
本专栏文章持续更新,新增内容使用蓝色表示。
AWK 是一种强大的文本分析工具,以其三位创始人 Alfred Aho、Peter Weinberger 和 Brian Kernighan 的姓氏首字母命名。自 1977 年诞生以来,它已成为 Unix/Linux 系统中不可或缺的数据处理工具,特别擅长查询、统计和分析结构化文本数据。
简单来说,AWK 的工作模式可以总结为 “读取-分割-处理” 就是把文件逐行读入,以空格作为默认分割符将每行切片,切开的部分再进行各种分析处理。
食用指南
在开始 awk 练习之前,建议先快速浏览前面部分的内容,对 awk 的基本概念和功能有个整体印象。不需要死记硬背所有选项和语法,重点是了解 awk 能做什么。
练习部分建议:阅读完题目之后自行尝试解决,遇到问题可以回到前面的"选项"、"模式"、"操作"等章节查找对应的解决方法。解决完问题之后,可自行拓展其他的复杂场景。
语法:
awk [options] 'pattern{action}' {filenames}一、常用选项 (options)
| 选项 | 说明 |
|---|---|
| -F | 指定字段分隔符 |
| -v | 定义变量 |
| -f | 从文件读取awk脚本 |
内置变量
| 变量 | 说明 |
|---|---|
| $0 | 当前整行内容 |
| $1,$2,...$n | 第1,2,...n个字段 |
| NF | 当前行的字段数量 |
| NR | 当前处理的行号 |
| FNR | 当前文件中的行号 |
| FS | 设置输入字段分隔符(默认空格),等价于 -F 选项 |
| OFS | 输出字段分隔符(默认空格) |
| RS | 输入记录分隔符(默认换行) |
| ORS | 输出记录分隔符(默认换行) |
| FILENAME | awk 浏览的文件名 |
| $NF | number finally,表示最后一列的信息。 |
二、模式 (pattern) 类型
| 模式类型 | 语法 |
|---|---|
| 正则表达式 | /regex/ |
| 行号范围 | NR==n |
| 字段比较 | $n operator value |
| 特殊模式 | BEGIN、END、BEGINFILE、 ENDFILE |
| 条件组合 | && || ! |
特殊模式
BEGIN - 在处理任何输入行之前执行
# 初始化操作
awk 'BEGIN {
FS=":"; OFS="\t";
print "开始处理文件..."
}
{print $1, $3}' /etc/passwd
# 设置表头
awk 'BEGIN {print "姓名\t薪资"} {print $1, $4}' employees.txtEND - 在处理完所有输入行之后执行
# 统计总结
awk '{sum += $4} END {print "总薪资:", sum}' employees.txt
# 多文件统计
awk '{count++} END {print "总行数:", count}' *.txtBEGINFILE / ENDFILE - 处理每个文件开始和结束
# 为每个文件生成统计
awk '
BEGINFILE {print "处理文件:", FILENAME; count=0}
{count++}
ENDFILE {print "本文件行数:", count; total+=count}
END {print "所有文件总行数:", total}' file1.txt file2.txt三、常用操作 (action)
| 操作 | 语法 |
|---|---|
| 打印 | |
| 格式化打印 | printf |
| 变量赋值 | var=value |
| 流程控制 | if-else,for, while |
