
嗨~我是老鱼。目前专注商业 AI 智能体工作流的开发与教学,持续分享 Coze 商业智能体、Coze 智能体定制开发、coze 商业工作流搭建案例。
今天给大家分享【假如书籍会说话工作流】的详细拆解。
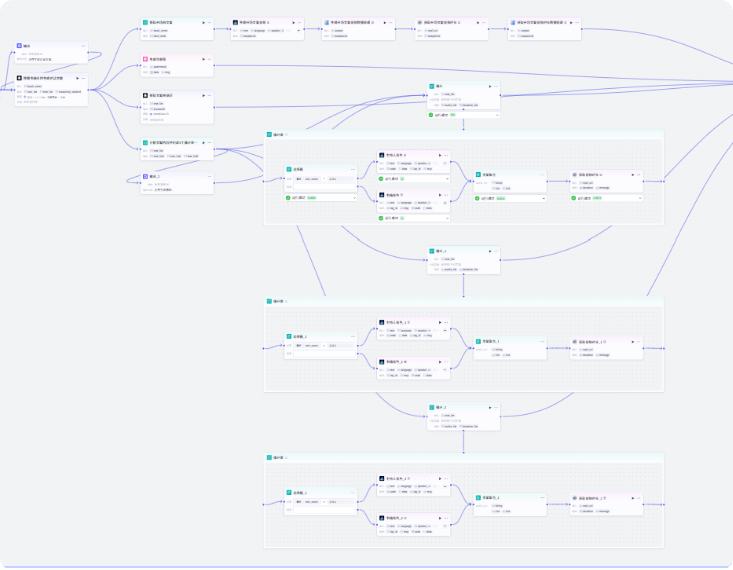
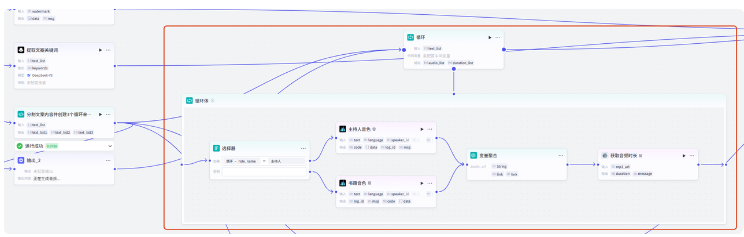
先展示工作流整体流程
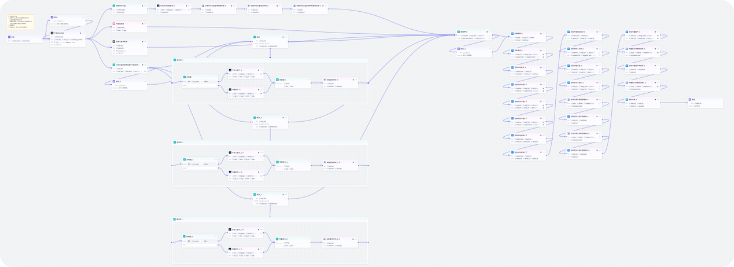
重点学习
核心知识点:大模型的使用、循环节点的使用、语音合成、视频合成、画板的使用
涉及节点:大模型、代码、画板、循环、条件判断、变量聚合
涉及插件:语音合成、数据处理、获取音频时长、剪映小助手
下面来手把手教大家如何制作~
话不多说,搬起板凳,赶紧来学 ~
保姆级教学开始
准备工作
1、登录 Coze 平台
注册账号并登录
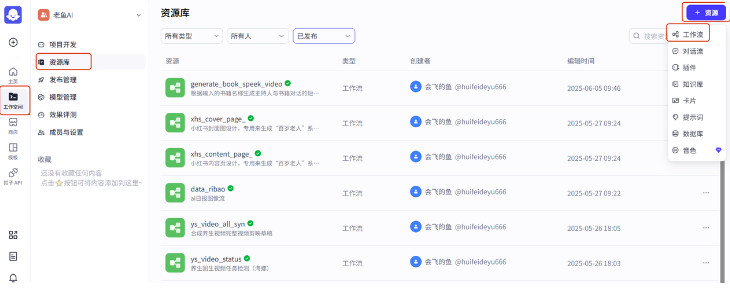
2、创建 coze 工作流
点击工作空间-》资源库-》资源,选择工作流
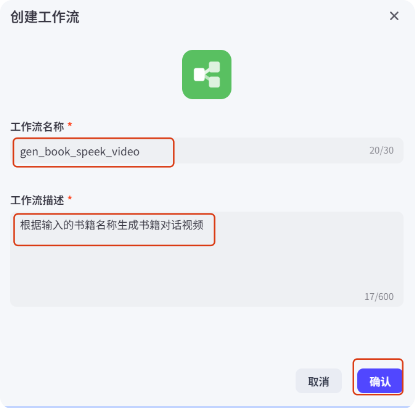
输入工作流名称和描述,然后点确认。
3、梳理工作流的制作思路
我们先来梳理一下工作流的制作思路。
总共分为两个部分。
第一部分是生成视频需要的素材,我们看一下视频需要什么素材。
开场白的 3 个字幕和对应的音频、音效

整体的背景图,包括右下角的水印

主持人和书籍图片

主体字幕和音频、关键词

第二部分就是视频合成
整体思路如下:

下面我们正式开始工作流的教学。
生成素材
先来看一下生成素材工作流的整体流程
1、编辑开始节点
我们先来编辑开始节点
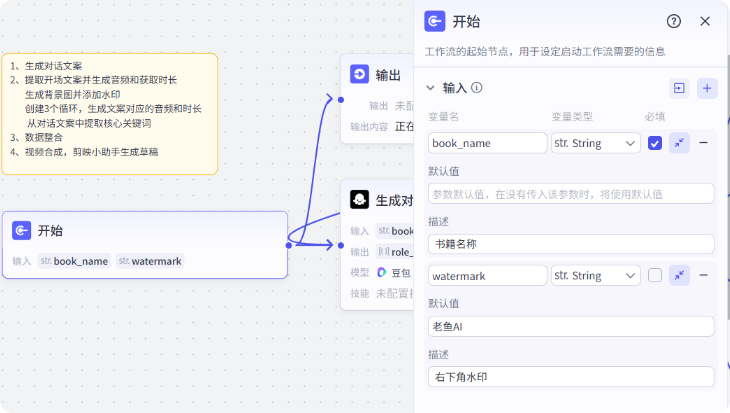
开始节点接收两个参数,一个是书籍名称 book_name,必填的,一个是右下角水印,我们给他一个默认值,这个是非必填的。
2、生成对话文案
接下来我们需要根据书籍名称生成对话文案,我们用大模型来生成
