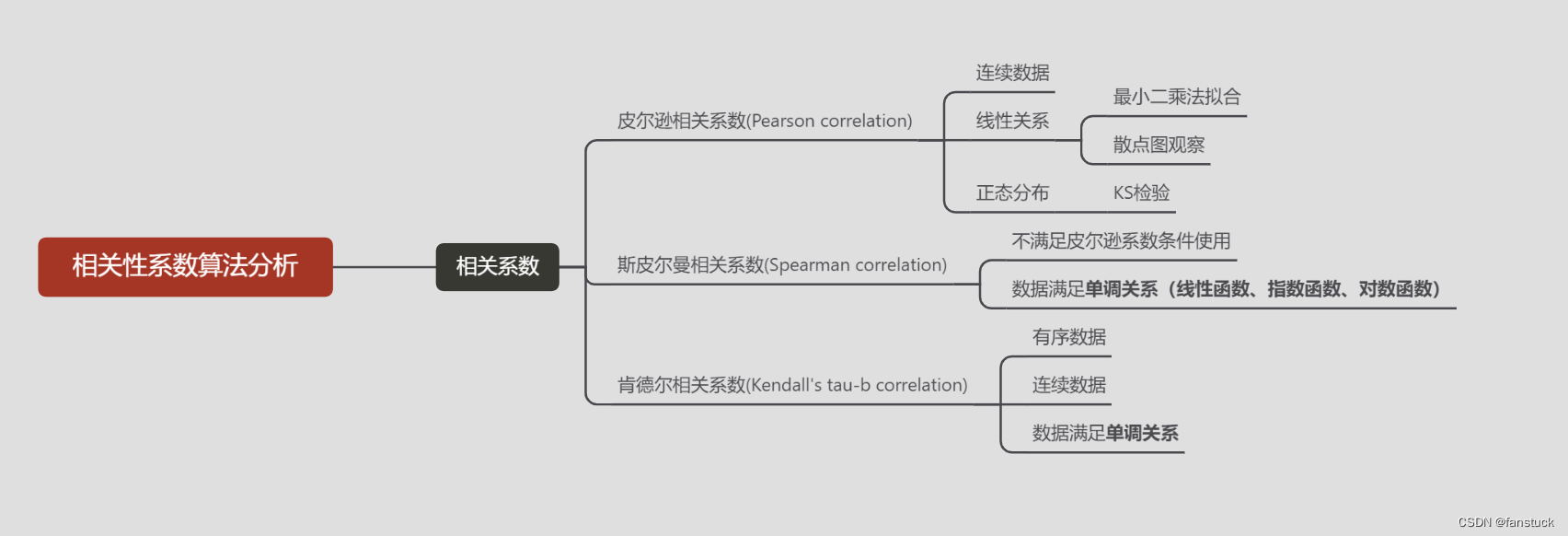
一、定义
经常用希腊字母ρ表示。 它是衡量两个变量的依赖性的非参数指标。 它利用单调方程评价两个统计变量的相关性。 如果数据中没有重复值, 并且当两个变量完全单调相关时,斯皮尔曼相关系数则为+1或−1。斯皮尔曼相关系数被定义成等级变量之间的皮尔逊相关系数。对于样本容量为n的样本,n个原始数据被转换成等级数据,相关系数ρ为:
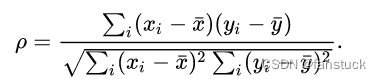
在实际应用或是具体题目中,变量间的连结是无关紧要的,将观测的两个变量的对应元素相减得到一个差值,则还可以将上述公式转化为:

其中,为
和
之间的等级差。
的计算方式为:

二、斯皮尔曼相关使用场景
斯皮尔曼相关系数的适用条件比皮尔逊相关系数要广,只需两个变量的观测值是成对的等级评定数据,或者是由连续变量观测数据转化得到的等级数据,不论两个变量的总体分布形态、样本容量的大小如何,都可以用斯皮尔曼等级相关系数来进行研究。只要数据满足单调关系(例如线性函数、指数函数、对数函数等)就能够使用。
斯皮尔曼相关系数对于异常值不太敏感,因为它基于排序位次进行计算,实际数值之间的差异大小对于计算结果没有直接影响。
三、斯皮尔曼相关系数(Spearman correlation)计算
和上期文章使用的函数一样,可以使用pandas的函数corr:
DataFrame.corr(method='pearson',
min_periods=1,
numeric_only=_NoDefault.no_default)参数说明:
method:{‘pearson’, ‘kendall’, ‘spearman’} or callable。Method of correlation。
-
pearson : standard correlation coefficient,皮尔逊系数
-
kendall : Kendall Tau correlation coefficient,肯德尔系数
-
spearman :Spearman rank correlation,斯皮尔曼系数
min_periods:int, optional。每对列所需的最小样本数。目前仅适用于Pearson和Spearman相关性。
numeric_only:bool, default True。仅包含浮点、整型或布尔型数据。
实现起来很简单:
rho =df_test.corr(method='spearman')
rho
热力图:
plt.rcParams['font.family'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
sns.heatmap(rho, annot=True)
plt.title('Heat Map', fontsize=18) 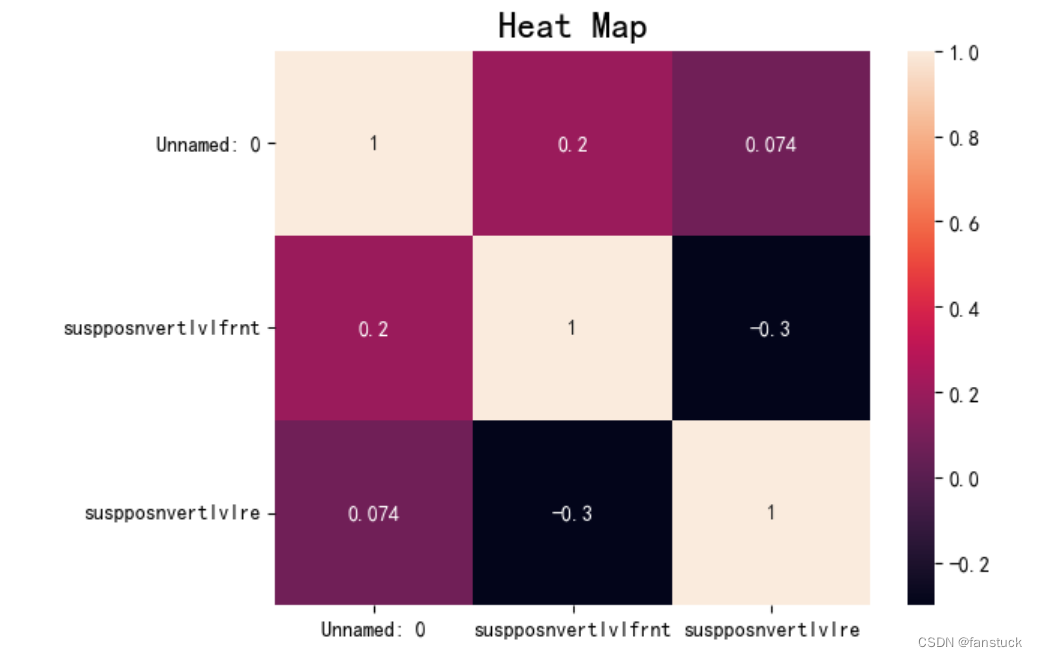
或者使用scipy的state函数,效果是一样的:
import numpy as np
from scipy import stats
stats.spearmanr(data1,data2)四、斯皮尔曼相关系数的假设检验
分为两种情况:小样本和大样本
小样本情况(n ≤ 30),直接查临界值表
H0:rs = 0; H1:rs ≠ 0
使用得出的斯皮尔曼相关系数 r 与对应的临界值进行比较。

大样本情况下,统计量
![]()
H0:rs = 0; H1:rs ≠ 0,计算检验值z*,并求出对应的p值与0.05比较即可。
点关注,防走丢,如有纰漏之处,请留言指教,非常感谢
以上就是本期全部内容。我是fanstuck ,有问题大家随时留言讨论 ,我们下期见
参阅
数学建模——相关系数(4)——斯皮尔曼相关系数(spearman)
转载自CSDN-专业IT技术社区
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/master_hunter/article/details/128609473