| 数组操作 | array[index] |
流程控制
if-else - 条件判断
# 简单条件
awk '{if($4 > 6000) print $1, "高薪"; else print $1, "普通"}' employees.txt
# 嵌套条件
awk '{
if($4 > 8000) grade="A"
else if($4 > 5000) grade="B"
else grade="C"
print $1, grade
}' employees.txtfor循环 - 固定次数循环
# 遍历字段
awk '{for(i=1;i<=NF;i++) print "字段" i ":", $i}' employees.txt
# 数字范围循环
awk 'BEGIN{for(i=1;i<=5;i++) print "数字:", i}'
# 倒序循环
awk '{for(i=NF;i>=1;i--) print $i}'while循环 - 条件循环
# 条件循环
awk '{i=1; while(i<=NF) {print $i; i++}}' employees.txt
# 模拟do-while
awk '{i=1; do {print $i; i++} while(i<=3)}' # 至少执行一次for...in循环 - 遍历数组
# 遍历关联数组
awk '{ips[$1]++} END{for(ip in ips) print ip, ips[ip]}' access.log
# 按特定顺序遍历
awk '{arr[$1]++} END{for(i in arr) print i, arr[i] | "sort -k2nr"}'break / continue - 循环控制
# break示例
awk '{
for(i=1;i<=NF;i++) {
if($i == "stop") break
print $i
}
}' data.txt
# continue示例
awk '{
for(i=1;i<=NF;i++) {
if($i == "skip") continue
print $i
}
}' data.txtnext - 跳过当前记录
# 跳过空行
awk '/^$/ {next} {print "非空行:", $0}' file.txt
# 跳过特定模式
awk '/^#/ {next} {print $0}' config.txt # 跳过注释行exit - 立即退出
# 找到特定记录后退出
awk '/error/ {print "发现错误:", $0; exit}' logfile.txt
# 限制处理行数
awk 'NR > 100 {print "超过100行,退出"; exit} {print $0}' largefile.txt补充:sort
sort 命令是 Linux/Unix 系统中的独立命令行工具。语法格式如下:
sort [选项] [文件]排序类型选项
| 选项 | 说明 |
|---|---|
| -n | 数字排序 |
| -r | 降序排序 |
| -f | 忽略大小写 |
| -R | 随机排序 |
字段控制选项
| 选项 | 说明 | 备注 |
|---|---|---|
| -k | 指定排序字段 | -k1 = 从第1字段到行尾 -k3,3 = 仅第3字段 sort命令按 -k 选项的顺序决定优先级 |
| -t | 指定字段分隔符 | |
| -u | 去重排序 |
四、awk 练习
4.1 数据准备
# 创建练习目录和文件
mkdir awk-practice && cd awk-practice4.2 基础输出
先进行一个简单的尝试:
echo 'apple banana tomato potato' | awk '{print$0}'
