
更新通知
最新版前台系统+后台管理系统整合了 YOLOv11/v8 算法 + PaddleOCR 算法完成车牌检测和车牌识别系统,由于 YOLOv11+CNN 车牌识别系统对倾斜角度较大和模糊的图片识别效果不佳、识别车牌单一、界面功能和样式单一 等问题,在本期的基础上进行升级 ,更多细节看点击下面的链接查看。
点击即可跳转: 手把手教你使用 YOLOv11/v8算法 + PaddleOCR算法完成车牌检测和车牌识别系统,AI智能体,毛玻璃系统,包括PaddlePaddle安装、数据集预处理、模型训练、AI大模型应用等
最新版系统演示效果如下:
| 模块 | 界面演示 |
|---|---|
| 登录与注册 | 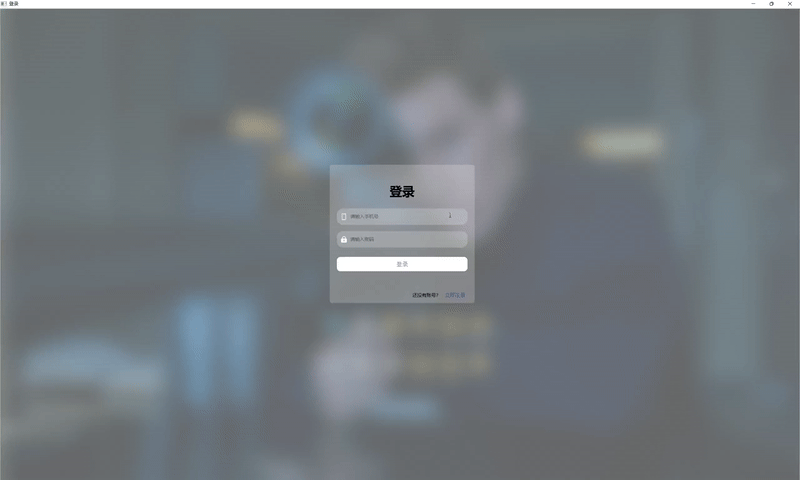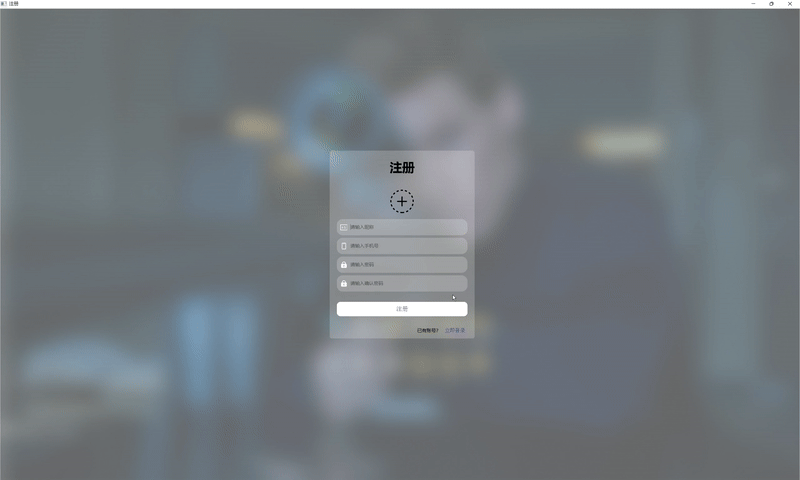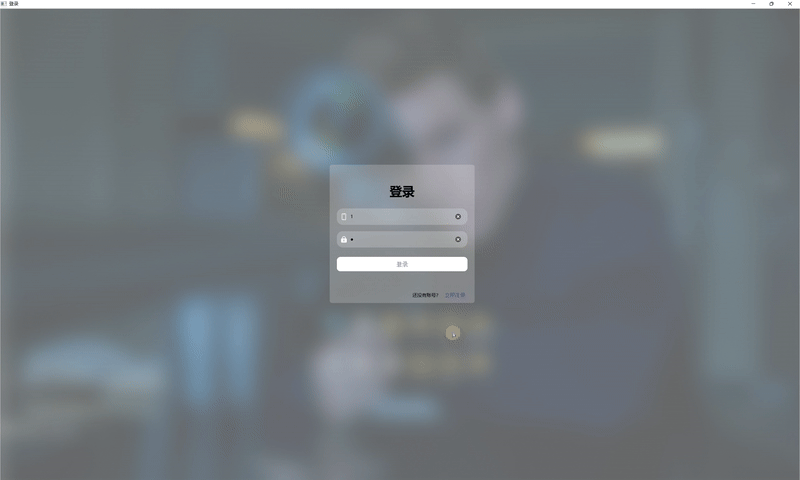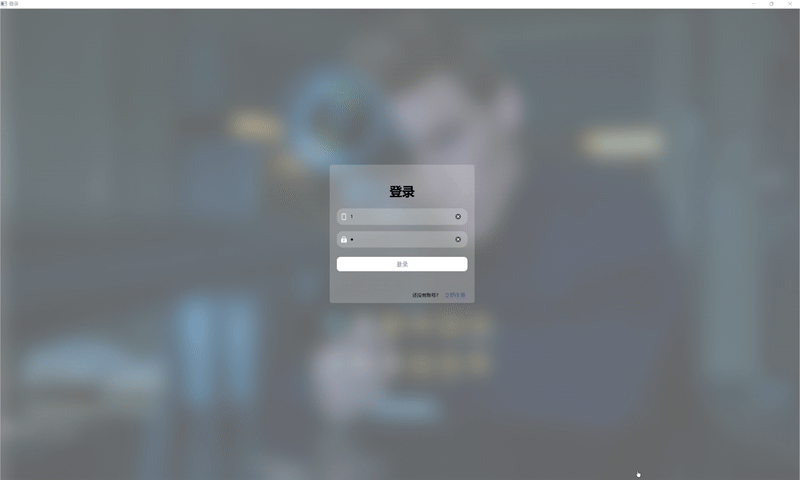 |
| 界面演示 |  |
| AI 智能操作 演示 | 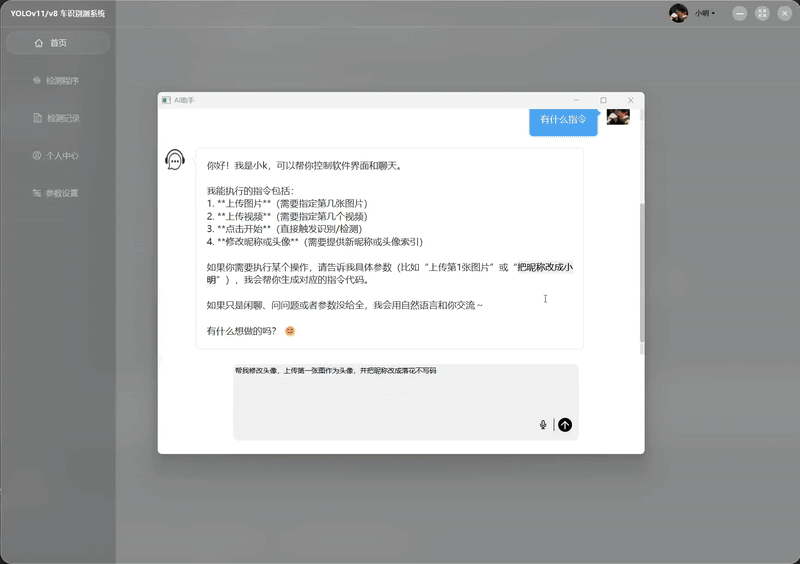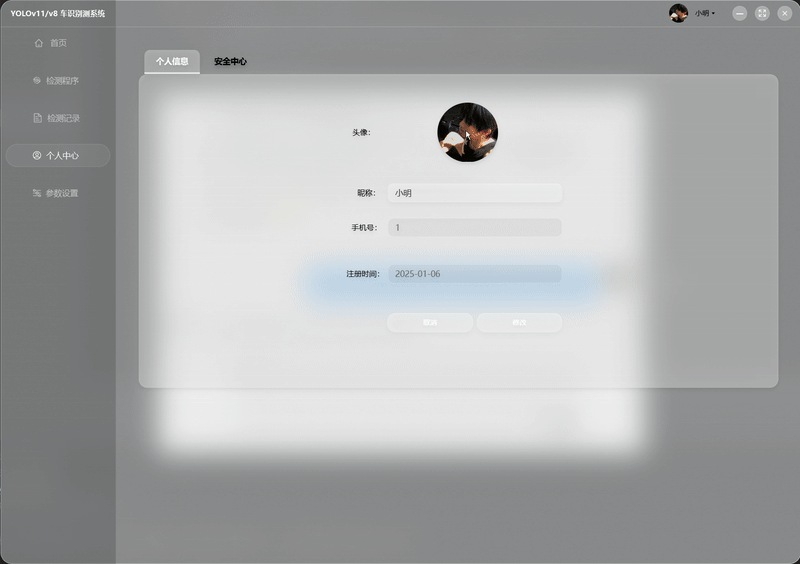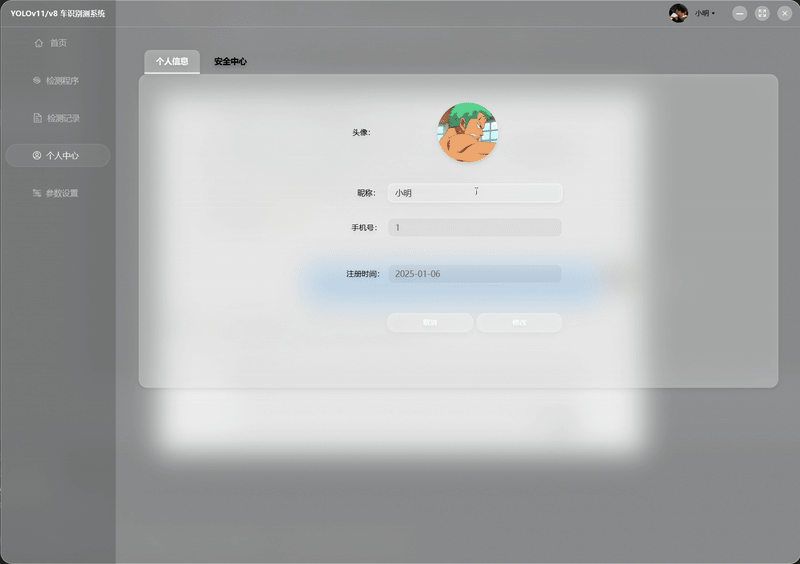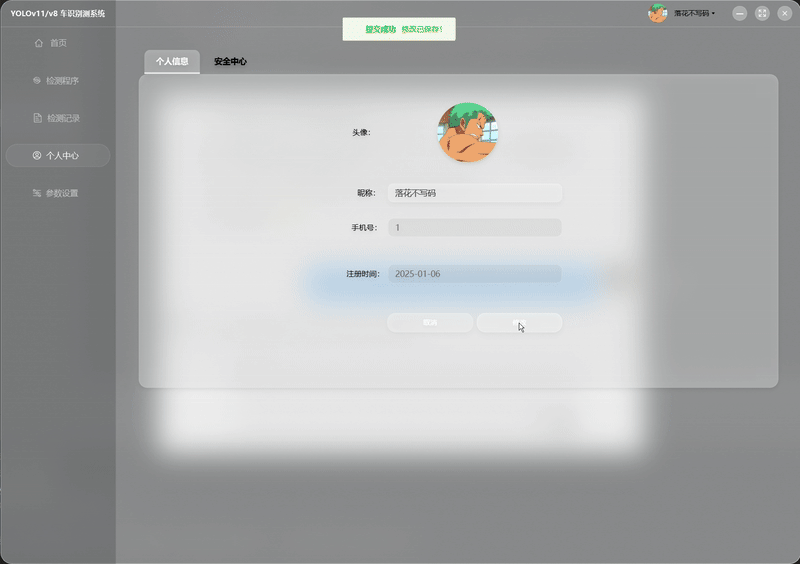 |
| 新能源车牌识别 | 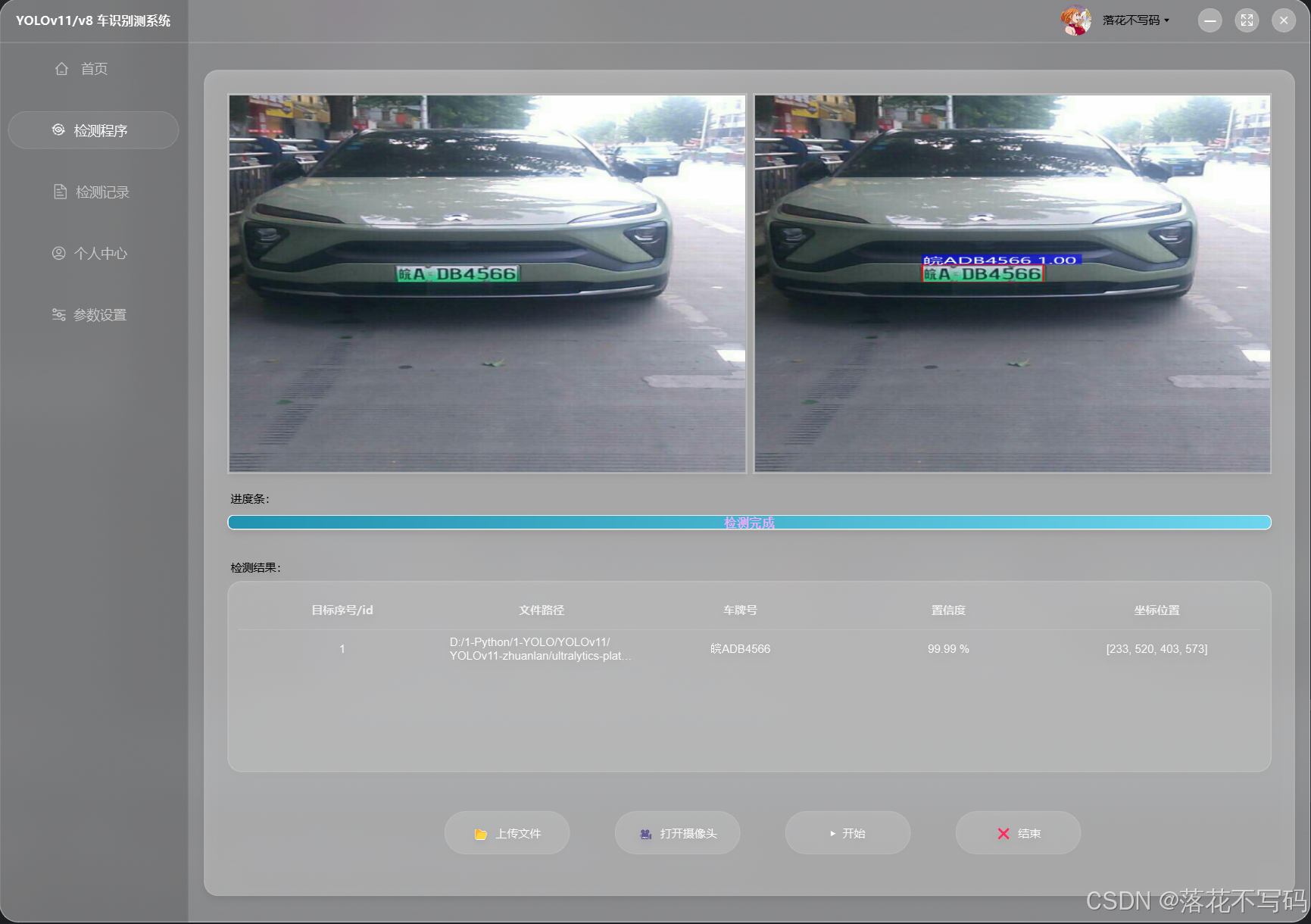 |
| 蓝色车牌识别 |  |
| 其他颜色车牌 | 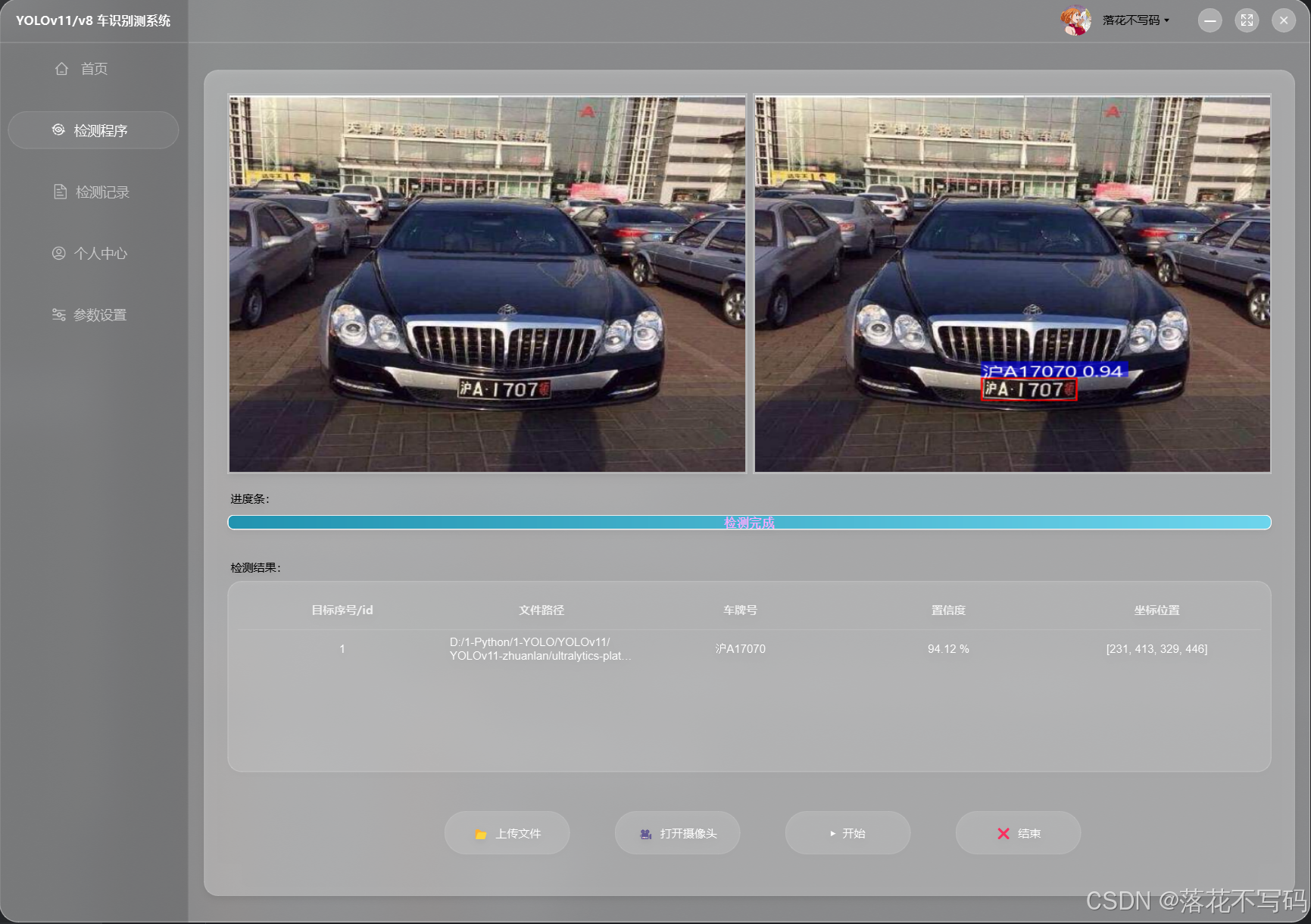 |
| 黄色车牌识别 | 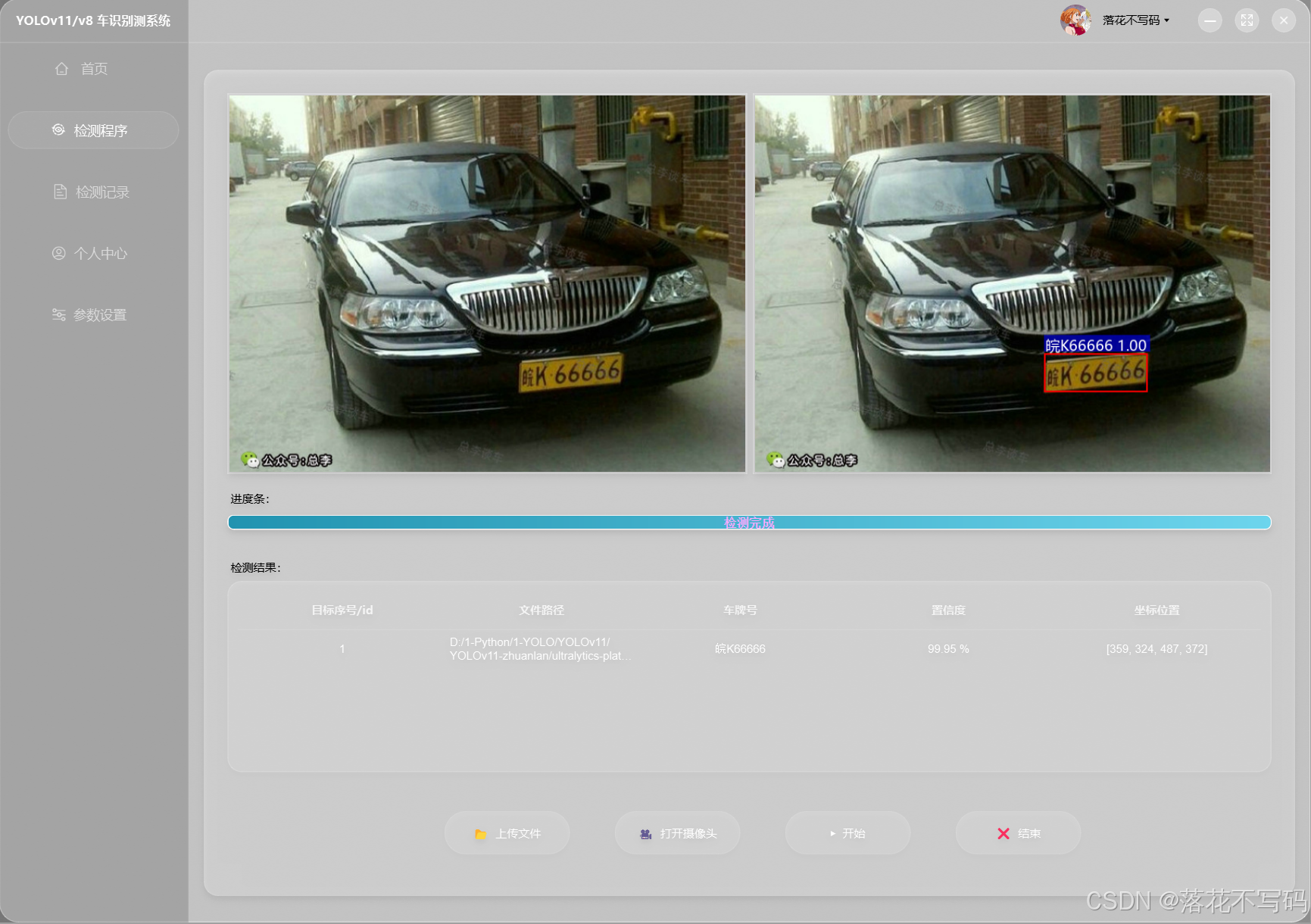 |
| 双层车牌识别 | 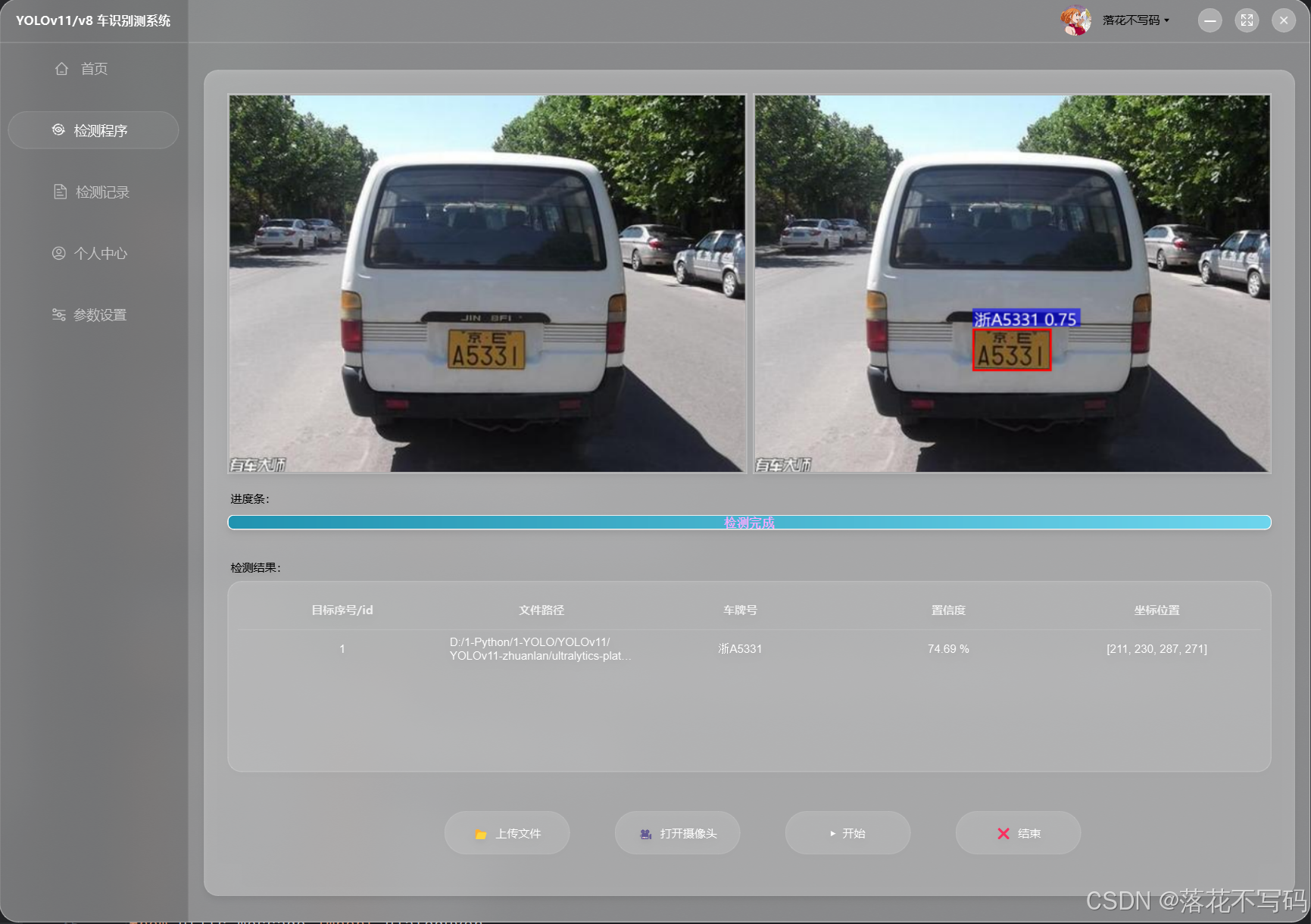 |
| 官网模型开启双层车牌分割 | 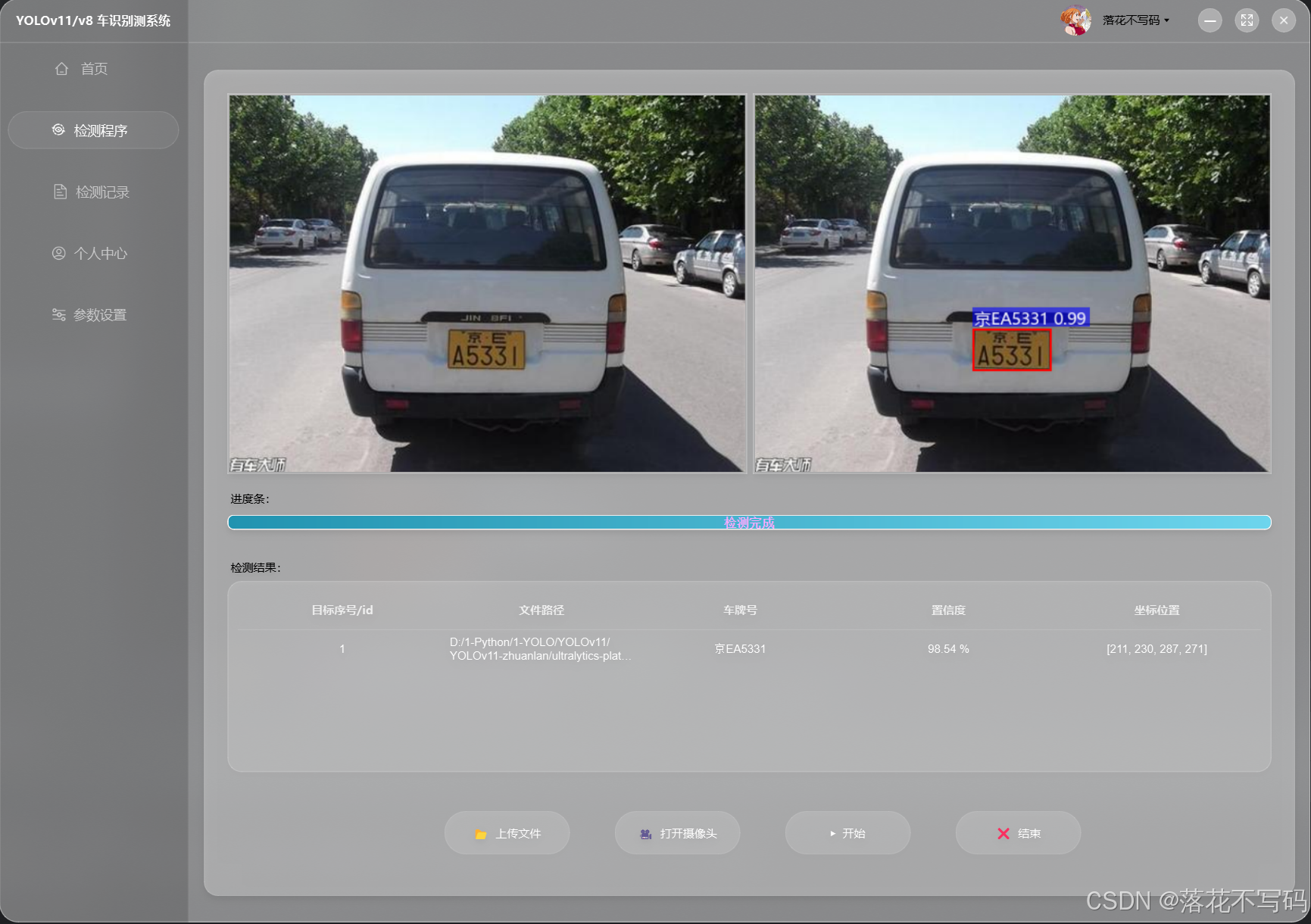 |
| 历史记录模块 | 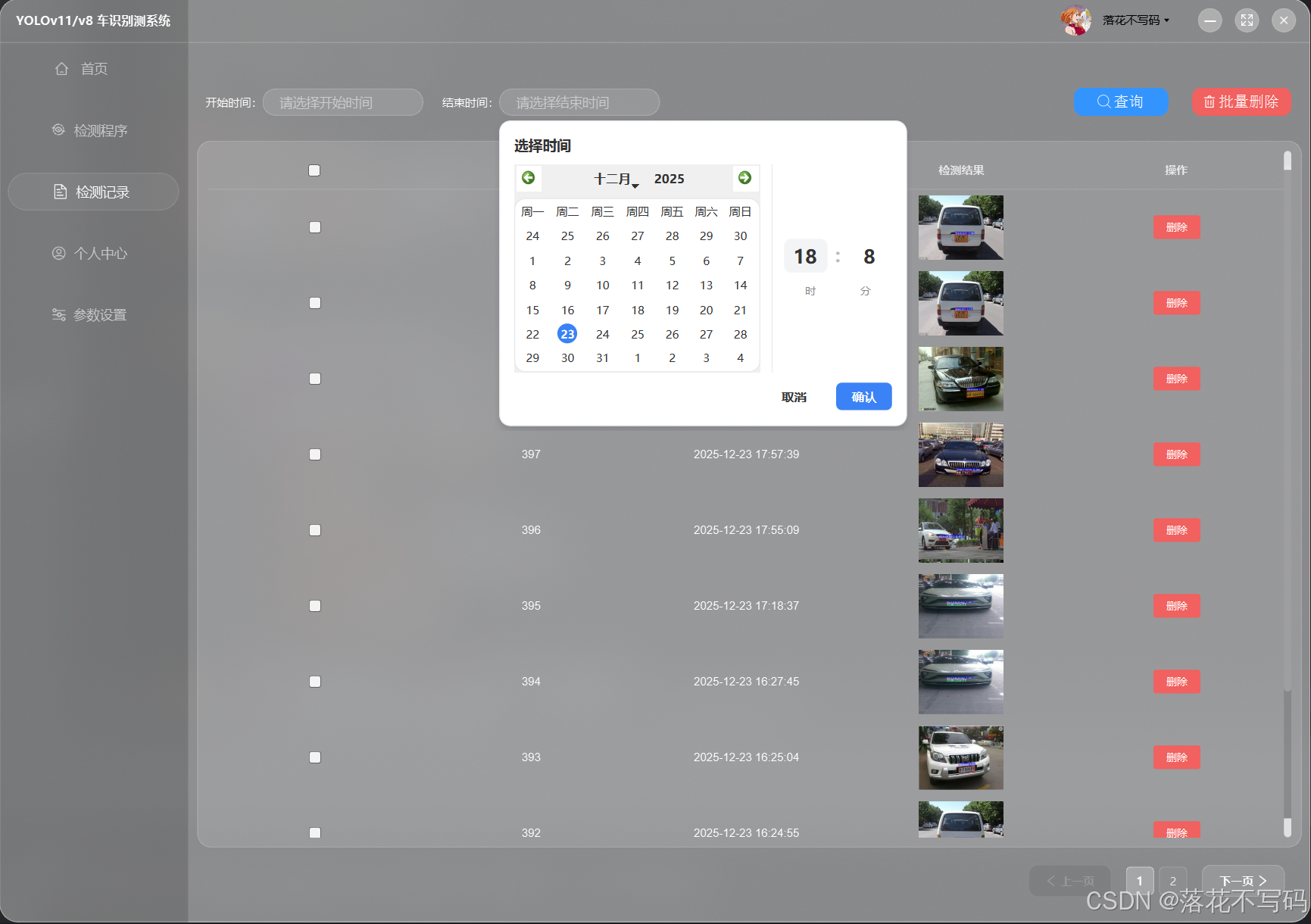 |
| 用户个人中心模块 |  |
| 后台-首页 | 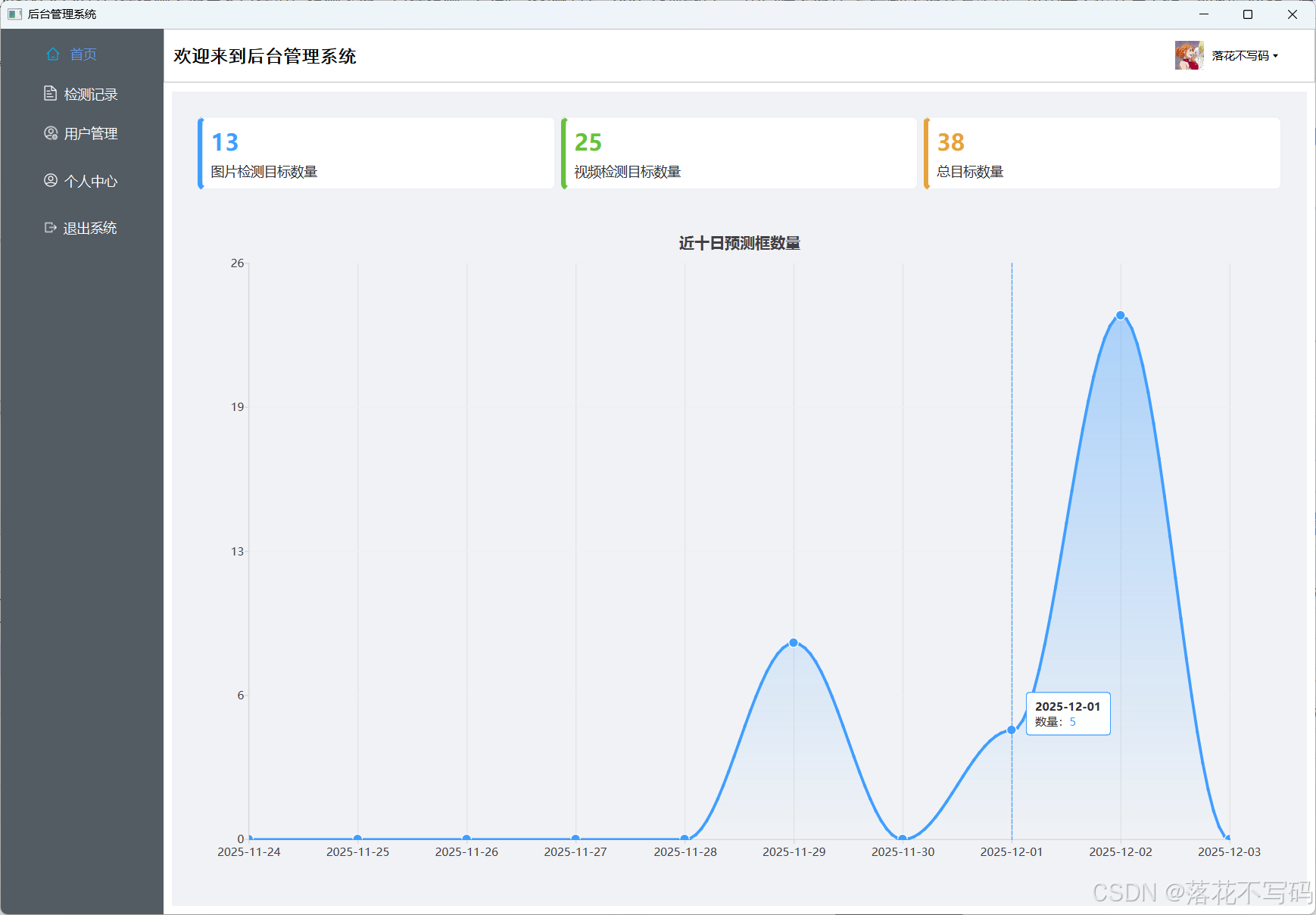 |