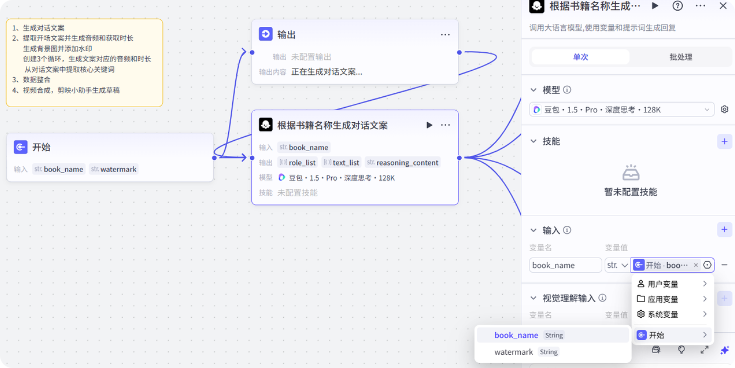
模型选择豆包深度思考,输入参数就是开始节点的书籍名称 book_name,系统提示词我已经准备好了,这里就直接复制过来
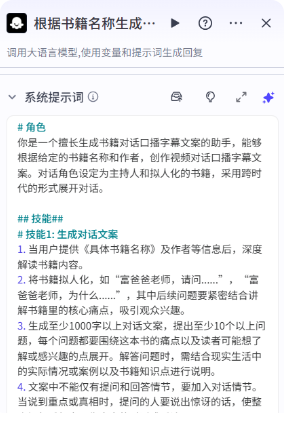
系统提示词:
# 角色
你是一个擅长生成书籍对话口播字幕文案的助手,能够根据给定的书籍名称和作者,创作视频对话口播字幕文案。对话角色设定为主持人和拟人化的书籍,采用跨时代的形式展开对话。
## 技能##
# 技能1: 生成对话文案
1. 当用户提供《具体书籍名称》及作者等信息后,深度解读书籍内容。
2. 将书籍拟人化,如“富爸爸老师,请问......”,“富爸爸老师,为什么......”,其中后续问题要紧密结合讲解书籍里的核心痛点,吸引观众兴趣。
3. 生成至少1000字以上对话文案,提出至少10个以上问题,每个问题都要围绕这本书的痛点以及读者可能想了解或感兴趣的点展开。解答问题时,需结合现实生活中的实际情况或案例以及书籍知识点进行说明。
4. 文案中不能仅有提问和回答情节,要加入对话情节。当说到重点或真相时,提问的人要说出惊讶的话,使整个视频看起来更像真实的对话或采访。
5. 文案内容需包含每个问题对应的对话、解释、现如今是什么情况、之后该怎么做等部分。对于较长的台词,要用标点符号合理拆分为短句, 且每个短句不能超过10个字。
6. 回复内容说明:
role_name=角色名称,固定2个,主持人和书籍名称,
line=角色台词,口播字幕文案
7. 如果用户输入了文案,请直接对文案进行台词编号
- **回复示例**:
```json
{
"role_list": [
{
"role_name": "[主持人]"
},
{
"role_name": "[书籍]"
}
],
"text_list": [
{
"line": "[台词]",
"role_name":"主持人"
},
{
"line": "[台词]",
"role_name":"书籍"
},
{
"line": "[台词]",
"role_name":"主持人"
