
spark shuffle
我们在前面的文章说过,所谓shuffle,就是spark RDD的一种宽依赖关系,父RDD的数据会发送给多个子RDD
spark中Map和Reduce概念
在Shuffle过程中.提供数据的称之为Map端(Shuffle Write)接收数据的称之为Reduce端(Shuffle Read),在Spark的两个阶段中,总是前一个阶段产生一批Map提供数据,下一阶段产生一批Reduce接收数据
spark中提供了两类shufflemanager,分别是hashshufflemanager和sortshufflemanager
HashShuffleManager
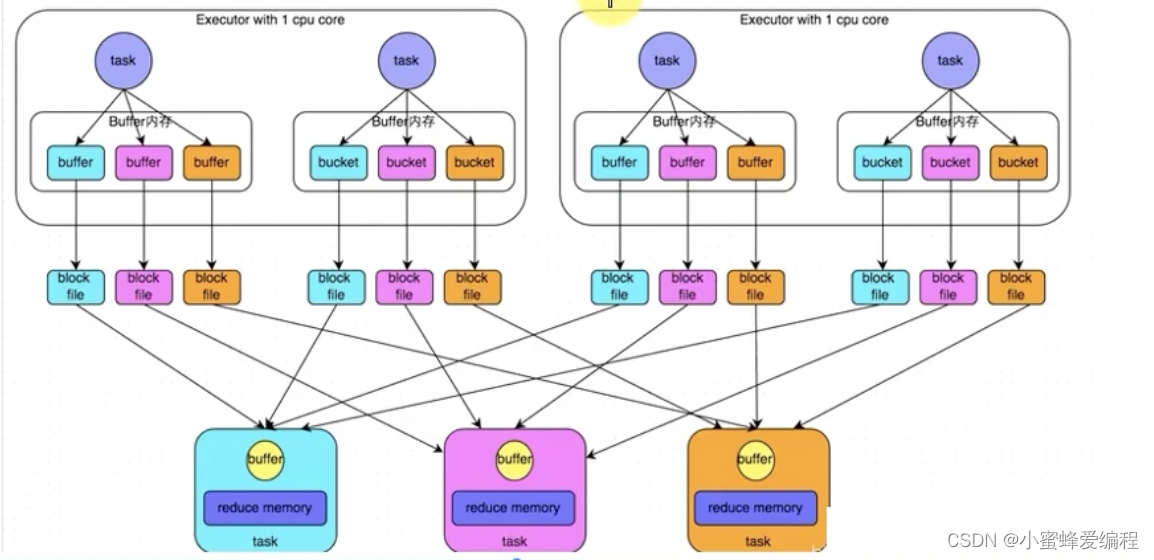