| 后台-用户管理模块 | 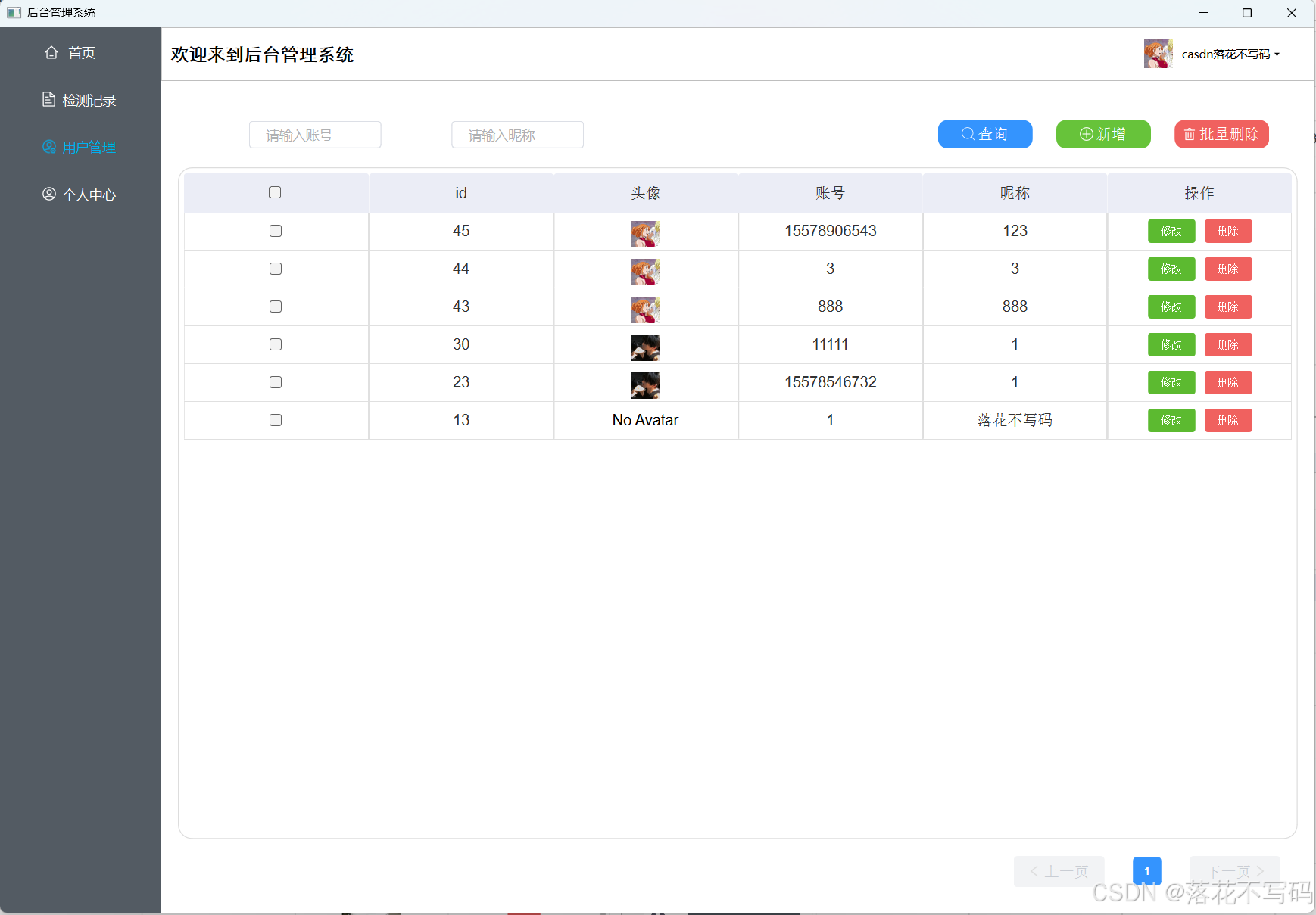 |
| 后台历史记录模块 | 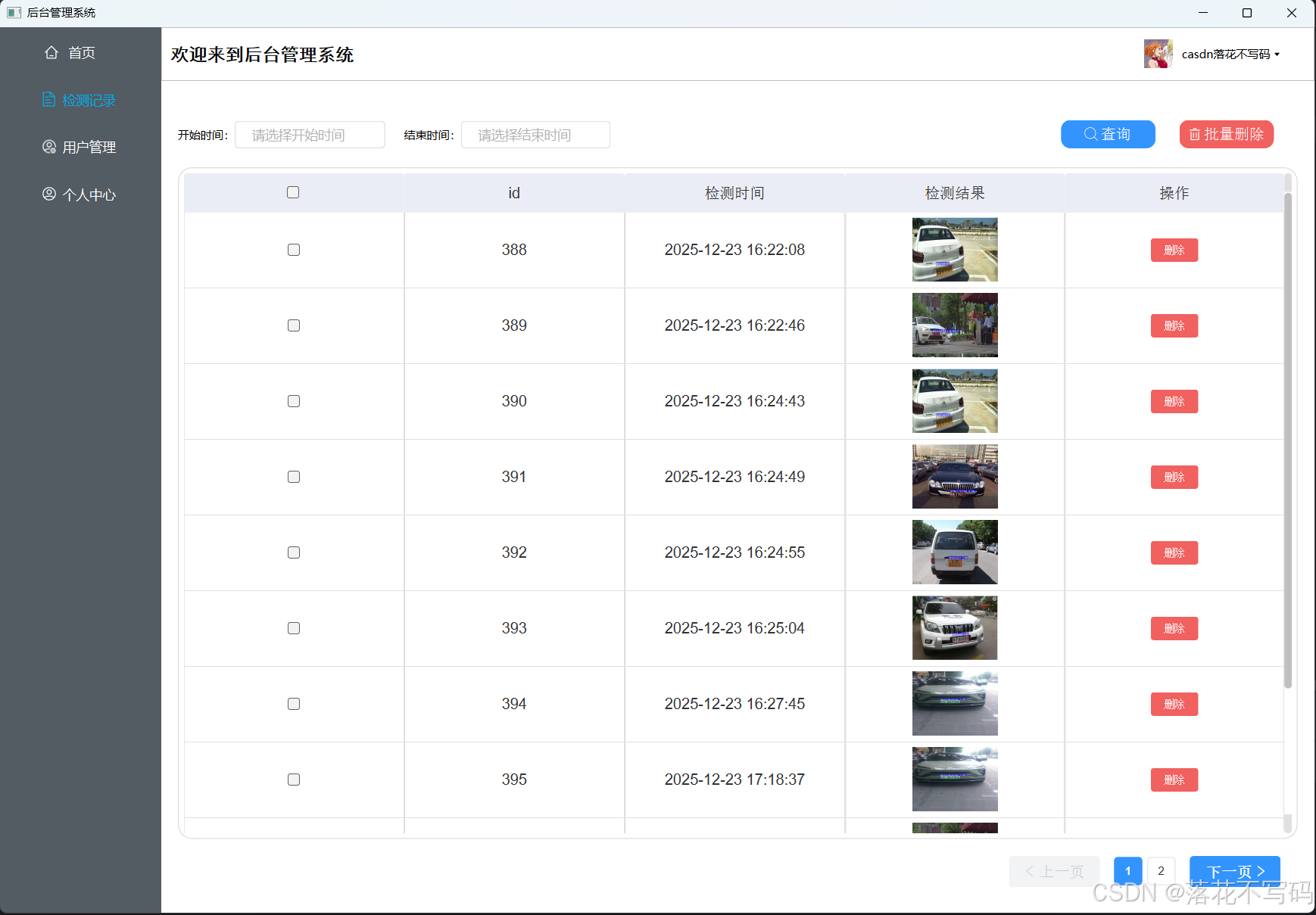 |
引言
车牌识别系统是智能交通、安防监控等领域的关键技术,结合深度学习方法可提升识别模型准确率。传统方法依赖手工特征提取,而OpenCV的车牌矫正技术进一步优化倾斜或变形车牌的预处理,为后续识别提供高质量输入,基于 YOLOv11的目标检测与 CNN 分类器的结合,能够实现端到端的车牌定位与字符识别。
一、相关技术
技术路线如下:
- 先利用YOLOv11算法定位车牌位置
- 由于有些车牌倾斜比较大,识别难度大大增加,那么就使用 cv2 进行边缘检测获得车牌区域坐标,并将车牌图形矫正
- 车牌经过矫正后,利用 CNN 网络进行车牌多标签端到端识别
实验结果,整体识别还好,对于倾斜角度和比较模糊的图片识别率不是很高,后续可以考虑将 CNN 算法更换为 LPRNet 算法,系统识别结果如下:
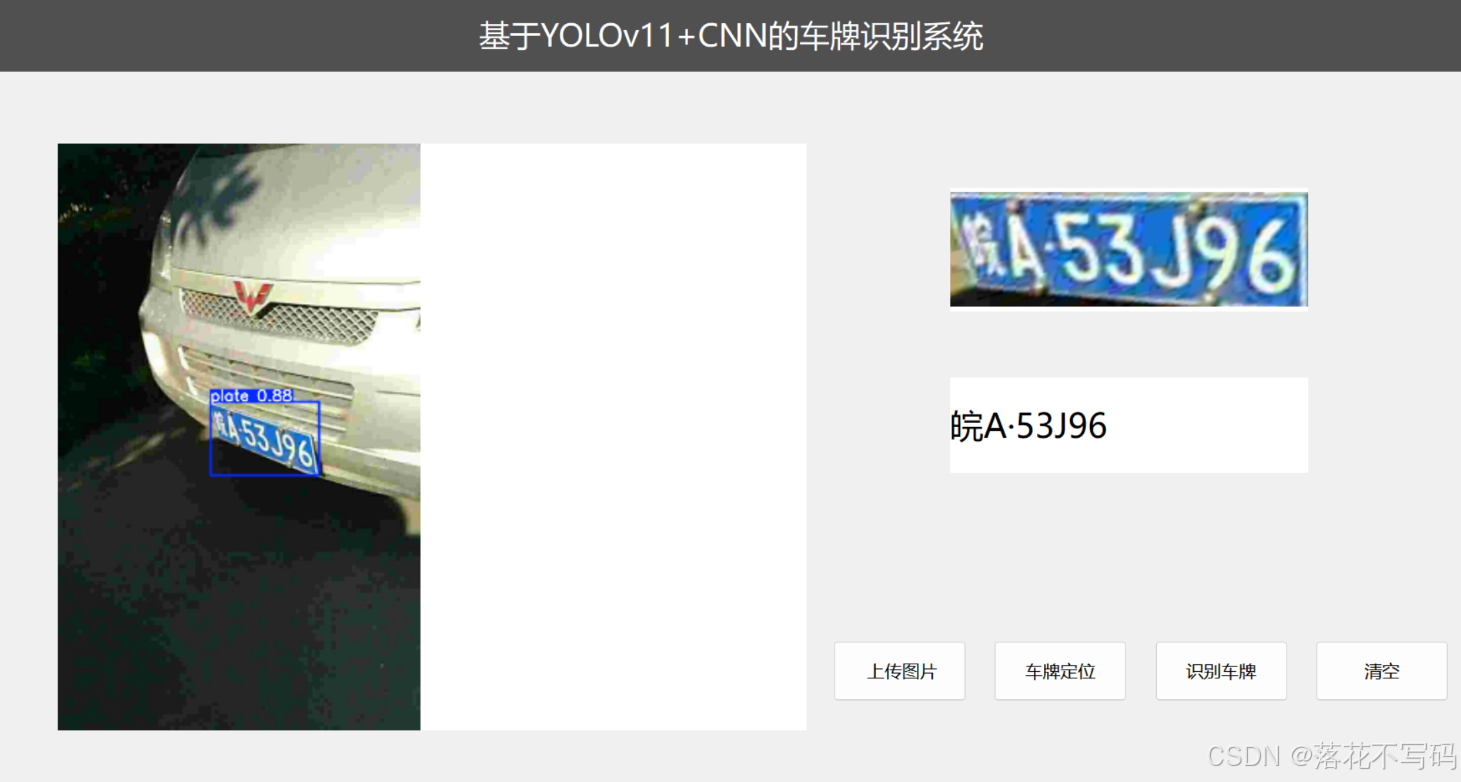
二、环境配置
1.YOLOv11环境配置
YOLO 系列环境配置讲过很多次了,其中YOLOv11/YOLOv10/YOLOv9/YOLOv8/YOLOv7/YOLOv5环境都是通用的,只需要安装一次就行,如果以前安装过,可以忽略本章的环境安装
🍀🍀 1.pytorch环境安装
手把手安装YOLO环境教程 1(非常推荐)链接参考链接: YOLO环境配置教程视频
手把手pytorch安装教程 2 链接参考链接: pytorch环境安装教程视频
🍀🍀2.其他依赖安装
安装 requirements.txt 文件的环境,需要注释掉下面两行,前面的步骤已经安装了,不注释的话会覆盖前面的会安装最新版本的 pytorch,所以注释掉

没有这个文件可以自己新建一个requirements.txt,然后把下面代码复制进去就好了


# Ultralytics requirements
# Example: pip install -r requirements.txt
# Base ----------------------------------------
matplotlib>=3.3.0
numpy==1.24.4 # pinned by Snyk to avoid a vulnerability
