
目录
引言
在数字化转型的浪潮中,企业数据生态呈现多元化发展趋势。不同业务系统产生的数据往往存在指标定义差异、数据源异构、商品类目不统一等问题,这使得"同一业务指标多源异构"成为数据治理领域的典型挑战。本文将从技术架构设计、实施策略到代码实现,深入探讨如何应对多源数据整合难题。
第一章 问题分析与决策框架
1.1 典型业务场景
-
跨渠道销售统计:线上线下订单系统商品ID体系不同
-
用户画像整合:CRM系统与APP埋点的用户行为数据标准不一
-
库存管理:ERP实时库存与WMS批次库存的时间粒度差异
1.2 关键矛盾点
-
业务敏捷性 vs 数据一致性
-
历史系统兼容 vs 架构现代化
-
计算资源优化 vs 开发维护成本
1.3 三维决策模型
| 决策维度 | 融合策略 | 分离策略 |
|---|---|---|
| 业务目标 | 需要全局分析的战略指标 | 业务域特性鲜明的专业指标 |
| 技术成熟度 | 具备维度建模能力 | 存在不可调和的技术债务 |
| 组织架构 | 强中心化治理团队 | 领域自治型组织 |
第二章 数据融合技术实现
2.1 统一维度建模
2.1.1 商品维度表设计
-- 商品异构ID映射表
CREATE TABLE dim_item (
item_id STRING COMMENT '统一商品ID',
online_sku STRING COMMENT '电商SKU',
offline_gtin STRING COMMENT '线下商品条码',
category_id INT COMMENT '统一类目ID',
valid_start DATE COMMENT '映射生效日期',
valid_end DATE COMMENT '映射失效日期'
) PARTITIONED BY (dt STRING)
STORED AS ORC
TBLPROPERTIES ('orc.compress'='SNAPPY');-- 缓慢变化维处理(Type 2)
INSERT OVERWRITE TABLE dim_item PARTITION(dt='20231001')
SELECT
uuid() AS item_id,
sku,
gtin,
category_id,
'2023-01-01' AS valid_start,
'9999-12-31' AS valid_end
FROM (
SELECT
o.sku,
s.gtin,
coalesce(c.cat_id, -1) AS category_id
FROM ods_online_sku o
FULL OUTER JOIN ods_offline_gtin s
ON o.barcode = s.barcode
LEFT JOIN dim_category c
ON o.online_cat = c.source_cat
) tmp;2.1.2 时间维度处理
-- 多粒度时间桥接表
CREATE TABLE dim_time_bridge (
date_key STRING COMMENT '自然日期(yyyyMMdd)',
fis_date STRING COMMENT '财年日期(yyyyMMdd)',
week_type STRING COMMENT '周类型(NATURE/FISCAL)',
hour_bucket INT COMMENT '小时时段(0-23)'
);2.2 事实表融合方案
2.2.1 流批统一处理架构
# PySpark结构化流处理示例
online_stream = spark.readStream \
.format("kafka") \
.option("subscribe", "online_orders") \
.load()
offline_stream = spark.readStream \
.format("kafka") \
.option("subscribe", "offline_sales") \
.load()
unified_stream = online_stream.union(offline_stream) \
.join(dim_item, ["sku", "gtin"]) \
.withWatermark("event_time", "1 hour") \
.groupBy(window("event_time", "1 hour"), "item_id") \
.agg(sum("amount").alias("hourly_sales"))
unified_stream.writeStream \
.format("hudi") \
.option("path", "/hudi/unified_sales") \
.option("hoodie.datasource.write.operation", "upsert") \
.start()2.2.2 融合计算视图
CREATE MATERIALIZED VIEW unified_sales_mv