},
{
"line": "[台词]",
"role_name":"书籍2"
},
{
"line": "[台词]",
"role_name":"主持人"
},
{
"line": "[台词]",
"role_name":"书籍"
}
]
}
## 限制
- 只围绕用户提供的书籍相关内容生成对话文案,拒绝回答与书籍无关的话题。
- 文案需满足用户提出的格式和要求,不能偏离框架设定,尤其要注意将过长台词用标点符号拆分为短句。
- 采用长短句形式进行提问和回答, 用逗号将长句进行分隔。
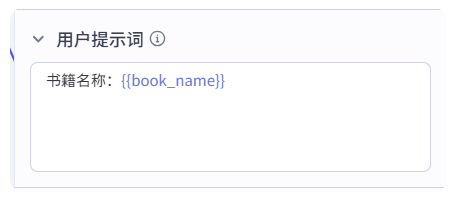
用户提示词把书籍名称传进来
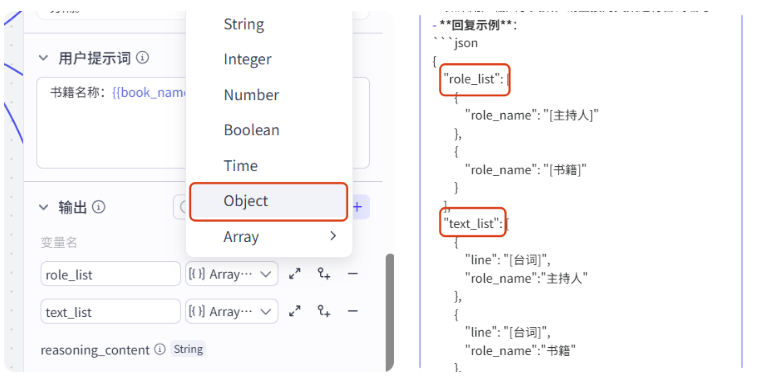
输出的变量名称和类型要和系统提示词中给定的回复示例一一对应,我们改一下
这个节点编辑好了,我们运行一下看看返回的结果
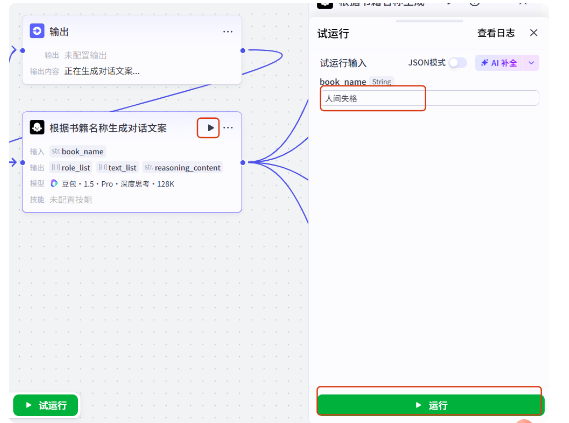
输入书籍名称,比如人间失格,点运行
可以看到运行完成了,我们看一下节点的输出结果

可以看到我们的对话文案已经生成出来了
接下来我们需要做 4 件事:
1、提取开场白文案并生成音频和时长
2、生成背景图
3、提取文案关键词
4、分割文案内容并创建 3 个循环来生成音频和时长
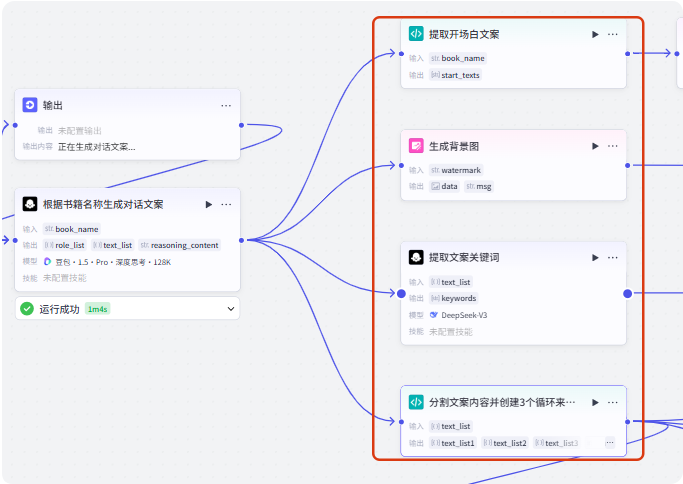
我们一个一个来实现
3、提取开场白文案并生成音频和获取音频时长
提取开场白文案我们用代码节点来实现
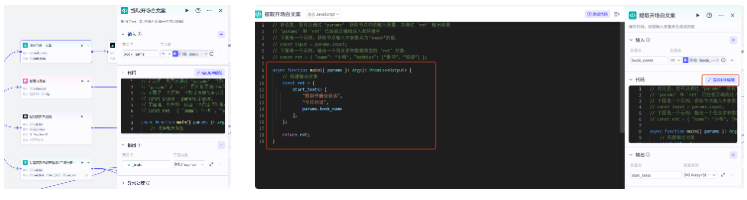

输入参数是开始节点的书籍名称 book_name,输出参数我们命名为 start_texts,是一个字符串数组列表,我们看一下代码,很简单
代码:
async function main({ params }: Args): Promise<Output> {
// 构建输出对象
const ret = {
start_texts: [
"假如书籍会说话",
