
大家好,继之前我们总结了Numpy和Matplotlib两大基本库之后,今天来总结一下最后一个Python的基本库Pandas,关于Pandas的内容会讲解的更细一些,可能分为多篇内容,希望大家多支持。

目录
1、Pandas的两大核心:Series和DataFrame
一、什么是Pandas
Pandas是Python中用于数据分析和处理的开源库,基于NumPy构建,专注于结构化数据(如表格、时间序列)的快速处理。
简单来说,pandas是一个开源的Python库,它为Python提供了快速、灵活、易于使用的数据结构和数据分析工具。它的名字来源于“Panel Data”(面板数据),但我们可以亲切地把它想象成一个超级智能的电子表格。
核心功能
提供DataFrame和Series两种核心数据结构,支持数据清洗、缺失值处理、数据转换及统计分析,可高效处理CSV、Excel、SQL等多种格式数据。
应用场景
适用于金融数据分析、机器学习数据预处理等场景,尤其适合处理中小型数据集(如单机数据处理)。
二、安装Pandas
想要安装Pandas首先需要确认已经安装了Python,外网安装较慢也可以通过国内镜像安装,在之前的文章中我们讲解过,大家参考一下https://blog.csdn.net/m0_61746796/article/details/128575340
有需要的也可以在本地安装虚拟环境,可以参考下面文章
https://blog.csdn.net/m0_61746796/article/details/132691221?spm=1001.2014.3001.5502
然后在终端或者虚拟环境中执行,因为pandas的底层依赖于numpy所以最好一起安装
pip install pandas numpy -i https://pypi.tuna.tsinghua.edu.cn/simple安装好之后我们在应用中使用的时候需要进行引用,通常会起一个别名,例如:
import pandas as pd三、使用Pandas
1、Pandas的两大核心:Series和DataFrame
想要熟练使用pandas,就必须要了解它的核心概念组成,其中Series和DataFrame就是最根本的数据结构核心
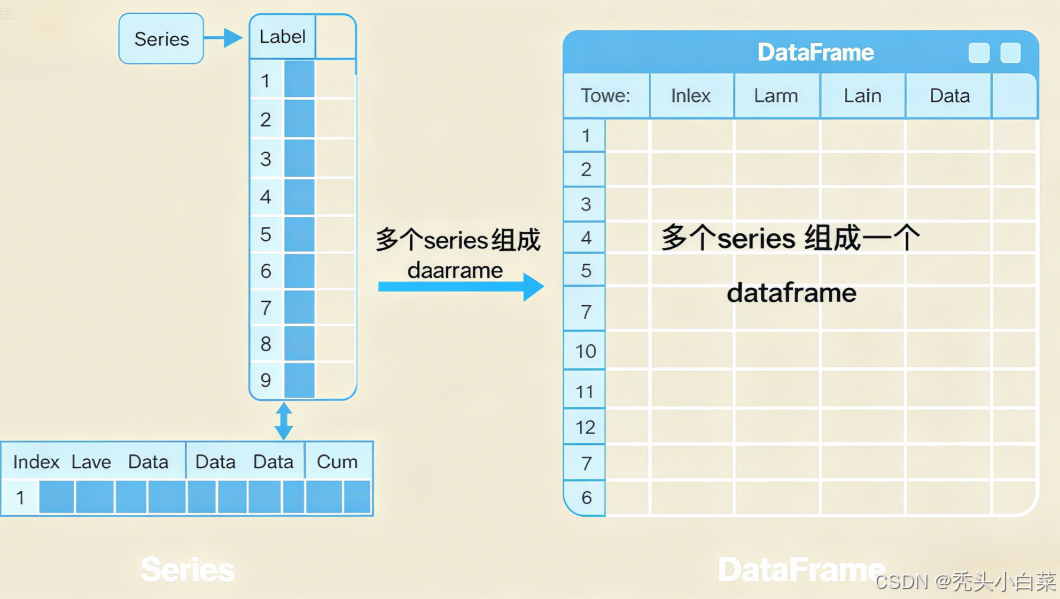
1.1、Series-带标签的一维数组
a.什么是Series?
