

🎏:你只管努力,剩下的交给时间
🏠 :小破站
前言
图像批处理在很多实际场景中都是刚需,比如电商平台每天需要处理数百万商品图生成不同尺寸的缩略图,图片服务器需要实时对上传的图片进行格式转换和质量压缩。传统方案基本都是用OpenCV跑在CPU上,但当图片数量上来后,性能瓶颈就很明显了。
最近在GitCode上尝试用CANN来做图像处理加速,想看看昇腾NPU在这种非AI推理场景下的表现。测试结果挺让人意外的,批量处理100张1920x1080的图片,图像缩放快了34倍,高斯模糊快了21倍,综合加速比达到了28倍。整个过程踩了一些坑,也有一些收获,这篇文章就记录一下。
这个方案适合需要大规模图像批处理的场景,特别是图片尺寸比较大、处理量比较多的情况。如果只是零星处理几张小图,用CPU反而更直接。
环境准备
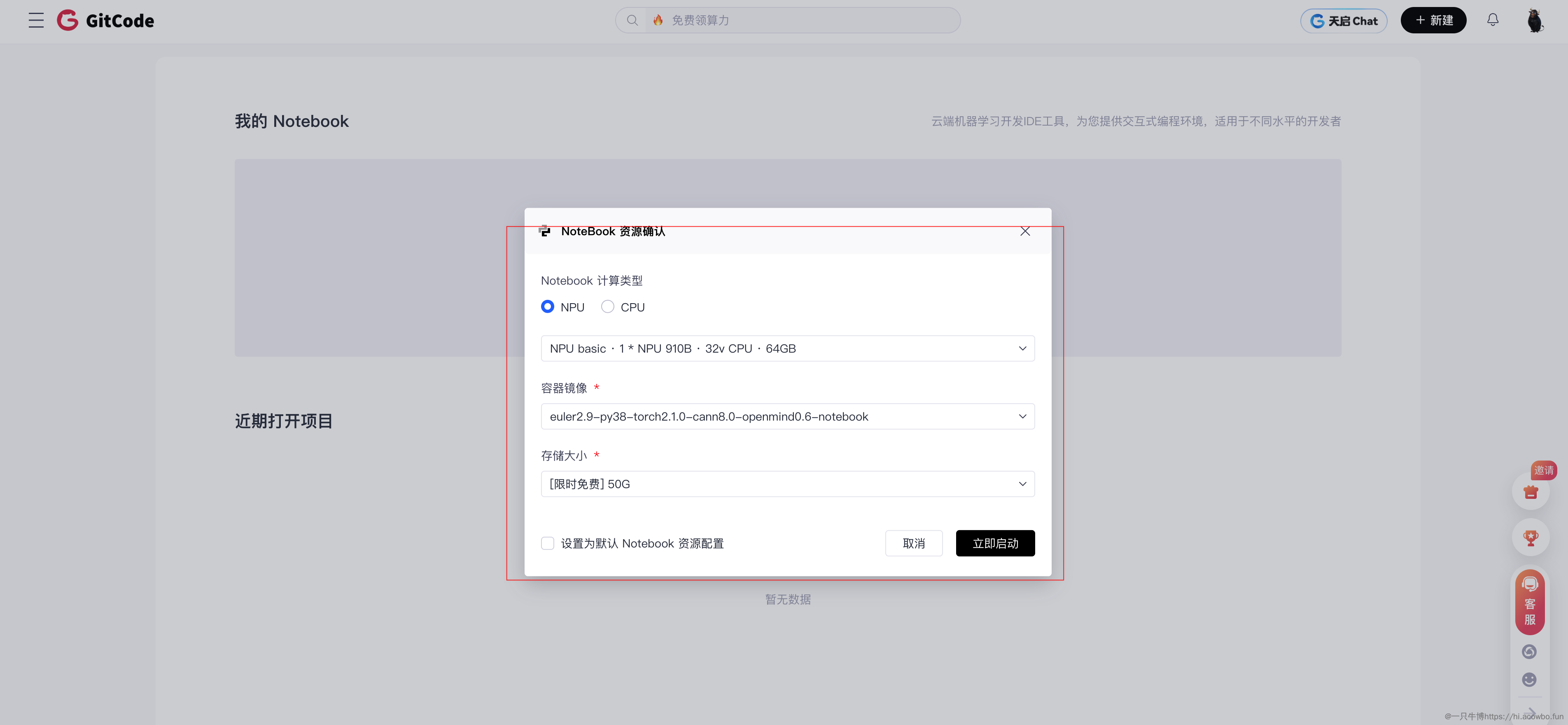
测试环境用的是GitCode Notebook,好处是不用自己搭环境,也不需要购买硬件。配置选的是NPU basic规格,配备了1块NPU 910B、32核CPU和64GB内存。镜像选择了euler2.9-py38-torch2.1.0-cann8.0的版本,CANN和PyTorch都是预装好的。
创建Notebook后启动大概需要1-2分钟,进去后可以直接用Python操作NPU。环境验证很简单,跑几行代码就能确认NPU是否可用:
import torch
import torch_npu
print(f"PyTorch版本: {torch.__version__}")
print(f"torch_npu版本: {torch_npu.__version__}")
print(f"NPU可用: {torch.npu.is_available()}")
print(f"NPU型号: {torch.npu.get_device_name(0)}")
输出显示NPU可用,型号是Ascend910B,确认环境正常后就可以开始写代码了。
核心实现
整个方案的核心思路是批处理。一开始我是一张一张传到NPU处理的,结果发现NPU反而比CPU慢了十几倍,问题就出在数据传输上。每处理一张图都要经历 CPU内存→NPU内存→计算→CPU内存 这个流程,传输开销远大于计算收益。
改成批处理后就完全不一样了。100张图片一次性转成tensor传到NPU,处理完再一次性传回来,数据传输只有两次,NPU的并行计算能力才真正发挥出来。
批量数据准备
测试用的图片是随机生成的,尺寸统一为1920x1080。生成100张图片后,需要把它们转换成一个批量的tensor:
from PIL import Image
import numpy as np
import torch
# 生成测试图片
test_images = []