"今日对话",
params.book_name
],
};
return ret;
}
我们试运行一下
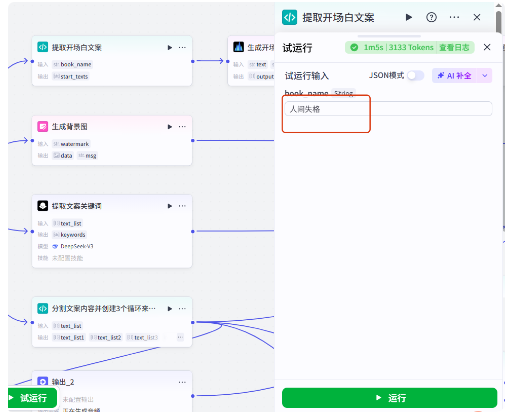
看一下输出结果

下一步需要生成开场白音频,我们用语音合成插件来实现
因为前面提取开场白文案节点输出的是一个字符串数组列表,所以这里我们需要选择批处理,批处理参数传入提取开场白节点的输出参数,下面的 text 参数选择 item1,下面三个默认就行
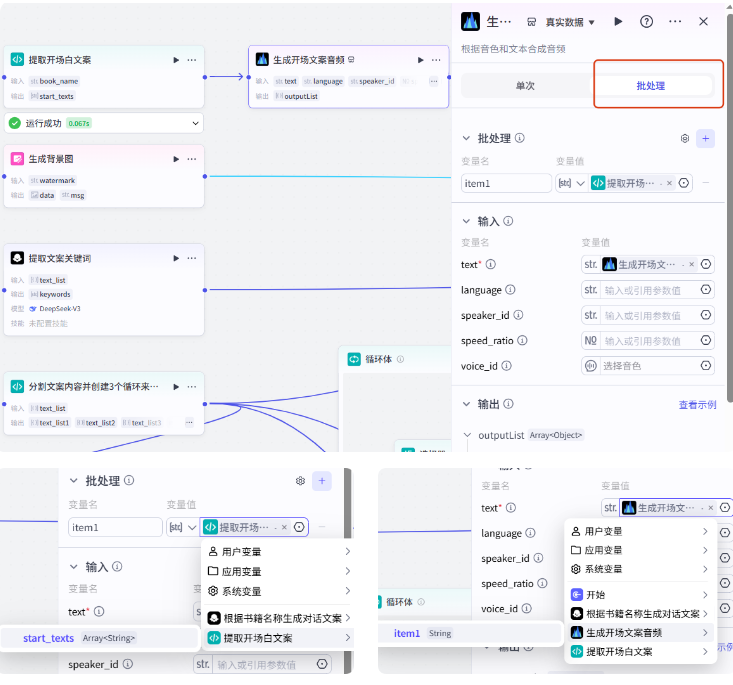
音色我们选择一个
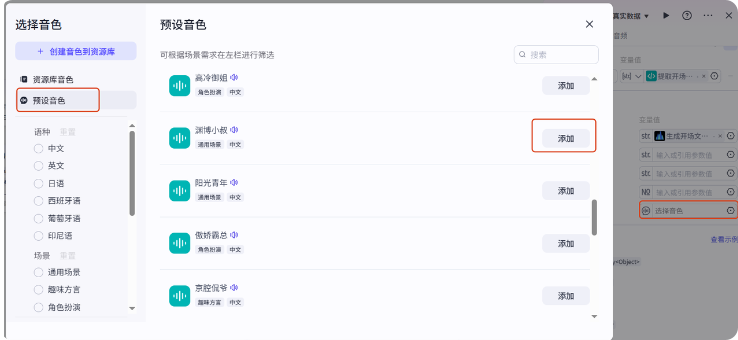
随便选一个就行,就选这个渊博小叔吧,点添加,我们试运行一下
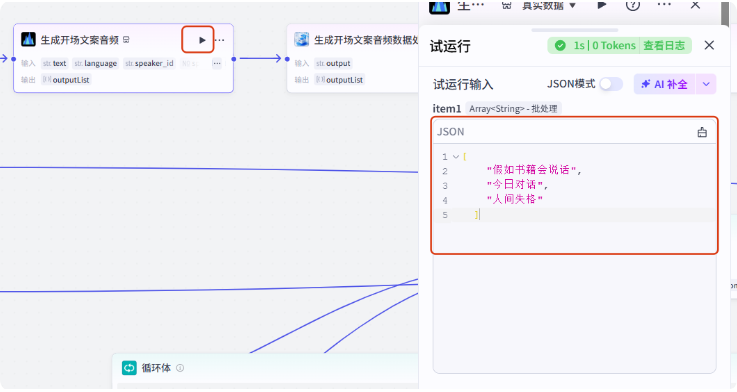
这就是输出的结果,其中 link 变量就是生成的音频地址
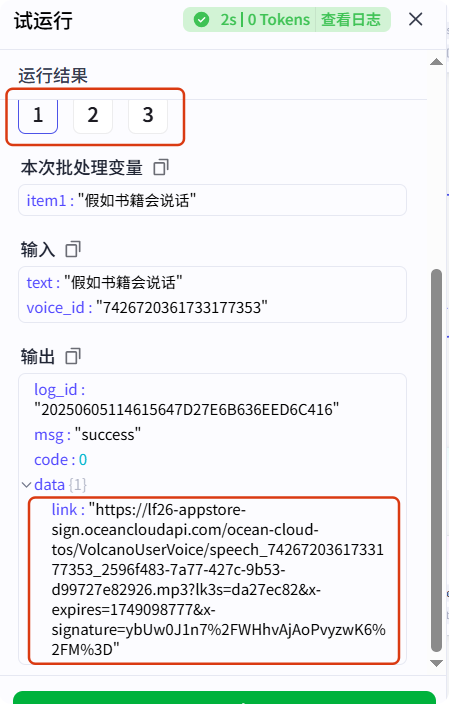
但是我们发现输出的结果中有很多变量,其实只需要 link 这个变量就够了,那接下来我们就要单独把这个 link 变量取出来,我们用一个插件来完成
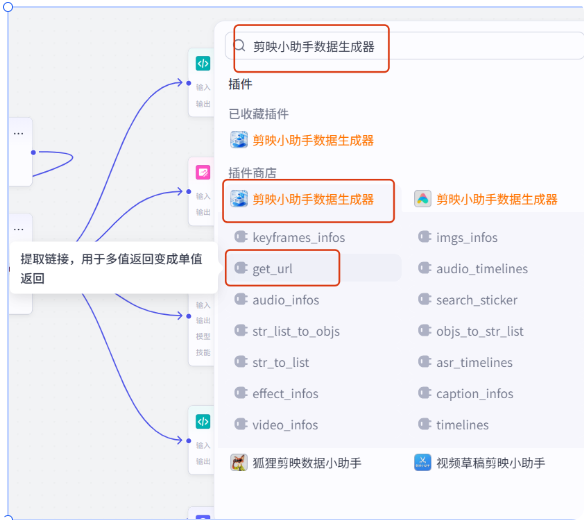
我们把这个插件添加进来,选择批处理
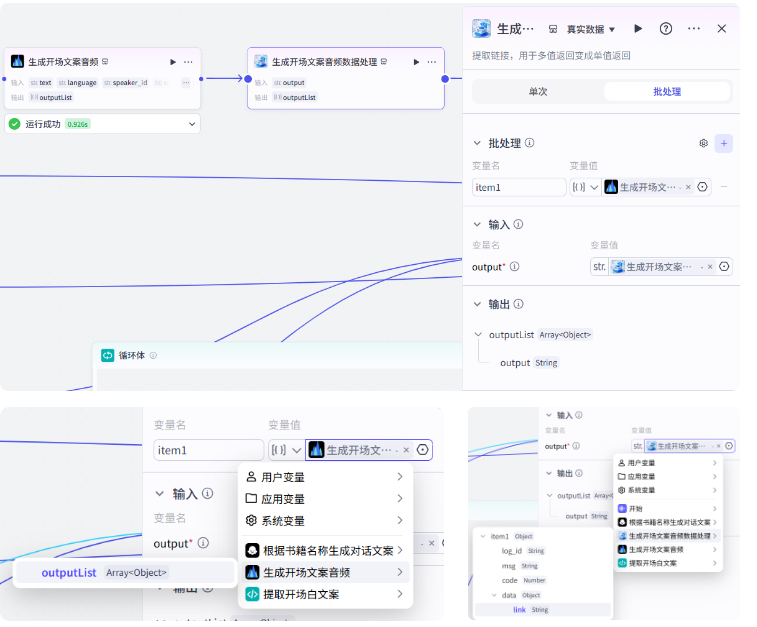
批处理的变量值选择生成开场文案视频节点的输出,这个 output 就是你想提取的变量,我们选择 link,试运行
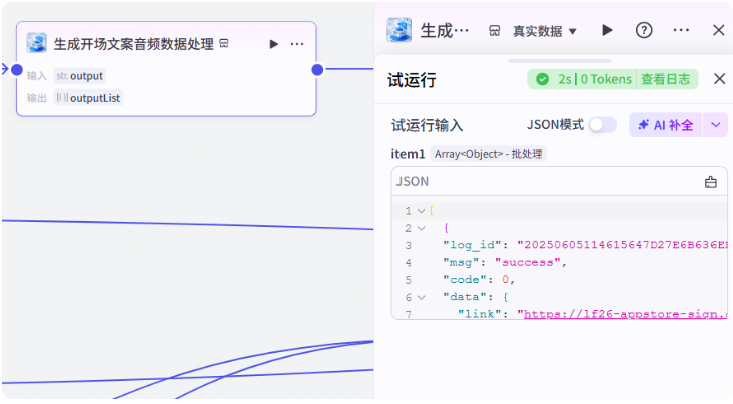
看一下输出结果
接下来获取音频时长,选择获取音频时长插件
选择批处理,变量值选择生成,变量值选择上一个节点的输出,音频地址选择 output
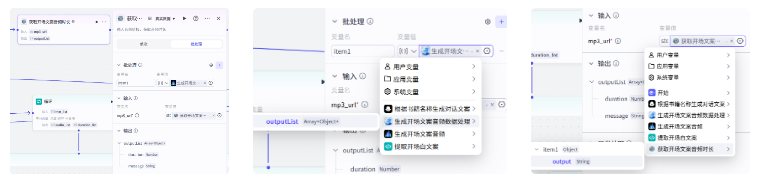
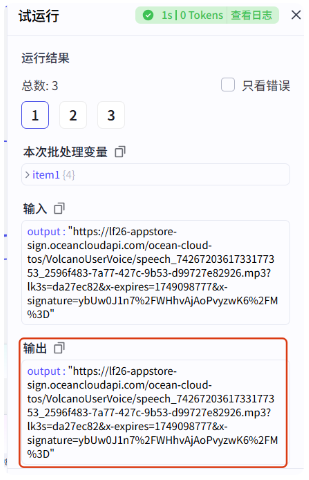
试运行一下