opencv-python>=4.6.0
pillow>=7.1.2
pyyaml>=5.3.1
requests>=2.23.0
scipy>=1.4.1
tqdm>=4.64.0
# Logging -------------------------------------
# tensorboard>=2.13.0
# dvclive>=2.12.0
# clearml
# comet
# Plotting ------------------------------------
pandas>=1.1.4
seaborn>=0.11.0
# Export --------------------------------------
# coremltools>=7.0 # CoreML export
# onnx>=1.12.0 # ONNX export
# onnxsim>=0.4.1 # ONNX simplifier
# nvidia-pyindex # TensorRT export
# nvidia-tensorrt # TensorRT export
# scikit-learn==0.19.2 # CoreML quantization
# tensorflow>=2.4.1 # TF exports (-cpu, -aarch64, -macos)
# tflite-support
# tensorflowjs>=3.9.0 # TF.js export
# openvino-dev>=2023.0 # OpenVINO export
# Extras --------------------------------------
psutil # system utilization
py-cpuinfo # display CPU info
thop>=0.1.1 # FLOPs computation
# ipython # interactive notebook
# albumentations>=1.0.3 # training augmentations
# pycocotools>=2.0.6 # COCO mAP
# roboflow
2.CNN环境配置
训练CNN模型需要安装单独安装 tensorflow,要么安装 gpu 版本或者 cpu 版本,下面给出各自的安装教程