Series是Pandas中最基本的数据结构,你可以把它理解为:
一个带标签的数组
像Python中的列表,但更强大
像Excel中的一列数据
像字典和numpy数组的结合体
b.创建Series的多种方式
创建series大致总结了三种方式:从列表中创建/(指定索引)、从字典创建、从numpy数组创建
import pandas as pd
import numpy as np
# 方式1:从列表创建(最常用)
data_list = [90, 85, 92, 88]
scores = pd.Series(data_list)
print("从列表创建:")
print(scores)
print()
# 方式2:从列表创建并指定索引
scores_named = pd.Series([90, 85, 92, 88],
index=['张三', '李四', '王五', '赵六'])
print("带自定义索引的Series:")
print(scores_named)
print()
# 方式3:从字典创建(键自动成为索引)
data_dict = {'张三': 90, '李四': 85, '王五': 92, '赵六': 88}
scores_dict = pd.Series(data_dict)
print("从字典创建:")
print(scores_dict)
print()
# 方式4:从numpy数组创建
arr = np.array([90, 85, 92, 88])
scores_np = pd.Series(arr, index=['A', 'B', 'C', 'D'])
print("从numpy数组创建:")
print(scores_np)c.Series的核心属性
# 创建一个示例Series
students = pd.Series([90, 85, 92, 88, 95],
index=['Alice', 'Bob', 'Charlie', 'David', 'Eve'])
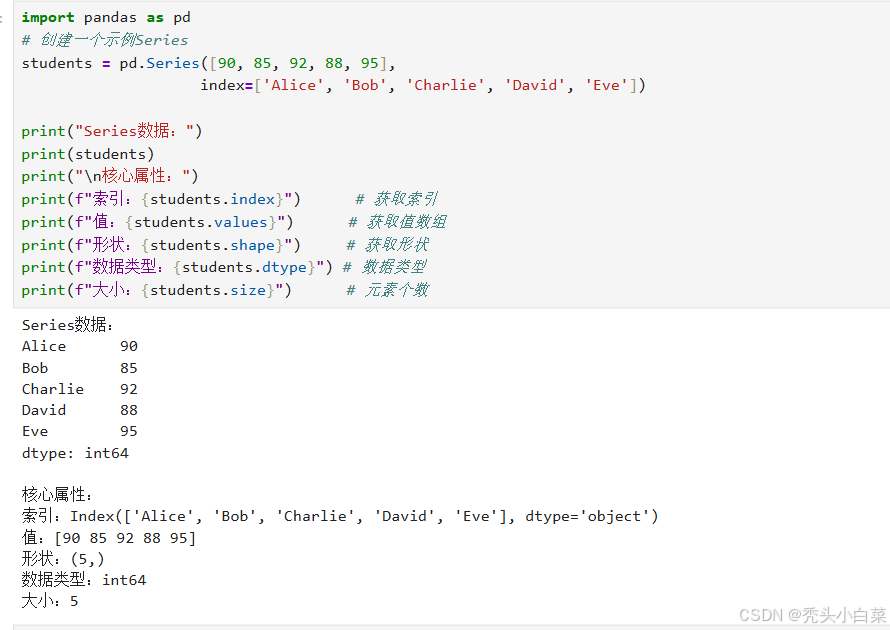
print("Series数据:")
print(students)
print("\n核心属性:")
print(f"索引:{students.index}") # 获取索引
print(f"值:{students.values}") # 获取值数组
print(f"形状:{students.shape}") # 获取形状
print(f"数据类型:{students.dtype}") # 数据类型
print(f"大小:{students.size}") # 元素个数运行结果如下:
d.Series的索引和切片
print("原始Series:")
print(students)
print()
# 按标签索引
print("Bob的成绩:", students['Bob'])
print("Charlie的成绩:", students.loc['Charlie'])
# 按位置索引
print("第一个元素:", students[0])
print("前三个元素:", students.iloc[:3])
# 布尔索引
print("90分以上的学生:")
print(students[students > 90])
# 多标签索引
print("多个学生成绩:")
print(students[['Alice', 'David', 'Eve']])运行结果如下:

e.Series的基本操作
# 数学运算
print("所有成绩加5分:")
print(students + 5)
print("\n成绩乘以1.1:")
print(students * 1.1)
# 统计操作
print(f"\n平均分:{students.mean()}")
print(f"最高分:{students.max()}")
print(f"最低分:{students.min()}")
print(f"标准差:{students.std()}")
# 向量化操作
bonus = pd.Series([5, 3, 2, 4, 1], index=students.index)
print("\n加上额外加分:")
print(students + bonus)运行结果如下:

1.2、DataFrame-二维表格数据结构
a.什么是DataFrame?