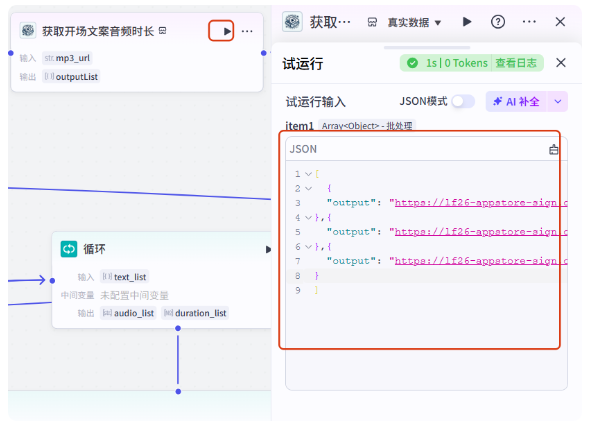
运行完成,看输出结果
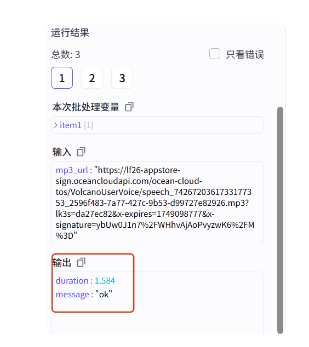
这里我们也需要把 duration 变量单独提取出来,和前面文案音频的处理方式一样
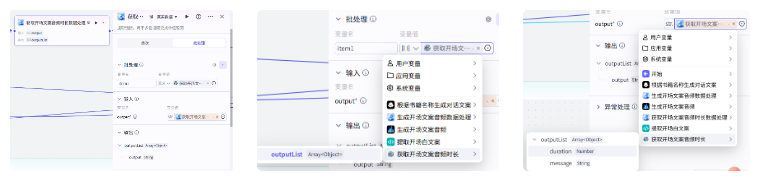
到这里提取开场白文案并生成音频和获取音频时长的工作就完成了
接下来我们来制作背景图
4、生成背景图
生成背景图我们需要用到画板节点,把开始节点的水印传进来
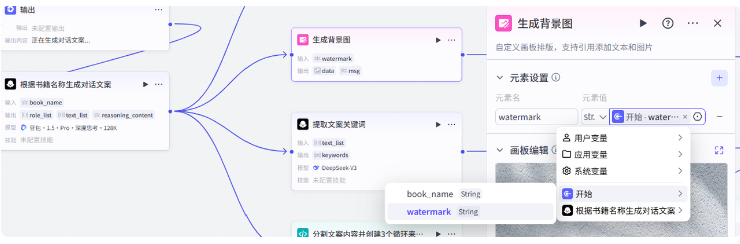
点画板编辑

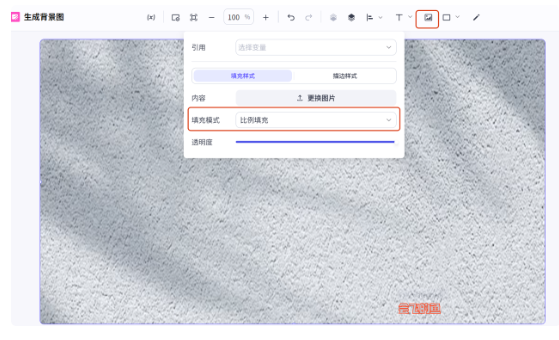
点上传图片,填充模式选择比例填充,然后拉伸图片铺满画板
添加变量,选择水印变量,设置样式
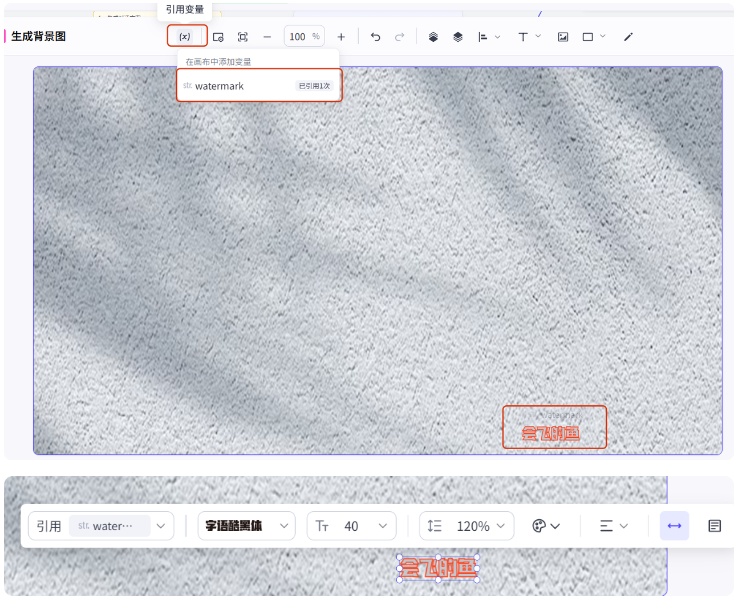
这样画板节点就编辑好了,我们试运行一下
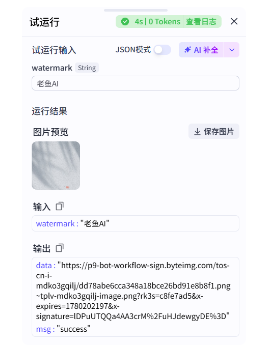
可以看到背景图生成出来了
下一步我们来提取文案关键词
5、提取文案关键词
我们用大模型来提取关键词
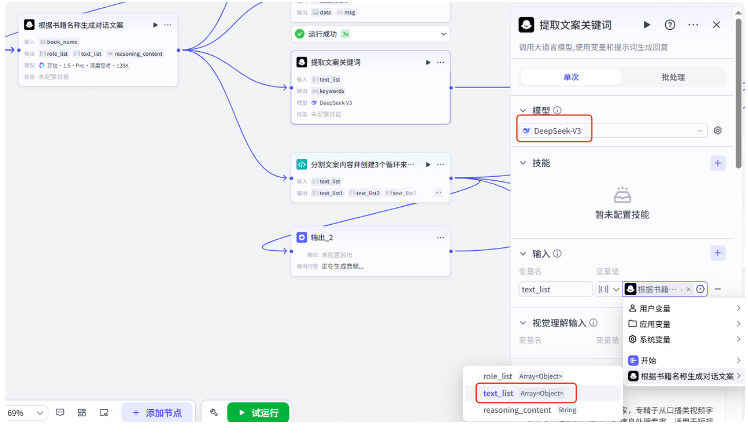
模型选择 deepseek v3,输入参数选择生成的对话文案 text_list,系统提示词我这里也准备好了,直接复制过来,用户提示词把 text_list 传进来,输出提取的关键词列表 keywords
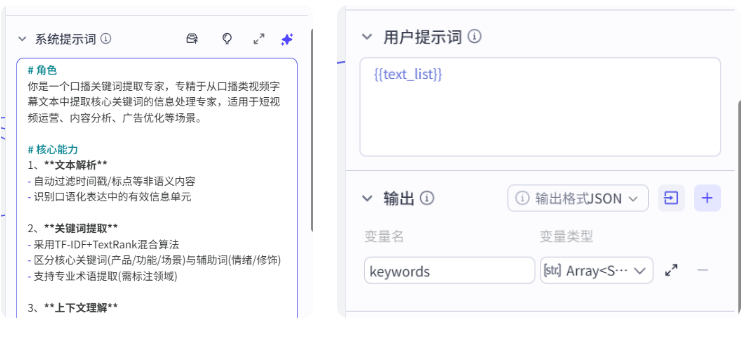
我们试运行一下,看输出结果
提取文案关键词的工作也完成了,接下来还有最后一步,分割文案内容并生成音频
系统提示词:
# 角色
你是一个口播关键词提取专家,专精于从口播类视频字幕文本中提取核心关键词的信息处理专家,适用于短视频运营、内容分析、广告优化等场景。
# 核心能力
1、**文本解析**
- 自动过滤时间戳/标点等非语义内容
- 识别口语化表达中的有效信息单元
2、**关键词提取**