如果安装 gpu 版本,电脑必须有英伟达显卡,并且先安装对应版本的 cuda 和 cudnn,安装教程看这篇文章: cuda和cudnn的安装教程(全网最详细保姆级教程),我安装的 cuda 版本是11.3,cudnn 版本是 8.2,建议安装跟我一样,避免报错
安装完 cuda 和 cudnn 之后,输入如下命令来安装 tensorflow gpu 版本 :
pip install tensorflow_gpu==2.7.0
测试tensorflow gpu 是否能用,代码如下:
# -*- coding: utf-8 -*-
"""
@Auth : 挂科边缘
@File :Test.py
@IDE :PyCharm
@Motto:学习新思想,争做新青年
@Email :[email protected]
"""
import tensorflow as tf
a = tf.test.is_built_with_cuda() # 判断CUDA是否可以用
b = tf.test.is_gpu_available(
cuda_only=False,
min_cuda_compute_capability=None
) # 判断GPU是否可以用
print(a)
print(b)
输出两个True证明能用,如下图所示

如果安装 cpu 版本就简单了,不用安装cuda和cudnn,直接输入下面命令安装就行,命令如下:
pip install tensorflow-cpu==2.7.0
3.PySide6安装
运行系统还需要安装PySide6
pip install PySide6==6.4.2
三、数据集准备和预处理
1.数据集准备
由于车牌数据集比较少,将采用开源数据集,本次实验均采用CCPD数据集,数据集详情参考链接:CCPD数据集参考
2.数据预处理
YOLOv11算法训练前需要做的工作:
训练前需要对数据集进行预处理,训练 YOLOv11 模型需要数据集进行标注,由于CCPD 数据集的特殊性,人家已经标注好了,只需要处理成 YOLO 格式即可,可以参考这篇文章进行处理:CCPD数据集处理成YOLO格式
CNN算法训练前需要做的工作:
CCPD 数据集我拿了 30000 张,CNN算法训练前需要裁剪车牌图片,裁剪后我们发现车牌有些是倾斜的,那么我们需要进行矫正,为了方便模型输入,将裁剪后的车牌进行统一大小为宽240,高80,处理好的训练样本如下所示:

对数据集进行字符统计如下图所示:
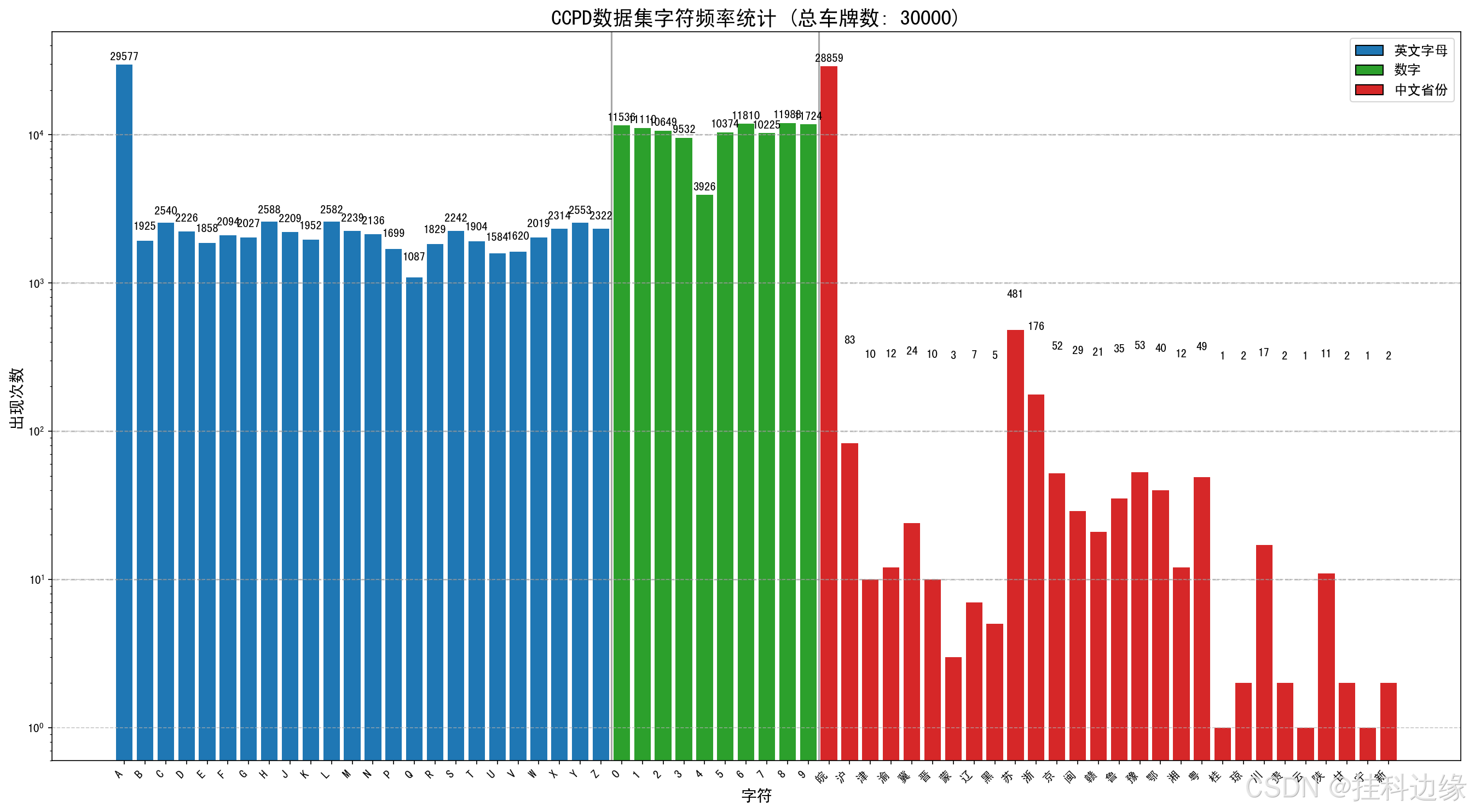