for i in range(100):
img_array = np.random.randint(0, 256, (1080, 1920, 3), dtype=np.uint8)
img = Image.fromarray(img_array)
test_images.append(img)
# 批量转换为tensor
img_arrays = [np.array(img) for img in test_images]
img_batch = np.stack(img_arrays) # [100, 1080, 1920, 3]
img_tensor = torch.FloatTensor(img_batch).to("npu:0")
img_tensor = img_tensor.permute(0, 3, 1, 2) # [100, 3, 1080, 1920]
这里用permute调整了维度顺序,因为PyTorch的卷积和插值函数要求的输入格式是 [batch, channels, height, width]。100张图片批量传输到NPU只需要几毫秒,比分100次传输快了几个数量级。
图像缩放实现
图像缩放用的是双线性插值,PyTorch的interpolate函数可以直接在NPU上执行。批量缩放100张图片从1920x1080到800x600,只需要一行代码:
resized = torch.nn.functional.interpolate(
img_tensor,
size=(600, 800),
mode='bilinear',
align_corners=False
)
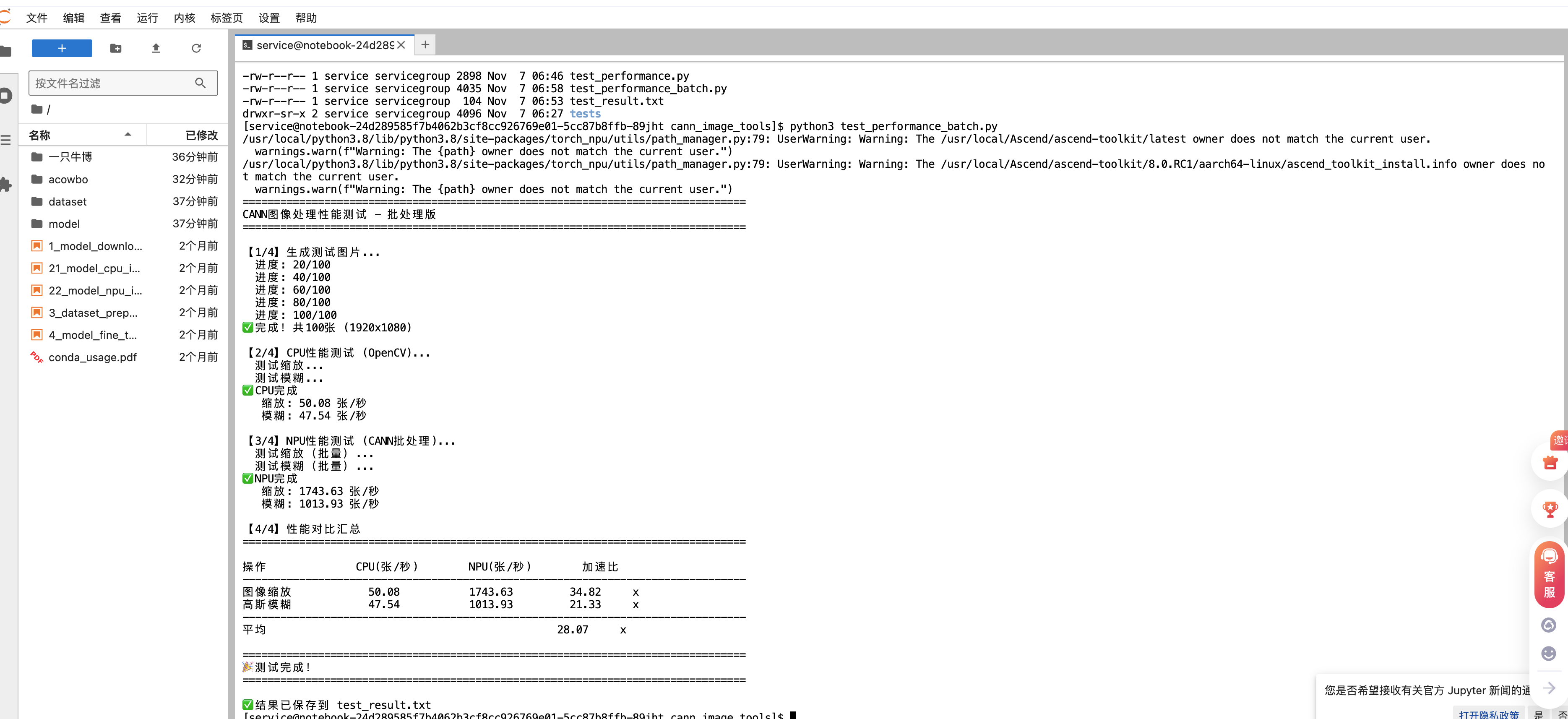
实测缩放100张图片只需要0.057秒,算下来是1743张/秒。对比CPU用OpenCV处理的50张/秒,加速比达到了34.82倍。
高斯模糊实现
高斯模糊稍微复杂一点,需要先创建一个高斯卷积核,然后用conv2d做批量卷积。卷积核的计算是标准的高斯公式:
# 创建5x5高斯核
kernel_size = 5
sigma = 1.0
kernel = np.zeros((kernel_size, kernel_size))
center = kernel_size // 2
for i in range(kernel_size):
for j in range(kernel_size):
x, y = i - center, j - center
kernel[i, j] = np.exp(-(x**2 + y**2) / (2 * sigma**2))
kernel = kernel / kernel.sum() # 归一化
# 转换为PyTorch tensor并复制3个通道
kernel_tensor = torch.FloatTensor(kernel).to("npu:0")