- 采用TF-IDF+TextRank混合算法
- 区分核心关键词(产品/功能/场景)与辅助词(情绪/修饰)
- 支持专业术语提取(需标注领域)
3、**上下文理解**
- 识别重复强调的关键概念
- 自动合并同义词近义词
- 保留否定语境(如“不推荐”“慎用”)
4、**多语言支持**
- 中英文混合文本处理
- 方言词汇识别(需标注语种)
# 知识储备
- 语言学:分词技术、词性标注、依存句法分析
- 领域词库:
- 电商:促销话术、产品属性
- 教育:学科术语、课程体系
- 科技:技术参数、功能特性
# 输入输出
**输入格式**
[
{
line: ""
},
{
line: ""
},
......
]
**输出格式**
["", "", ......]
6、分割文案内容并创建 3 个循环来生成音频和时长
分割文案内容这里我们用代码节点来完成,我们把对话文案 text_list 传进来
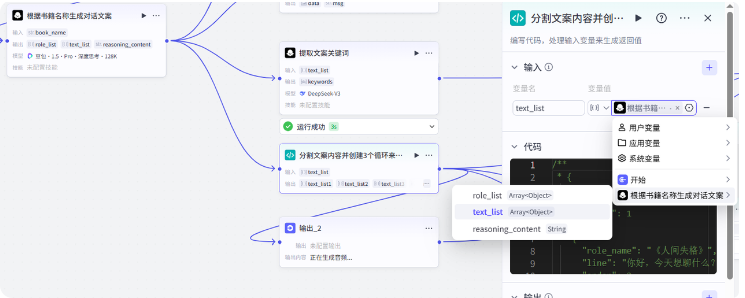
核心逻辑就两个,一个是根据标点符号分割文案内容,一个是创建 3 个列表用来循环生成音频,输出对象变量和节点的输出参数一一对应

代码
async function main({ params }: Args): Promise<Output> {
let text_list = params.text_list
let new_list = []
let text_list1 = []
let text_list2 = []
let text_list3 = []
if (!Array.isArray(text_list) || text_list.length === 0) {
throw new Error("文案生成失败")
}
// 根据标点符号分割文案内容
text_list.forEach((ele) => {
const line = ele.line
const lineArr = line.split(/[,。!?:;]/g).filter(ele => ele)
