

目录
大家好,我是哪吒。
专栏导读
图解Redis,谈谈Redis的持久化,RDB快照与AOF日志
一、Redis主从架构
单节点Redis的并发能力是有上限的,要进一步提高Redis的并发能力,就需要搭建主从集群,实现读写分离。
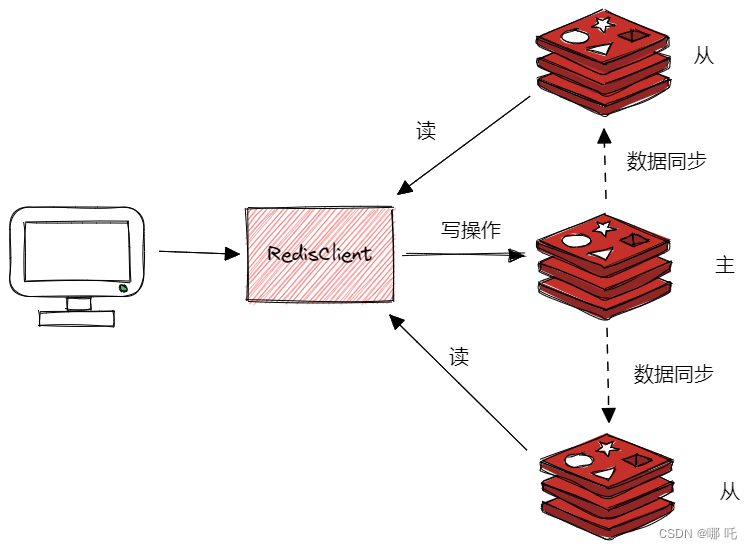
二、数据同步原理
master如何判断slave是不是第一次来同步数据?这里会用到两个很重要的概念:
1、Replication Id:简称replid,是数据集的标记,id一致则说明是同一数据集。每一个master都有唯一的replid,slave则会继承master节点的replid
2、offset:偏移量,随着记录在repl_baklog中的数据增多而逐渐增大。slave完成同步时也会记录当前同步的offset。如果slave的offset小于master的offset,说明slave数据落后于master,需要更新。
因此slave做数据同步,必须向master声明自己的replication id 和offset,master才可以判断到底需要同步哪些数据。
三、全量同步的流程
- slave节点请求增量同步;
- master节点判断replid,发现不一致,拒绝增量同步;
- master将完整内存数据生成RDB,发送RDB到slave;
- slave清空本地数据,加载master的RDB;
- master将RDB期间的命令记录在repl_baklog,并持续将log中的命令发送给slave;
- slave执行接收到的命令,保持与master之间的同步;
三、可以从以下几个方面来优化Redis主从就集群
- 在master中配置repl-diskless-sync yes启用无磁盘复制,避免全量同步时的磁盘IO;
- Redis单节点上的内存占用不要太大,减少RDB导致的过多磁盘IO;
- 适当提高repl_baklog的大小,发现slave宕机时尽快实现故障恢复,尽可能避免全量同步;
- 限制一个master上的slave节点数量,如果实在是太多slave,则可以采用主-从-从链式结构,减少master压力
四、全量同步和增量同步区别?
全量同步:master将完整内存数据生成RDB,发送RDB到slave。后续命令则记录在repl_baklog,逐个发送给slave;
增量同步:slave提交自己的offset到master,master获取repl_baklog中从offset之后的命令给slave;
五、什么时候执行全量同步?
slave节点第一次连接master节点时;
slave节点断开时间太久,repl_baklog中的offset已经被覆盖时;
六、什么时候执行增量同步?
slave节点断开又恢复,并且在repl_baklog中能找到offset时。
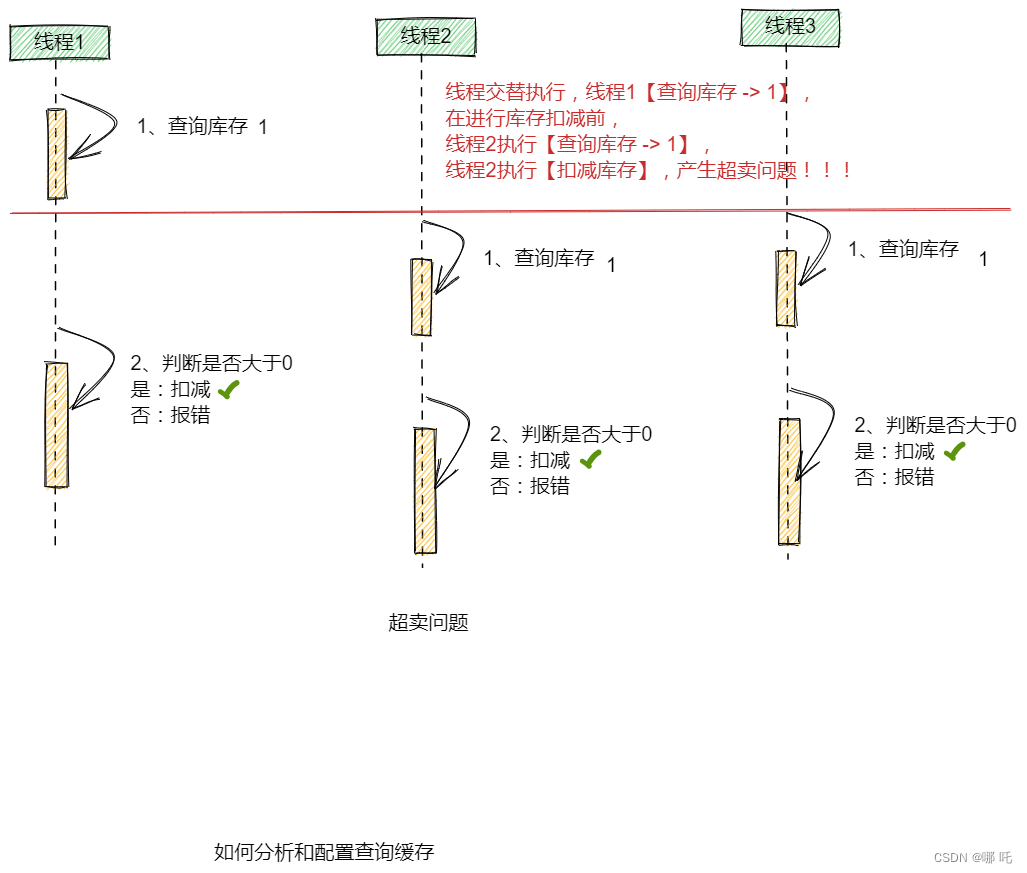
七、超卖问题
线程交替执行,线程1【查询库存 -> 1】,
在进行库存扣减前,
线程2执行【查询库存 -> 1】,
线程2执行【扣减库存】,产生超卖问题!!!

🏆本文收录于,Java基础教程系列。
目前已经700+订阅,CSDN最强Java专栏,包含全部Java基础知识点、Java8新特性、Java集合、Java多线程、Java代码实例,理论结合实战,实现Java的轻松学习。
🏆哪吒多年工作总结:Java学习路线总结,搬砖工逆袭Java架构师。
转载自CSDN-专业IT技术社区
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/guorui_java/article/details/128051349