echo 'apple banana tomato potato' | awk '{print$3}'
echo 'apple banana tomato potato' | awk '{print$1"+"$3"+"$4}'
4.3 日志分析练习 (access.log)
# 创建日志文件
cat > access.log << 'EOF'
192.168.1.100 - - [10/Oct/2023:10:30:01] "GET /index.html HTTP/1.1" 200 1524
192.168.1.101 - - [10/Oct/2023:10:30:02] "POST /login HTTP/1.1" 302 0
192.168.1.102 - - [10/Oct/2023:10:30:03] "GET /products HTTP/1.1" 404 234
192.168.1.100 - - [10/Oct/2023:10:30:04] "GET /about.html HTTP/1.1" 200 2100
192.168.1.103 - - [10/Oct/2023:10:30:05] "GET /index.html HTTP/1.1" 200 1524
192.168.1.101 - - [10/Oct/2023:10:30:06] "GET /contact HTTP/1.1" 200 1800
192.168.1.104 - - [10/Oct/2023:10:30:07] "POST /register HTTP/1.1" 500 123
192.168.1.102 - - [10/Oct/2023:10:30:08] "GET /images/logo.png HTTP/1.1" 200 5432
EOF文件内容示例如下:
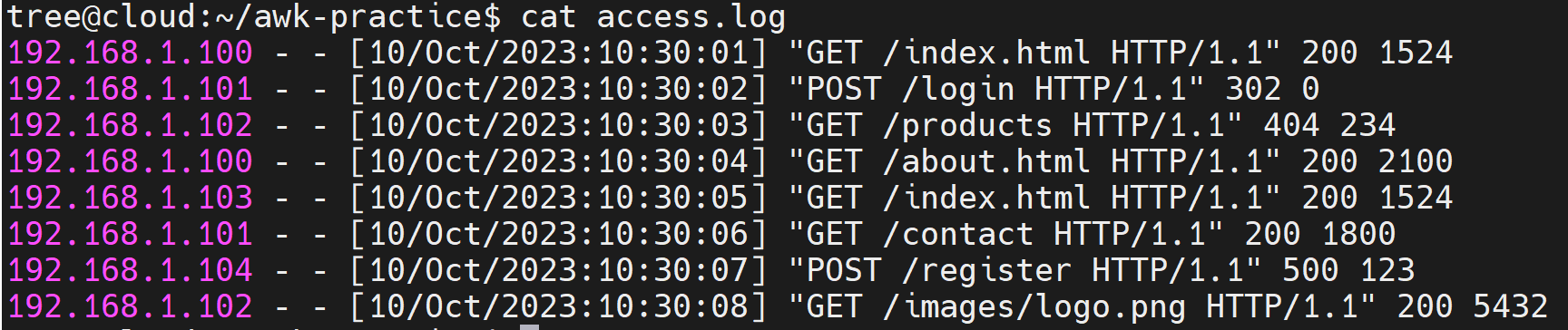
4.3.1 提取所有IP地址
awk '{print $1}' access.log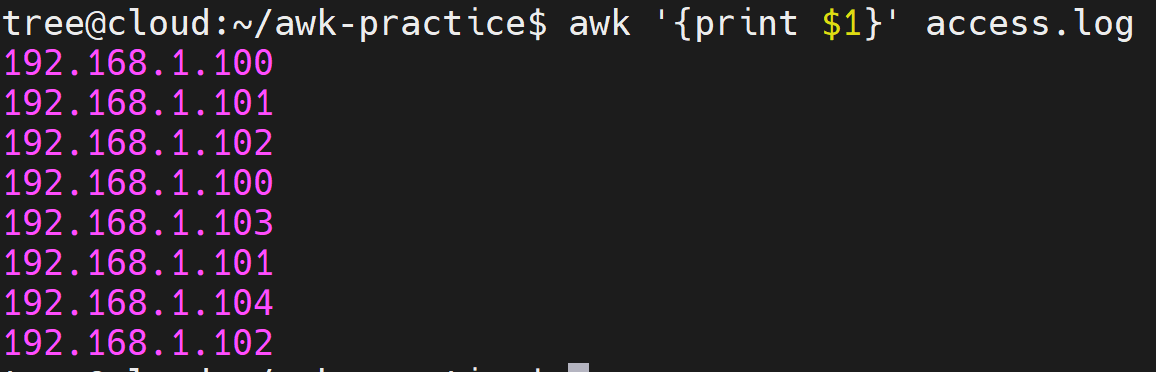
4.3.2 统计状态码出现次数
awk '{status[$8]++} END {for(code in status) print code,status[code]}' access.log
统计操作要在主块中完成,输出结果在END块中进行。
在这个基础上加上以出现次数为依据降序排序,如果次数相同,就以状态码为依据,进行降序排序。只需要在上一个命令的基础上加 sort 排序即可。
awk '{status[$8]++} END {for(code in status) print code, status[code]}' access.log | sort -k2,2nr -k1,1nr
4.3.3 统计所有的 GET 请求
awk '/GET/{print}' access.log
在这个结果基础之上筛选出状态码为 200 的 IP。
通过观察可以发现 IP 在第一列,状态码在第八列。
方法一:先过滤 GET 请求,再判断状态码
awk '/GET/ && $8==200 {print $1}' access.log
方法二:使用 if 语句
awk '/GET/ {if($8==200) print $1}' access.log
4.3.4 找出访问量最大的IP
awk '{nums[$1]++} END {for(ip in nums) print ip,nums[ip]}' access.log
练习其余部分见下一篇。
如有问题或建议,欢迎在评论区中留言~
转载自CSDN-专业IT技术社区
原文链接:https://blog.csdn.net/D2005_10_25/article/details/154287817