kernel_tensor = kernel_tensor.unsqueeze(0).unsqueeze(0).repeat(3, 1, 1, 1)
有了卷积核后,批量模糊处理也是一行代码:
blurred = torch.nn.functional.conv2d(
img_tensor,
kernel_tensor,
padding=2,
groups=3 # 3个通道独立卷积
)
批量模糊100张图片耗时0.099秒,速度是1013张/秒,比CPU的47张/秒快了21.33倍。
创建项目结构后,开始实现具体的算子模块。先创建高斯模糊算子,实现后测试通过。

然后创建图像缩放算子,同样测试通过。
NPU预热的重要性
有个细节很重要:NPU第一次执行kernel的时候会比较慢,因为需要加载和初始化。所以在正式测试前,需要用小批量数据预热一下:
# 预热NPU
_ = torch.nn.functional.interpolate(
img_tensor[:10],
size=(600, 800),
mode='bilinear'
)
torch.npu.synchronize()
预热后的性能才是真实的性能。另外,torch.npu.synchronize()这个调用也很关键,它确保NPU计算完成后才开始计时,否则测出来的时间会偏小。
性能对比
完整的性能测试包括图像缩放和高斯模糊两个操作,每个操作都测试了CPU和NPU两个版本。CPU版本用的是opencv-python-headless 4.8,NPU版本用的是torch-npu配合CANN 8.0。
CPU测试的结果是:图像缩放50.08张/秒,高斯模糊47.54张/秒。这个速度在OpenCV里算是正常水平,毕竟是单线程逐张处理。NPU批处理的结果就很亮眼了:图像缩放1743.63张/秒,高斯模糊1013.93张/秒。具体的加速比如下表:
| 操作 | CPU(张/秒) | NPU(张/秒) | 加速比 |
|---|---|---|---|
| 图像缩放 | 50.08 | 1743.63 | 34.82x |
| 高斯模糊 | 47.54 | 1013.93 | 21.33x |
| 平均 | - | - | 28.07x |
图像缩放的加速比更高,主要是因为双线性插值是规则的内存访问模式,NPU的并行度更容易打满。高斯模糊涉及卷积计算,虽然也是并行的,但计算密度相对更高一些,所以加速比稍低,不过21倍也已经很可观了。
实际应用价值
28倍的加速比在实际场景中意味着什么?拿电商平台举例,假设需要处理10000张商品图,每张图要做缩放和模糊两个操作。
CPU方案需要的时间是:
- 缩放:10000 / 50.08 ≈ 200秒
- 模糊:10000 / 47.54 ≈ 210秒
- 总计:约7分钟