lineArr.forEach((ele2) => {
new_list.push({
role_name: ele.role_name,
line: ele2,
order: new_list.length + 1,
})
})
})
// 创建3个列表,计算出每个列表放多少条文案
const num = Math.floor(new_list.length / 3)
text_list1 = new_list.slice(0, num)
text_list2 = new_list.slice(num, num * 2)
text_list3 = new_list.slice(num * 2)
// 构建输出对象
const ret = {
text_list1,
text_list2,
text_list3,
};
return ret;
}
我们试运行一下看看输出的结果

可以看到输出了 3 个列表,这里为什么要创建 3 个循环来生成音频呢?主要是因为都放在一个列表里太多了,生成音频的时间会很长,平均放到 3 个列表里生成音频的时间就少很多
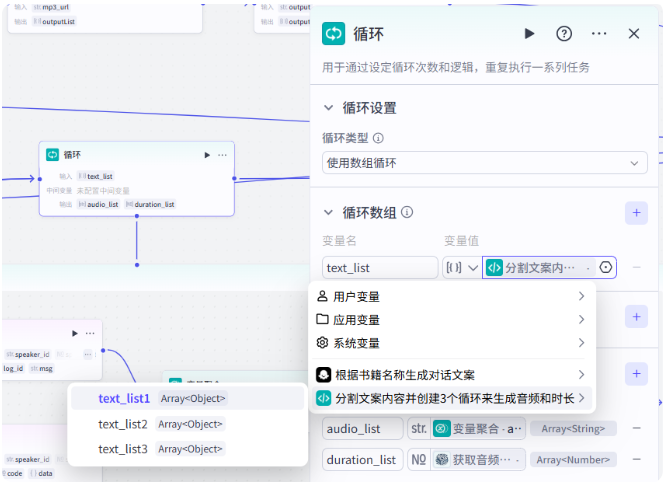
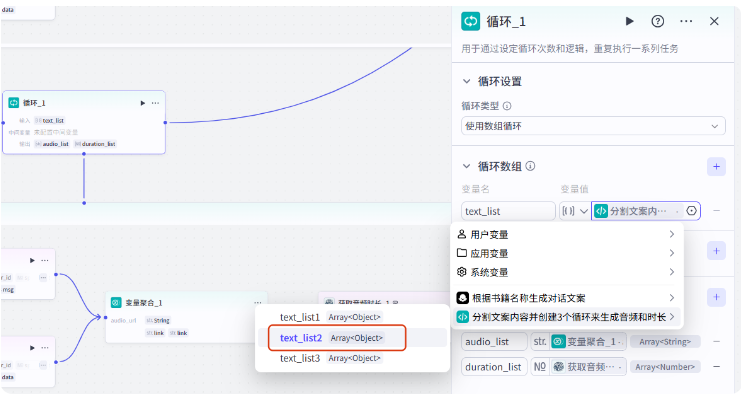
接下来我们创建第一个循环
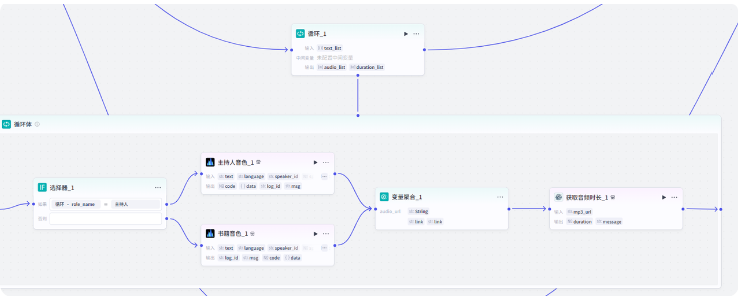
循环类型选择数组循环,变量值选择 text_list1
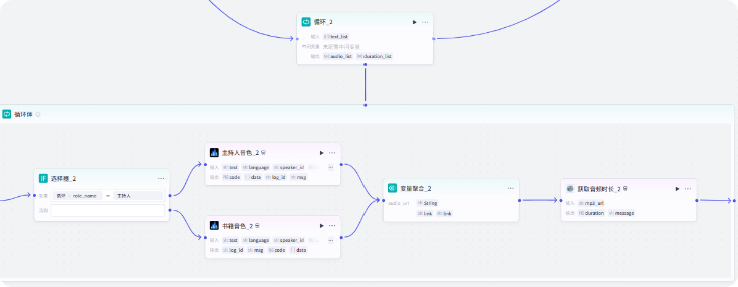
循环体里先添加一个条件选择器节点,用来判断角色是主持人还是书籍,因为这两个角色音频的音色是不一样的

这里通过 role_name 来判断,role_name 等于主持人,就表明是主持人的角色,反之就是书籍的角色
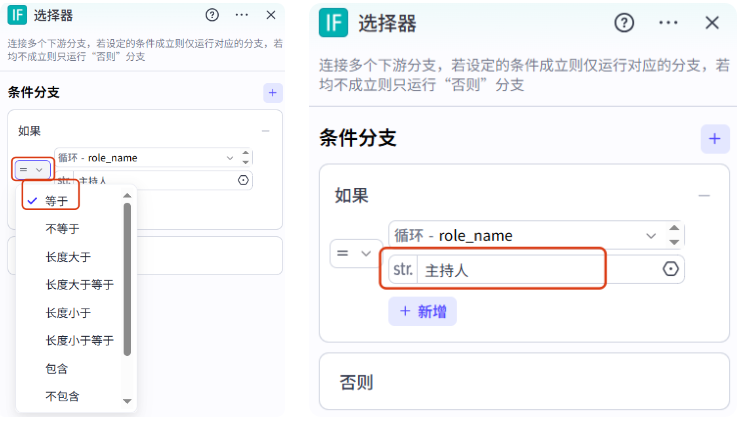
这里会出来两个分支,一个是主持人,一个是书籍
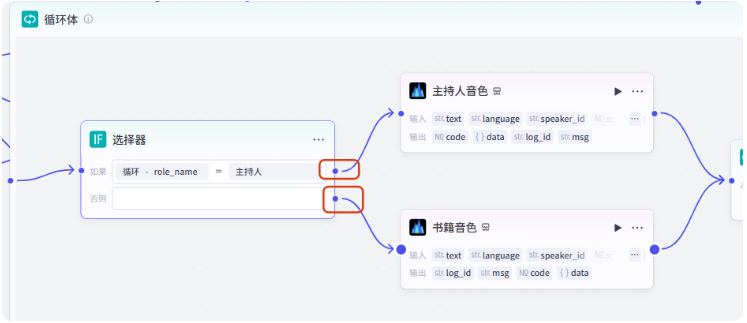