STORED AS PARQUET
AS
SELECT
t.fis_date,
i.category_id,
SUM(s.amount) AS total_sales,
COUNT(DISTINCT s.order_id) AS order_count
FROM fact_sales s
JOIN dim_time_bridge t
ON s.date_key = t.date_key
JOIN dim_item i
ON s.item_id = i.item_id
WHERE t.week_type = 'FISCAL'
GROUP BY t.fis_date, i.category_id;第三章 数据分离建设方案
3.1 业务域独立模型
3.1.1 电商域用户模型
-- 用户行为宽表
CREATE TABLE dwd_ec_user_wide (
user_id STRING,
last_login TIMESTAMP,
cart_items ARRAY<STRUCT<sku:STRING,add_time:TIMESTAMP>>,
purchase_history MAP<STRING,INT> -- <category_id, count>
) PARTITIONED BY (dt STRING)
STORED AS ORC;
-- JSON数据解析UDF
ADD JAR hdfs:///lib/json_udf.jar;
CREATE TEMPORARY FUNCTION parse_behavior AS 'com.udf.JsonBehaviorParser';
INSERT OVERWRITE TABLE dwd_ec_user_wide
SELECT
user_id,
MAX(event_time) AS last_login,
collect_list(named_struct('sku', sku, 'add_time', add_time)) AS cart_items,
str_to_map(concat_ws(',', collect_list(concat(category_id,':',cnt)))) AS purchase_history
FROM (
SELECT
user_id,
event_time,
parse_behavior(log_data).sku AS sku,
parse_behavior(log_data).add_time AS add_time,
category_id,
COUNT(*) OVER (PARTITION BY user_id, category_id) AS cnt
FROM ods_ec_logs
WHERE dt='20231001'
) tmp
GROUP BY user_id;3.1.2 金融域风控模型
-- 信贷特征宽表
CREATE TABLE dwd_fin_risk_wide (
user_id STRING,
credit_score INT,
overdue_records ARRAY<STRUCT<loan_id:STRING, overdue_days:INT>>,
recent_query_times INT
) PARTITIONED BY (dt STRING);
WITH query_stats AS (
SELECT
user_id,
SIZE(EXPLODE(queries)) AS query_count
FROM ods_fin_credit
LATERAL VIEW JSON_TUPLE(raw_data, 'query_records') q AS queries
)
INSERT OVERWRITE TABLE dwd_fin_risk_wide
SELECT
u.user_id,
CASE
WHEN score >= 750 THEN 1
WHEN score BETWEEN 650 AND 749 THEN 2
ELSE 3
END AS credit_score,
COLLECT_LIST(NAMED_STRUCT('loan_id', loan_id, 'overdue_days', days)) AS overdue_records,
COALESCE(q.query_count, 0) AS recent_query_times
FROM ods_fin_loan l
LEFT JOIN query_stats q ON l.user_id = q.user_id
GROUP BY u.user_id, q.query_count;3.2 跨域一致性保障
3.2.1 元数据注册中心
<!-- XML格式的指标定义 -->
<metric name="gmv" domain="sales">
<definition>SUM(valid_order_amount)</definition>