DataFrame是Pandas中最重要的数据结构,你可以把它理解为:
一个二维的、大小可变的、可以包含异构数据类型的表格
像Excel中的一个工作表
像SQL数据库中的一张表
由多个Series组成(每个列都是一个Series)
b.创建DataFrame的多种方式
创建series大致总结了三种方式:从字典创建(常用)、从列表中创建、从Series创建
# 方式1:从字典创建(最常用)
data = {
'姓名': ['张三', '李四', '王五', '赵六'],
'年龄': [20, 21, 19, 22],
'成绩': [90, 85, 92, 88],
'城市': ['北京', '上海', '广州', '深圳']
}
df = pd.DataFrame(data)
print("从字典创建的DataFrame:")
print(df)
print()
# 方式2:从列表的列表创建
data_list = [
['张三', 20, 90, '北京'],
['李四', 21, 85, '上海'],
['王五', 19, 92, '广州'],
['赵六', 22, 88, '深圳']
]
df_list = pd.DataFrame(data_list,
columns=['姓名', '年龄', '成绩', '城市'])
print("从列表创建的DataFrame:")
print(df_list)
print()
# 方式3:从Series创建
name_series = pd.Series(['张三', '李四', '王五', '赵六'])
age_series = pd.Series([20, 21, 19, 22])
score_series = pd.Series([90, 85, 92, 88])
df_series = pd.DataFrame({
'姓名': name_series,
'年龄': age_series,
'成绩': score_series
})
print("从Series创建的DataFrame:")
print(df_series)c.DataFrame的核心属性
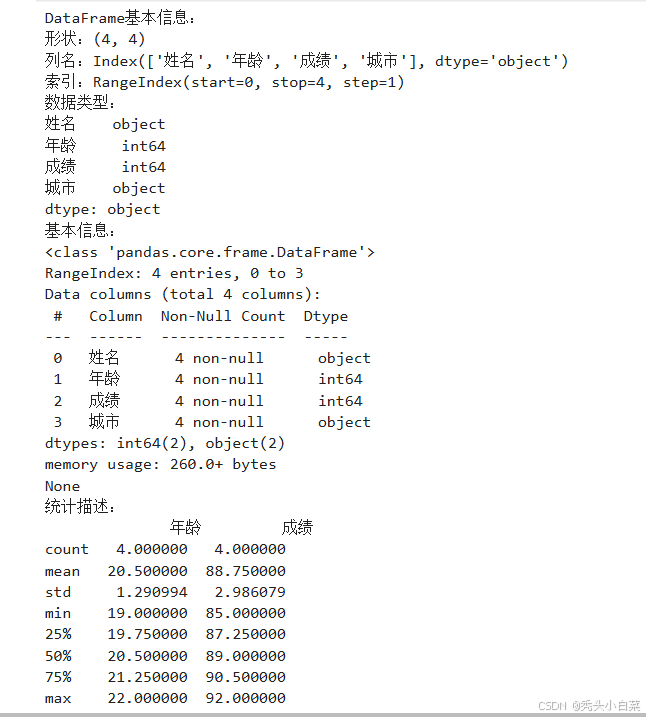
print("DataFrame基本信息:")
print(f"形状:{df.shape}") # (行数, 列数)
print(f"列名:{df.columns}") # 列索引
print(f"索引:{df.index}") # 行索引
print(f"数据类型:\n{df.dtypes}") # 每列的数据类型
print(f"基本信息:")
print(df.info())
print(f"统计描述:\n{df.describe()}") # 数值列的统计描述运行结果如下:
d.访问获取DataFrame中的数据
print("原始DataFrame:")
print(df)
print()
# 选择单列(返回Series)
print("选择'姓名'列:")
print(df['姓名'])
print(type(df['姓名'])) # 查看数据类型
# 选择多列(返回DataFrame)
print("\n选择'姓名'和'成绩'列:")
print(df[['姓名', '成绩']])
# 使用loc按标签选择
print("\n选择前两行:")
print(df.loc[0:1]) # 包含结束位置
print("\n选择特定行和列:")
print(df.loc[1:2, ['姓名', '城市']])
# 使用iloc按位置选择
print("\n按位置选择前两行:")
print(df.iloc[0:2]) # 不包含结束位置
print("\n按位置选择特定行列:")
print(df.iloc[1:3, 0:2]) # 第1-2行,第0-1列e.根据条件筛选数据
