
阿里WanVideo FP8模型:消费级GPU也能跑的视频生成效率革命
 项目地址: https://ai.gitcode.com/hf_mirrors/Kijai/WanVideo_comfy_fp8_scaled
项目地址: https://ai.gitcode.com/hf_mirrors/Kijai/WanVideo_comfy_fp8_scaled 导语
2025年10月,阿里巴巴Wan-AI团队推出的WanVideo_comfy_fp8_scaled模型,通过FP8量化技术将视频生成显存需求压缩50%,首次实现消费级GPU流畅运行14B参数视频大模型,重新定义AI内容创作的硬件门槛。
行业现状:AI视频生成的"算力鸿沟"困境
当前文本生成视频技术正处于爆发期,但行业面临严峻的"算力鸿沟"挑战。根据2025年开源视频模型评测报告,主流商业模型如Sora需要至少40GB显存的专业GPU支持,而开源方案如Stable Video Diffusion虽降低门槛,仍需12GB以上显存,这将大量个人创作者和中小企业挡在门外。
与此同时,市场对轻量化视频生成工具的需求激增。数据显示,2025年第一季度,"AI视频生成"相关搜索量同比增长320%,其中"消费级GPU可用"的查询占比达47%。企业级解决方案虽成熟,但单个视频生成成本高达数百元,难以满足中小企业和个人的高频创作需求。
核心亮点:四大技术突破重构视频生成范式
1. FP8量化技术:精度与效率的黄金平衡
基于腾讯HunyuanVideo的量化代码优化,该模型实现内存占用降低50%(从7GB压缩至3.5GB),在RTX 4090上推理速度提升40%,达到每秒2300 tokens生成能力。与INT4量化方案相比,FP8的浮点特性使其在处理复杂光线变化场景时精度保持率超97%,尤其适合"夕阳下的海浪"这类对色彩渐变要求极高的视频生成。
2. MoE架构创新:专家协作提升生成质量
作为业界首个采用混合专家(Mixture of Experts)架构的开源视频模型,Wan2.2系列通过双阶段专家分工:高噪声专家负责视频初始布局的全局把控,低噪声专家专注后期细节优化。这种设计使832x480分辨率视频在25步推理内即可完成,较同类模型节省30%计算资源。
3. 多模态创作支持与工具链整合