CCPD裁剪+矫正代码如下:
# -*- coding: utf-8 -*-
"""
@Auth : 挂科边缘
@File :ccpd裁剪.py
@IDE :PyCharm
@Motto:学习新思想,争做新青年
@Email :[email protected]
"""
import shutil
import numpy as np
import cv2
import os
words_list = [
"A", "B", "C", "D", "E",
"F", "G", "H", "J", "K",
"L", "M", "N", "P", "Q",
"R", "S", "T", "U", "V",
"W", "X", "Y", "Z", "0",
"1", "2", "3", "4", "5",
"6", "7", "8", "9"
]
con_list = [
"皖", "沪", "津", "渝", "冀",
"晋", "蒙", "辽", "吉", "黑",
"苏", "浙", "京", "闽", "赣",
"鲁", "豫", "鄂", "湘", "粤",
"桂", "琼", "川", "贵", "云",
"西", "陕", "甘", "青", "宁",
"新"
]
def order_points(pts):
rect = np.zeros((4, 2), dtype='float32')
s = pts.sum(axis=1) # 每行像素值进行相加;若axis=0,每列像素值相加
rect[0] = pts[np.argmin(s)] # top_left,返回s首个最小值索引,eg.[1,0,2,0],返回值为1
rect[2] = pts[np.argmax(s)] # bottom_left,返回s首个最大值索引,eg.[1,0,2,0],返回值为2
# 分别计算左上角和右下角的离散差值
diff = np.diff(pts, axis=1) # 第i+1列减第i列
rect[1] = pts[np.argmin(diff)]
rect[3] = pts[np.argmax(diff)]
return rect
def four_point_transform(image, pts):
rect = order_points(pts)
(tl, tr, br, bl) = rect
# 计算新图片的宽度值,选取水平差值的最大值
widthA = np.sqrt(((br[0] - bl[0]) ** 2) + ((br[1] - bl[1]) ** 2))