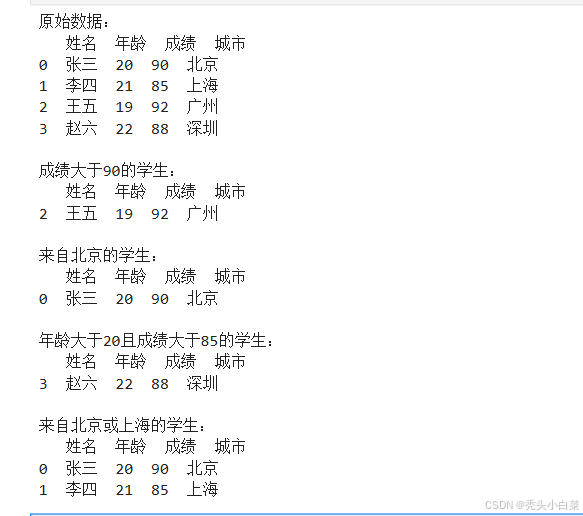
print("原始数据:")
print(df)
print()
# 单条件筛选
print("成绩大于90的学生:")
print(df[df['成绩'] > 90])
print("\n来自北京的学生:")
print(df[df['城市'] == '北京'])
# 多条件筛选
print("\n年龄大于20且成绩大于85的学生:")
print(df[(df['年龄'] > 20) & (df['成绩'] > 85)])
print("\n来自北京或上海的学生:")
print(df[(df['城市'] == '北京') | (df['城市'] == '上海')])运行结果如下:
f.修改DataFrame
如何修改原有框架中的数据,下面分别从两个方向进行讲解,分别是从列的角度和行的角度
# 以列的角度来进行增删改
# 添加新列
df['等级'] = ['A', 'B', 'A', 'B']
print("添加'等级'列后:")
print(df)
# 修改列
df['成绩调整'] = df['成绩'] + 5
print("\n添加'成绩调整'列后:")
print(df)
# 修改特定值
df.loc[0, '成绩'] = 95 # 修改张三的成绩
print("\n修改张三成绩后:")
print(df)
# 删除列
df_dropped = df.drop('成绩调整', axis=1)
print("\n删除'成绩调整'列后:")
print(df_dropped)# 以行的角度来进行增删改
# 1、增加新行
# 方法1:以两个dataframe的方式进行合并,使用字典创建新行
new_row = {'姓名': '王五', '年龄': 19, '成绩': 92, '城市': '广州'}
new_df = pd.DataFrame([new_row]) # 注意要放在列表中
df_new = pd.concat([df, new_df], ignore_index=True)
print("\n添加新行后:")
print(df_new)
# 添加多个新行
new_rows = pd.DataFrame([
['孙七', 23, 95, '杭州'],
['周八', 20, 87, '南京']
], columns=df.columns)
df = pd.concat([df, new_rows], ignore_index=True)
print("\n批量添加多行后:")
print(df)
# 方法2:使用loc在末尾添加(如果索引不存在会自动创建)
df.loc[2] = ['王五', 19, 92, '广州'] # 指定索引位置
df.loc[3] = ['赵六', 22, 88, '深圳']
print("\n使用loc添加行后:")
print(df)
# 2、删除行
# 方法1:删除单行(按索引)
df_dropped = df.drop(0) # 删除索引为0的行
print("删除第一行后:")
print(df_dropped)
# 方法2:删除多行
df_dropped_multi = df.drop([1, 3]) # 删除索引为1和3的行
print("\n删除第2和第4行后:")
print(df_dropped_multi)
# 3、修改行
print("修改前的数据:")
print(df)
# 方法1:修改单行
df.loc[0] = ['张三丰', 25, 98, '武当山'] # 完全替换第一行
print("\n修改第一行后:")
print(df)
# 方法2:只修改特定列的值
df.loc[1, ['年龄', '成绩']] = [22, 93] # 修改第二行的年龄和成绩