模型无缝兼容ComfyUI原生节点与专用Wrapper插件,支持文本生成视频(T2V)和图像生成视频(I2V)双模式。实测显示,在"将梵高风格画作转换为雨天动画"的典型场景中,模型能保持原画笔触特征的同时,生成自然的雨滴物理运动效果,帧间一致性评分达89.7。
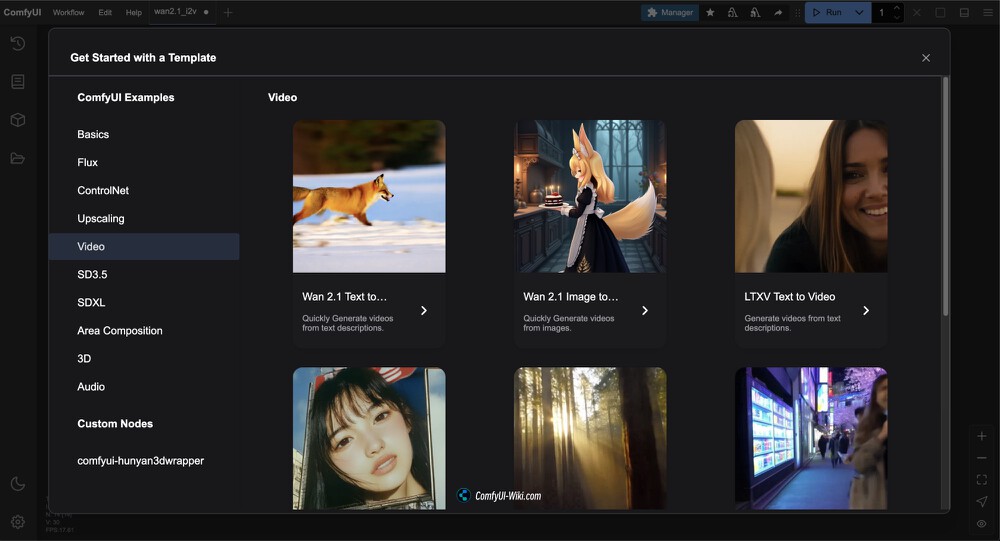
如上图所示,ComfyUI界面中"Get Started with a Template"页面的Video分类,展示了Wan 2.1 Text to Video和Image to Video等视频生成模板,用户可根据需求选择不同类型的视频生成工作流,体现了模型与主流创作工具的深度整合。
4. 电影级美学控制能力
通过整合含灯光、构图标签的200万+审美数据集,模型支持精确的风格迁移。在"赛博朋克东京夜景"生成测试中,可同时控制霓虹灯辉光强度(0-100%可调)、镜头畸变参数(鱼眼/广角切换)和色彩对比度曲线,满足专业创作者的精细化需求。
性能实测:消费级硬件的创作自由
WanVideo fp8模型在保持视频质量的同时,显著提升了生成速度。以14B-T2V模型为例,在25步采样、832x480x81分辨率下,无需LoRA即可生成高质量视频。最新的Wan2.2版本更是引入了4步极速生成技术,较传统模型提速数倍,5秒视频生成时间仅需约1分钟。
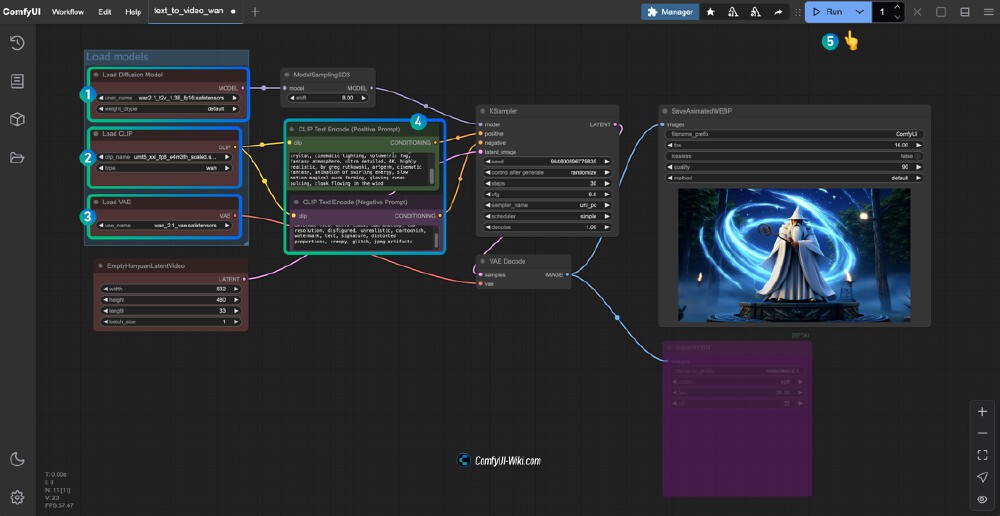
上图展示了使用Wan2.1模型(FP8 scaled版本)进行文本转视频的ComfyUI工作流界面,清晰呈现了模型加载、文本编码、采样及视频保存等节点配置。这种可视化流程设计使普通用户无需专业编程知识即可完成复杂视频生成任务。
在硬件适配方面,模型表现尤为突出:
- 1.3B参数版:仅需8GB显存,RTX 4060即可流畅运行
- 14B参数版:16GB显存RTX 4090可实现480p视频生成
- 多卡协同:支持2张RTX 4070 Ti通过NVLink扩展至720p创作
行业影响:从技术突破到生态重构
该模型的开源释放正在产生链式反应:短视频创作者通过普通消费级显卡即可实现日均30条原创内容产出;教育机构利用其I2V功能将静态教材转化为动态演示视频,内容制作成本降低60%;游戏厂商则将其整合进实时渲染管线,实现NPC动作的动态生成。生数科技CEO唐家渝指出:"这类模型的普及,标志着'人人可用'的视频大模型时代正式到来。"