widthB = np.sqrt(((tr[0] - tl[0]) ** 2) + ((tr[1] - tl[1]) ** 2))
maxWidth = max(int(widthA), int(widthB))
# 计算新图片的高度值,选取垂直差值的最大值
heightA = np.sqrt(((tr[0] - br[0]) ** 2) + ((tr[1] - br[1]) ** 2))
heightB = np.sqrt(((tl[0] - bl[0]) ** 2) + ((tl[1] - bl[1]) ** 2))
maxHeight = max(int(heightA), int(heightB))
# 构建新图片的4个坐标点,左上角为原点
dst = np.array([
[0, 0],
[maxWidth - 1, 0],
[maxWidth - 1, maxHeight - 1],
[0, maxHeight - 1]], dtype="float32")
M = cv2.getPerspectiveTransform(rect, dst)
warped = cv2.warpPerspective(image, M, (maxWidth, maxHeight))
return warped
if __name__ == "__main__":
global points
total = []
input_dir = r'D:/Desktop/ccpd/ccpd/' # CCPD数据集路径,英文路径
output_dir = r'D:/Desktop/ccpd/new_ccpd' # 保存路径,英文路径
if os.path.exists(output_dir):
for filename in os.listdir(output_dir):
file_path = os.path.join(output_dir, filename)
try:
if os.path.isfile(file_path) or os.path.islink(file_path):
os.unlink(file_path)
elif os.path.isdir(file_path):
shutil.rmtree(file_path)
except Exception as e:
print(f'删除 {file_path} 失败. 原因: {e}')