print("\n修改第二行部分值后:")
print(df)
# 方法3:修改单个值
df.loc[2, '城市'] = '成都'
print("\n修改第三行城市后:")
print(df)
# 方法4:按位置修改(第二行,第一列:姓名)
df.iloc[1, 0] = '李四四'
print("\n使用iloc修改后:")
print(df)
# 方法5:修改整行
df.iloc[2] = ['王五五', 24, 89, '重庆']
print("\n使用iloc修改整行后:")
print(df)除了上述的例子,我们还有多种方法来操作数据,例如iloc、at、loc等等,后面有时间会简单给大家讲解一下各自的区别,更新后会来附上链接,有兴趣的小伙伴可以收藏。
1.3、Series VS DataFrame 对比总结
| 特性 | Series | DataFrame |
|---|---|---|
| 维度 | 一维 | 二维 |
| 类比 | Excel中的一列 | 整个Excel表格 |
| 结构 | 索引 + 值数组 | 行索引 + 列索引 + 值矩阵 |
| 创建方式 | 列表、字典、numpy数组 | 字典、列表的列表、Series字典 |
| 选择数据 | s[label], s.loc[label], s.iloc[position] | df[column], df.loc[row, col], df.iloc[row_pos, col_pos] |
| 主要用途 | 单一变量的数据 | 多变量、表格型数据 |
1.4、实际应用示例
让我们用一个完整的例子来展示Series和DataFrame的配合使用:
# 创建学生数据
students_df = pd.DataFrame({
'数学': [85, 92, 78, 90],
'英语': [88, 79, 95, 87],
'物理': [92, 85, 88, 94]
}, index=['张三', '李四', '王五', '赵六'])
print("学生成绩表:")
print(students_df)
print()
# 从DataFrame中提取Series
math_scores = students_df['数学']
print("数学成绩Series:")
print(math_scores)
print(f"类型:{type(math_scores)}")
# 对Series进行操作
print(f"\n数学平均分:{math_scores.mean()}")
print(f"数学最高分:{math_scores.max()}")
# 将Series操作结果添加回DataFrame
students_df['总分'] = students_df['数学'] + students_df['英语'] + students_df['物理']
students_df['平均分'] = students_df['总分'] / 3
print("\n添加总分和平均分后:")
print(students_df)总结:
Series 是构建块,是单一维度的数据容器
DataFrame 是工作马,是实际数据分析中最常用的结构
理解它们之间的关系(DataFrame由多个Series组成)是掌握Pandas的关键
熟练使用索引和切片操作是进行有效数据分析的基础
建议你亲自运行这些代码,并尝试创建自己的Series和DataFrame,这样才能真正理解它们的工作原理!

今天就初步总结到这里,我会在后续更为深入的讲解分析,对比Pandas中其他的使用方法,希望大家多多支持,点赞关注收藏评论(转发请附上链接),我将更加有动力更新文章!!!
转载自CSDN-专业IT技术社区
原文链接:https://blog.csdn.net/m0_61746796/article/details/153201960