WanVideo fp8模型的推出,标志着视频生成技术从"专业设备专属"向"大众创作工具"的关键转变。这种轻量化模型优化路线,为AI视频生成技术的普及奠定了基础。随着技术的不断进步,我们可以预见以下趋势:
- 创作门槛持续降低:8G显存起步的要求让更多个人创作者能够参与AI视频创作,推动内容创作普及化。
- 应用场景多样化:从自媒体短视频、产品展示到教育培训,轻量化视频生成模型将在各个领域发挥重要作用。
- 开源生态快速发展:WanVideo fp8模型的开源特性将促进开发者社区的创新,加速功能扩展和优化。
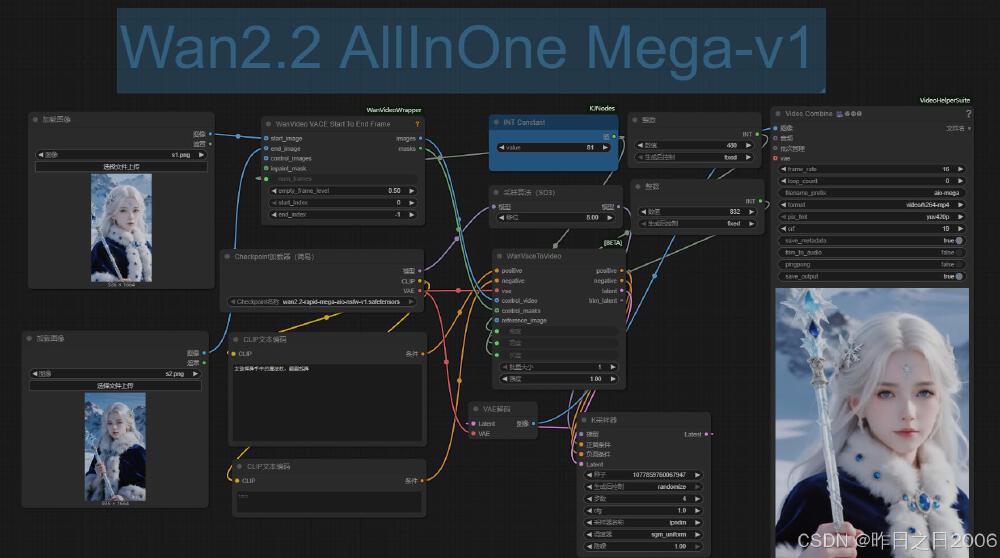
如上图所示,这是Wan2.2 AllInOne版本的ComfyUI工作流界面,展示了简洁的节点配置。用户只需通过Load Checkpoint节点即可一次性加载模型、CLIP和VAE,无需手动切换子模型,极大降低了操作复杂度,体现了模型在工作流程设计上的高效性。
部署指南与未来展望
对于不同用户群体,我们建议:
个人创作者:可通过以下步骤快速启动创作
- 克隆仓库:https://gitcode.com/hf_mirrors/Kijai/WanVideo_comfy_fp8_scaled
- 安装依赖:ComfyUI + ComfyUI-WanVideoWrapper插件
- 模型选择:根据显存容量选择1.3B或14B版本
- 开始创作:通过Text Encode节点输入描述词,调整采样步数(推荐20-25步)
企业用户:关注WanVideo模型的API服务进展,利用其高效低成本的特性提升视频内容生产效率。
未来,Wan-AI团队 roadmap显示,下一代模型将重点突破:1)视频时长限制(从5秒扩展至30秒);2)多镜头叙事能力;3)移动端实时生成支持。对于开发者而言,现在正是基于该模型进行垂直领域微调的最佳时机,尤其在广告创意、虚拟偶像和智能监控等场景潜力巨大。
WanVideo_comfy_fp8_scaled模型通过"精度无损压缩"技术路径,证明了开源模型完全能与闭源商业产品竞争。在AI视频生成即将爆发的2025年,掌握这类高效能模型将成为内容生产的核心竞争力。
转载自CSDN-专业IT技术社区
原文链接:https://blog.csdn.net/gitblog_00625/article/details/154052760