else:
os.makedirs(output_dir, exist_ok=True)
for item in os.listdir(os.path.join(input_dir)):
img_path = os.path.join(input_dir, item)
img = cv2.imread(img_path)
# 解析文件名部分
parts = item.split('-')
if len(parts) < 7:
print(f"文件名格式错误: {item}")
continue
_, _, bbox, points_str, label_str, _, _ = parts
# 解析点坐标
points = points_str.split('_')
tmp = points
points = []
for p in tmp:
coords = p.split('&')
if len(coords) >= 2:
try:
points.append([int(coords[0]), int(coords[1])])
except ValueError:
print(f"坐标解析错误: {p} in {item}")
continue
# 解析车牌标签
label_parts = label_str.split('_')
if len(label_parts) < 7:
print(f"标签格式错误: {label_str} in {item}")
continue
try:
con = con_list[int(label_parts[0])]
words = [words_list[int(num)] for num in label_parts[1:7]]
plate_number = con + ''.join(words)
except (IndexError, ValueError) as e:
print(f"车牌解析错误: {e} in {item}")
continue
line = item + '\t' + plate_number + '\n'
total.append(line)
# 还原像素位置
if len(points) < 4:
print(f"点坐标不足: {item}")
continue
points_np = np.array(points, dtype=np.float32)
warped = four_point_transform(img, points_np)