<owner>data-governance-team</owner>
<sources>
<source system="online" table="dwd_online_orders"/>
<source system="offline" table="dwd_offline_sales"/>
</sources>
<validation>
<rule type="volatility" threshold="0.15"/>
<rule type="freshness" interval="24h"/>
</validation>
</metric>3.2.2 自动化测试框架
# 使用PyTest的数据质量测试用例
def test_gmv_consistency():
online = spark.sql("SELECT SUM(amount) FROM dwd_online_orders WHERE dt='20231001'").collect()[0][0]
offline = spark.sql("SELECT SUM(amount) FROM dwd_offline_sales WHERE dt='20231001'").collect()[0][0]
delta = abs(online - offline) / ((online + offline)/2)
assert delta < 0.01, f"GMV差异超过1%: online={online}, offline={offline}"
def test_user_id_mapping():
ec_users = spark.sql("SELECT COUNT(DISTINCT user_id) FROM dwd_ec_user").collect()[0][0]
fin_users = spark.sql("SELECT COUNT(DISTINCT user_id) FROM dwd_fin_user").collect()[0][0]
overlap = spark.sql("""SELECT COUNT(1)
FROM dwd_ec_user ec
INNER JOIN dwd_fin_user fin
ON ec.user_id = fin.user_id""").collect()[0][0]
assert overlap / ec_users > 0.7, "用户映射覆盖率不足70%"第四章 演进路线与未来展望
4.1 三阶段演进路径
-
标准化阶段(0-6个月)
-
建立企业级数据字典
-
实现核心指标逻辑统一
-
部署基础数据质量监控
-
-
平台化阶段(6-18个月)
-
构建指标中台
-
实施领域驱动设计
-
完善数据血缘追踪
-
-
智能化阶段(18-36个月)
-
引入AI自动映射
-
实现动态阈值预警
-
构建自愈型数据管道
-
4.2 Data Mesh实践
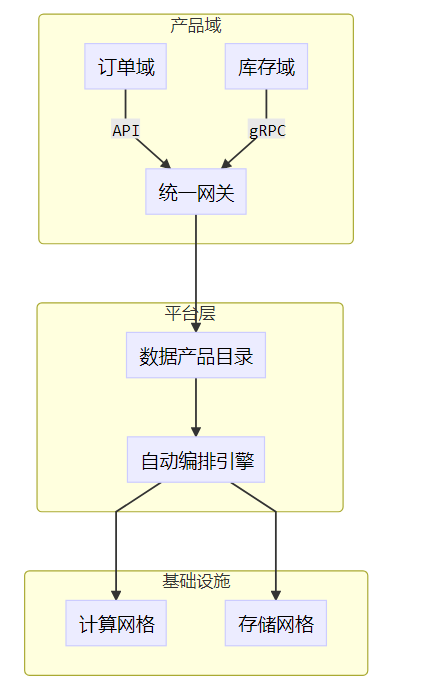
4.3 技术趋势展望
-
逻辑物理解耦:通过Lakehouse架构实现存储层统一
-
语义层标准化:采用dbt等工具实现逻辑模型统一
-
自适应数据治理:基于ML的异常检测和根因分析
结语
面对多源异构数据整合的复杂挑战,企业需采取"分而治之,合而为一"的策略。通过建立清晰的决策框架、设计灵活的技术方案、实施严格的质量控制,最终实现数据资产的全局可管、可控、可用。未来随着Data Mesh等新范式的普及,数据治理将进入更智能、更自治的新阶段。
往期精彩
晋升答辩提问:既然业务需求已经很明确了,你数仓建模的价值体现在哪?
🚀 「SQL进阶实战技巧」专栏重磅上线! 🚀
🌟 从零到高手,解锁SQL的无限可能! 🌟
这里有SQL的终极进阶秘籍:
✅ 正则表达式精准提取数据、✅ Window函数玩转复杂分析、✅ Bitmap优化提速百倍查询
✅ 缺失值补全、✅ 分钟级趋势预测、✅ 非线性回归建模、✅ 逻辑推理破题、✅ 波峰智能检测
🛠️ 给数据工程师的超强工具箱:
👉 解决「电梯超载难题」👉 预测「商品零售增长」
👉 跳过「NULL值天坑」👉 拆解「JSON密钥迷宫」
👉 巧算「连续签到金币」👉 嗨翻「赛马趣味逻辑」
🔥 突破常规,用SQL实现Python级分析!
从线性回归到指数平滑预测,从块熵计算到TEO能量检测——原来SQL才是隐藏的科学计算利器!
📈 无论你是想优化千万级数据性能,还是用一句SQL破解公务员考题,这里都有答案!
🦅 让SQL飞越数据的天空,带你用代码写出商业洞见!
👉 点击探索,开启你的数据分析新次元!
👉专栏链接如下:
SQL实战技术【Ultra版】_莫叫石榴姐的博客-CSDN博客
转载自CSDN-专业IT技术社区
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/godlovedaniel/article/details/147341189