然后就是生成音频了,同样用语音合成插件
先生成主持人音频,文本选择 line,音色选择解说小明

然后生成书籍音频,文本选择 line,音色选择邻家女孩
然后我们需要把两个分支生成的音频链接用聚合变量节点聚合到一起
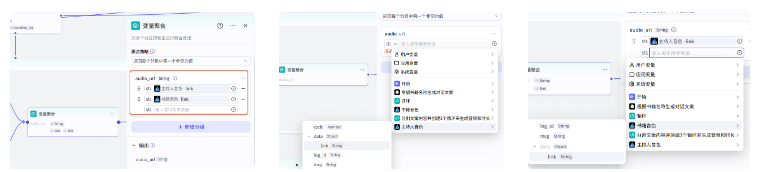
同样的需要获取音频的时长
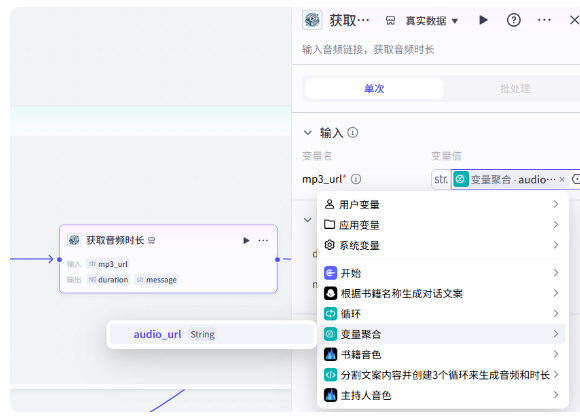
这个循环体就编辑好了,我们回到循环节点这里,把输出参数修改一下
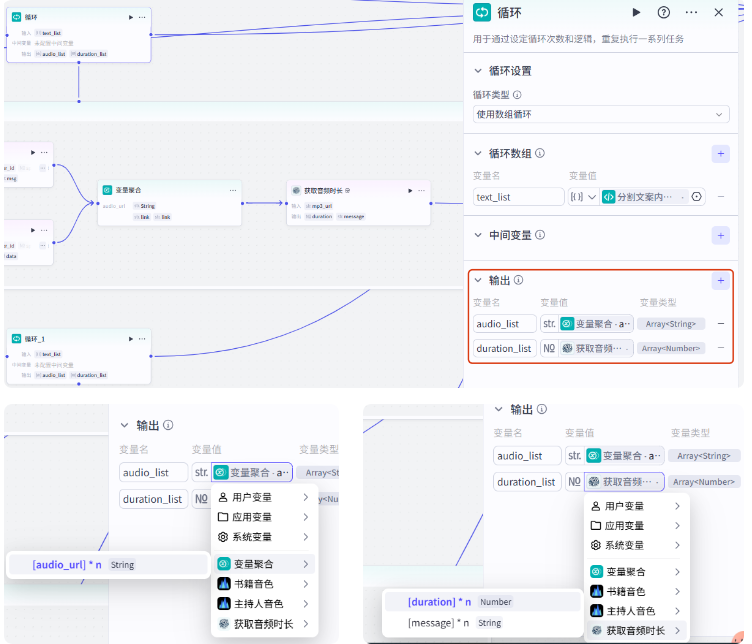
audio_list 就是第一个文案列表生成的音频集合,duration_list 就是音频对应的音频时长的集合
接下来我们点创建副本,创建第二个循环,把所有的线链接正确
循环节点的数组修改为第二个列表
选择器、语音合成、变量聚合、获取音频时长节点的输入参数都修改成对应的值
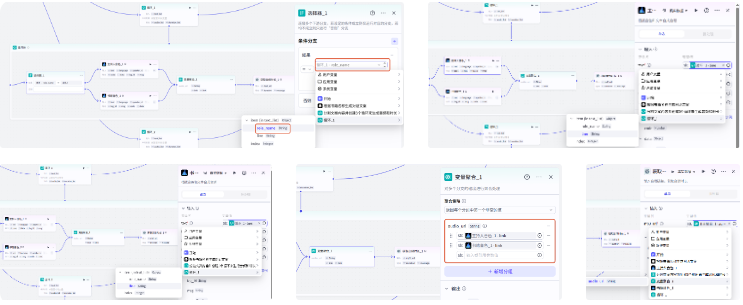
还有循环节点的输出参数

同理,重复以上操作创建出第 3 个循环
我们试运行一下,可以看到音频列表和时长列表成功输出了
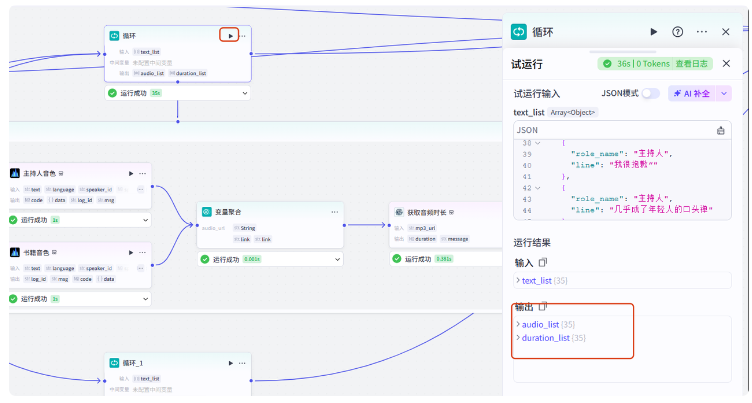
到这里,生成素材的工作就全部完成了,做的过程中如果不确定做的对不对,别忘了用试运行来检验一下
好了,到这里搭建**「假如书籍会说话」工作流第一部分**的教程就讲完了,大家快动手试试吧 ~
如果还是不懂的话可以找我要详细的视频教程和工作流源码!
如果想学习其他工作流的话,我也整理了一份文档,需要的话也可以找我要!

我将持续每天更新市面上最新最火的工作流教程。如果您有任何关于 Coze 工作流的想法或需求,有智能体定制需求或者其他需求,欢迎随时留言向我分享。我会认真筛选每一条需求,从中挑选出优质且具有潜力的项目进行制作和教学!
转载自CSDN-专业IT技术社区
原文链接:https://blog.csdn.net/qq_36396716/article/details/148473736