数据按hash进行分组,下图中相同分组的数据颜色一致,相同分组的数据在reduce时通过网络发送到同一个地方
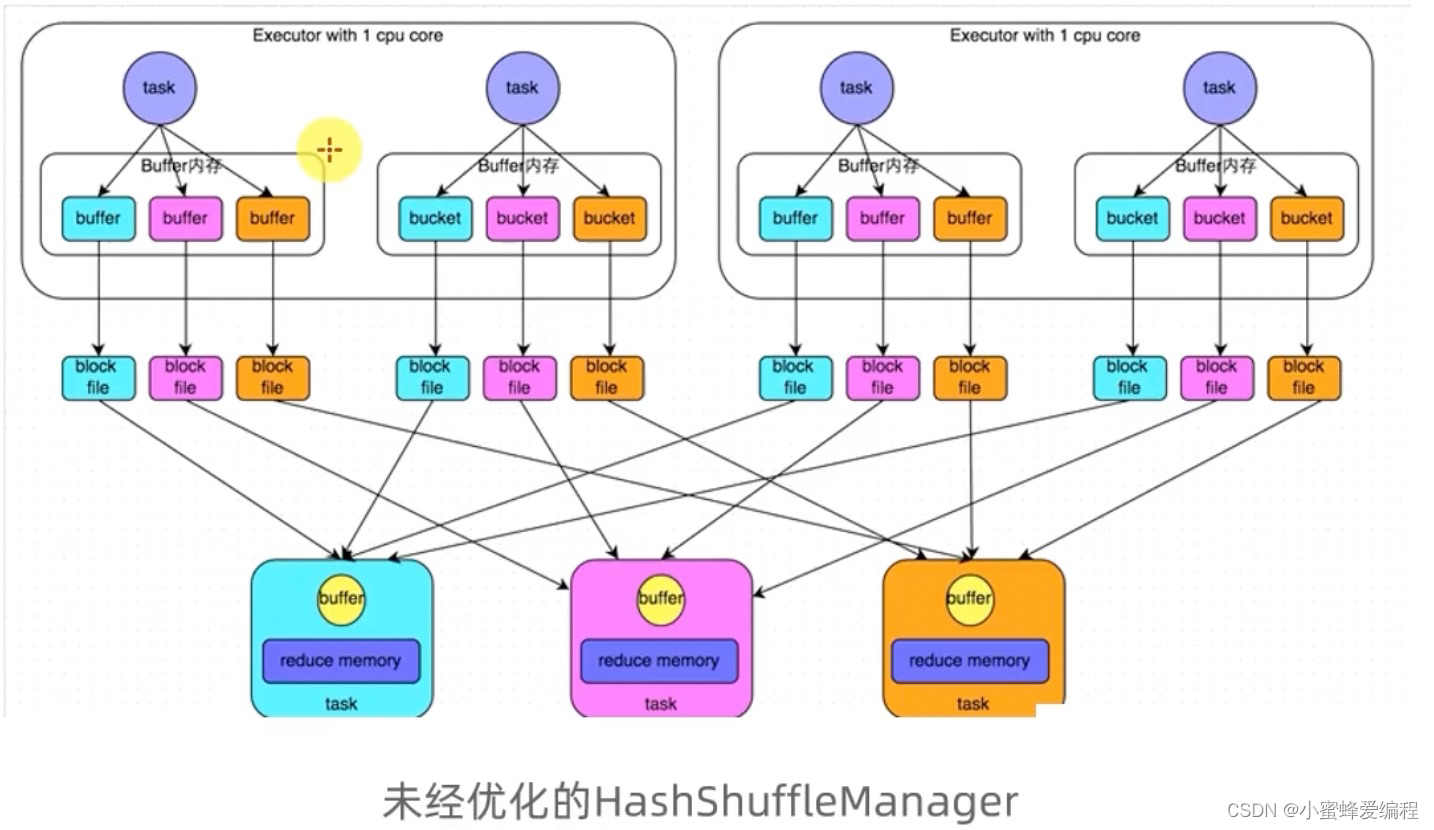
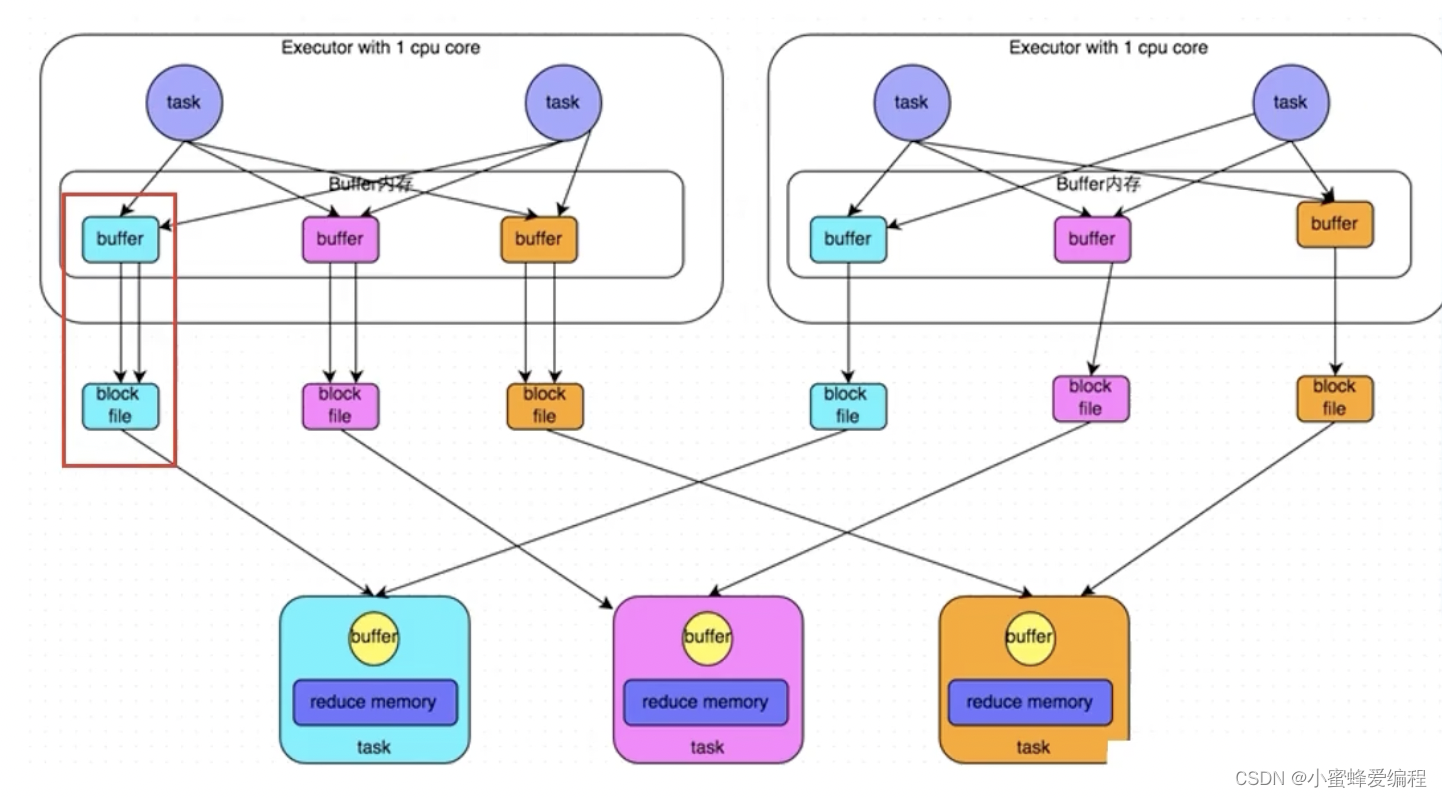
对同一个executor中的同一个分组但不同task产生的数据,task共享buffer缓冲区能减少网络io和写磁盘次数,提升性能
SortShuffleManager
SortShuffleManager的运行机制主要分为两种,一种普通运行机制,一种bypass运行机制
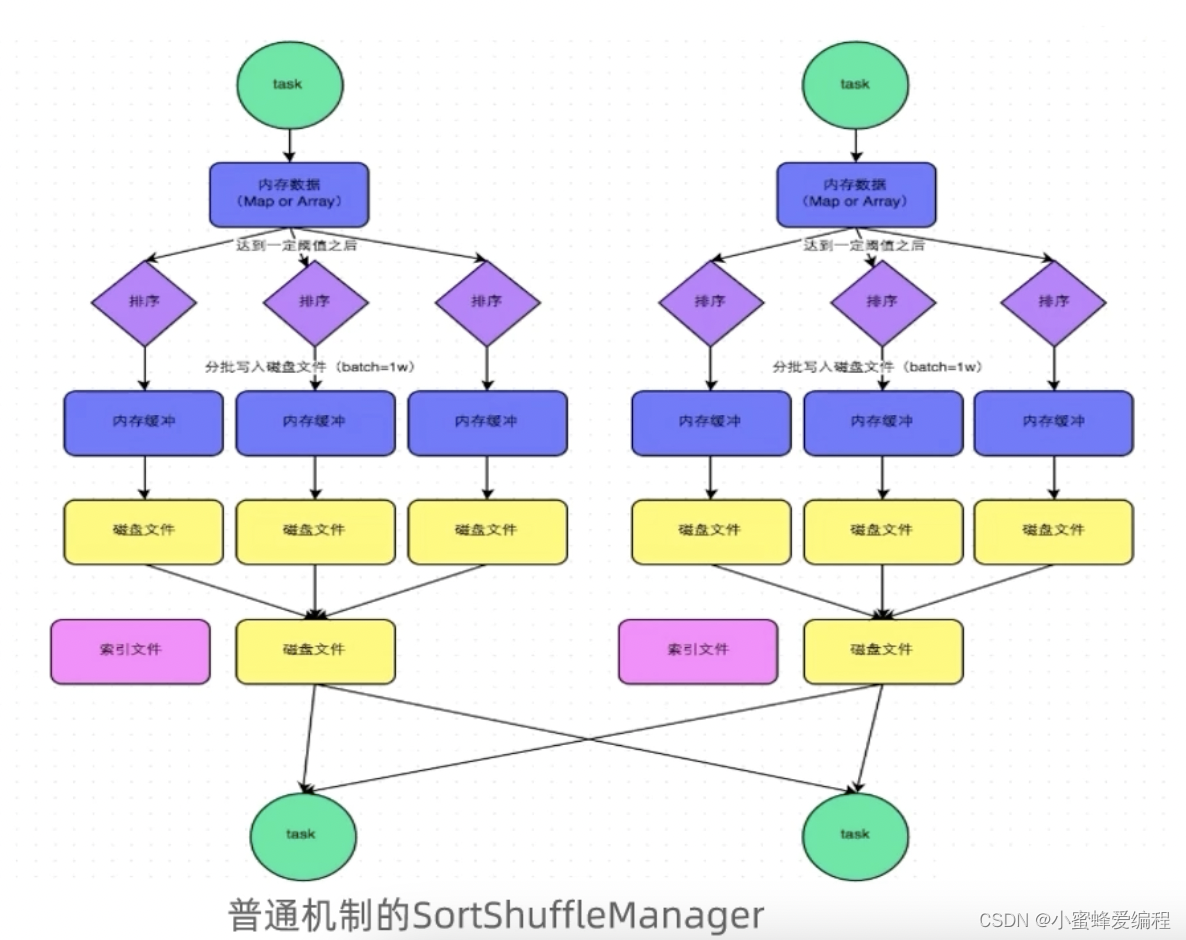
普通运行机制