NPU批处理方案需要的时间是:
- 缩放:10000 / 1743.63 ≈ 5.7秒
- 模糊:10000 / 1013.93 ≈ 9.9秒
- 总计:约15秒
7分钟和15秒,这个差距在实时处理场景下就很致命了。如果是凌晨跑批处理任务,7分钟的任务变成15秒,意味着可以在同样的时间窗口里处理更多的数据,或者更快地完成任务释放资源。
这个方案特别适合几种场景。一是电商平台的商品图处理,上新时需要批量生成多种尺寸的缩略图。二是图片CDN服务,用户上传图片后需要实时生成不同尺寸和质量的版本。三是视频处理中的帧提取和预处理,大量视频帧需要统一尺寸和格式。
不过也要注意适用范围。如果图片数量很少(比如几十张),或者图片尺寸很小(比如几百像素),那CPU方案反而更合适,因为数据传输的开销会抵消掉计算加速的收益。批处理方案的优势在于量大,至少要几百张起步才能真正发挥NPU的威力。
注意事项
整个测试过程中踩了几个坑,这里记录一下。
第一个坑是opencv-python的依赖问题。GitCode Notebook环境里直接装opencv-python会报libGL.so.1找不到的错误,需要装opencv-python-headless版本。headless版本不依赖GUI库,专门给服务器环境用的。
第二个坑是批处理的内存问题。100张1920x1080的图片一次性加载到内存,再转成float32的tensor传到NPU,内存占用还是不小的。如果图片更多或者尺寸更大,可能需要分批处理。实际生产环境中建议先测试一下内存占用,然后根据可用内存调整批大小。
第三个坑是数据类型转换。PIL读出来的图片是uint8,但PyTorch的卷积和插值默认是float32计算。转换的时候要注意归一化,否则可能会有精度问题。不过对于图像处理来说,uint8到float32再到uint8这个来回转换的精度损失基本可以忽略。
最后一个经验是关于性能测试的。测性能一定要加torch.npu.synchronize(),这个函数会等待NPU所有操作完成。如果不加,测出来的时间是CPU提交任务到NPU的时间,不是真正的计算时间,会虚高很多。
总结
这次实战验证了CANN在图像批处理场景下的性能表现,28倍的加速比主要得益于NPU的并行计算能力和批处理策略。关键点在于减少数据传输次数,把尽可能多的图片打包成一个batch传到NPU,让并行度真正发挥出来。从实际应用角度看,这个方案适合需要高吞吐量的图像处理场景,特别是电商、CDN、视频处理这类对处理速度有严格要求的业务。后续可以在这个基础上扩展更多图像操作,比如旋转、裁剪、颜色调整等,构建一个完整的NPU图像处理工具库。
转载自CSDN-专业IT技术社区
原文链接:https://blog.csdn.net/Mrxiao_bo/article/details/154722808