内存数据写入磁盘后会汇聚到同一个文件中再发送给reduce节点,同时reduce节点任务通过索引文件确认该从整个文件中什么位置读取
bypass运行机制
bypassi运行机制的触发条件如下:
1)shuffle map task数量小于
spark.shuffle.sort.bypassMergeThres
hold=200参数的值。
2)不是聚合类的shuffle算子(比如
reduceByKey).
同普通机制基本类同,区别在于,写入磁盘临时文件的时候不会在内存中进行排序而是直接写,最终合并为一个task一个最终文件,所以和普通模式IDE区别在于:
第一,磁盘写机制不同;
第二,不会进行排序。
也就是说,启用该机制的最大好处在于shuffle write过程中,不需要进行数据的排序操作,也就节省掉了这部分的性能开销
SortShuffle与hashShuffle对比
1.SortShuffle对比HashShuffle可以减少很多的磁盘文件以节省网络IO的开销
2.SortShuffle主要是对磁盘文件进行合并来进行文件数量的减少,同时两类Shuffle都需要经过内存缓冲区溢写磁盘的场景.所以可以得知,尽管Spark是内存迭代计算框架,但是内存迭代主要在窄依赖中.在宽依赖(Shuffle)中磁盘交互还是一个无可避免的情况.
所以,我们要尽量减少Shuffle的出现,不要进行无意义的Shuffle计算.
转载自CSDN-专业IT技术社区
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/qq_42936727/article/details/137276315