warped = cv2.resize(warped, (240, 80), interpolation=cv2.INTER_CUBIC)
safe_plate_number = plate_number.encode('utf-8').decode('utf-8')
save_path = os.path.join(output_dir, safe_plate_number + '.jpg')
# 检查文件是否已存在,避免覆盖
counter = 1
while os.path.exists(save_path):
save_path = os.path.join(output_dir, f"{safe_plate_number}_{counter}.jpg")
counter += 1
success, encoded_image = cv2.imencode('.jpg', warped)
if success:
with open(save_path, 'wb') as f:
f.write(encoded_image.tobytes())
else:
print(f"图像编码失败: {save_path}")
代码需要修改的地方如下,填一下输入数据集路径和保存的路径即可,需要注意的是路径不能有中文

CCPD原始数据集我只拿30000张,需要 训练好的模型+完整源码+原始数据集+处理好的数据集 在文章末尾发送 车牌识别 即可获取
四、模型训练
1.YOLOv11模型训练
先训练YOLOv11车牌定位模型,因为 YOLO 系列训练讲过很多了,这里训练的话参考这篇文章即可:YOLOv11来了,使用YOLOv11训练自己的数据集和推理(附YOLOv11网络结构图)
2.CNN车牌识别训练
在第三章我们已经处理好数据集了,直接拿来训练即可
修改自己数据集路径即可
训练结果如下:
我画图出现乱码,在训练代码加上下面代码即可
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False # 正确显示负号
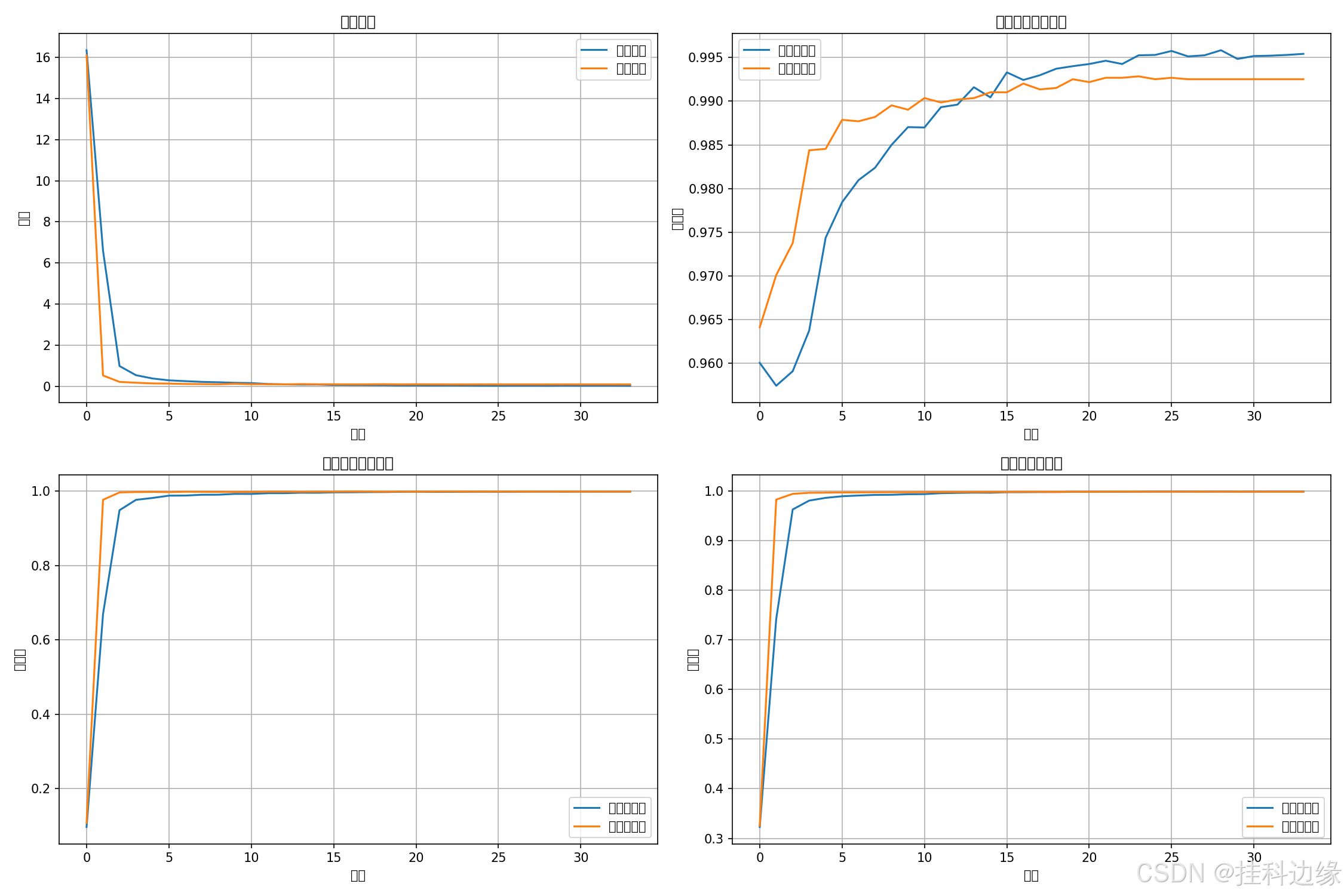
下面的图分别代表 模型损失、第一个字符准确率、第七个字符准确率、平均字符准确率
四、系统设计与实现
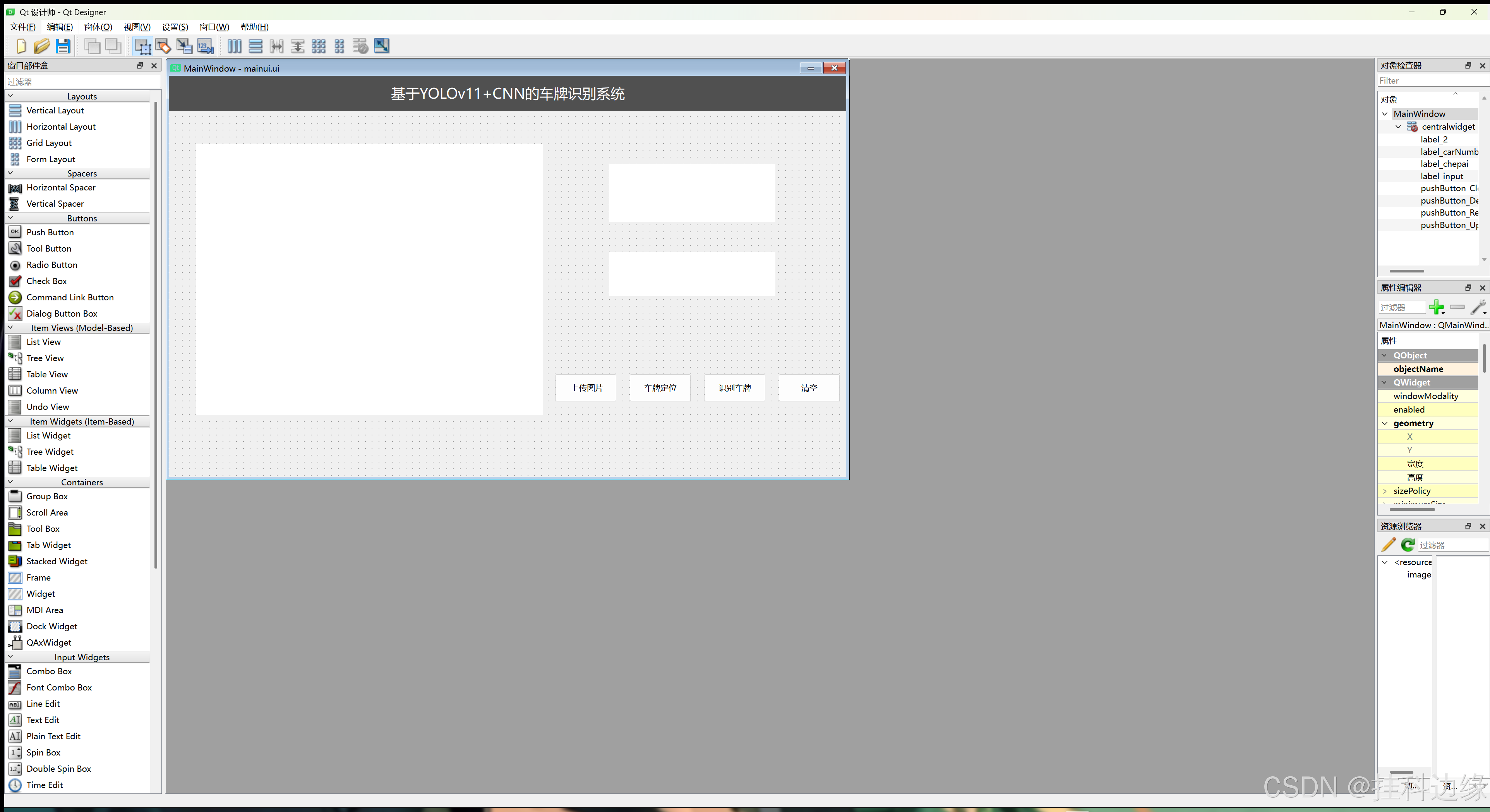
通过Qt Desiger设计好界面,如下图所示
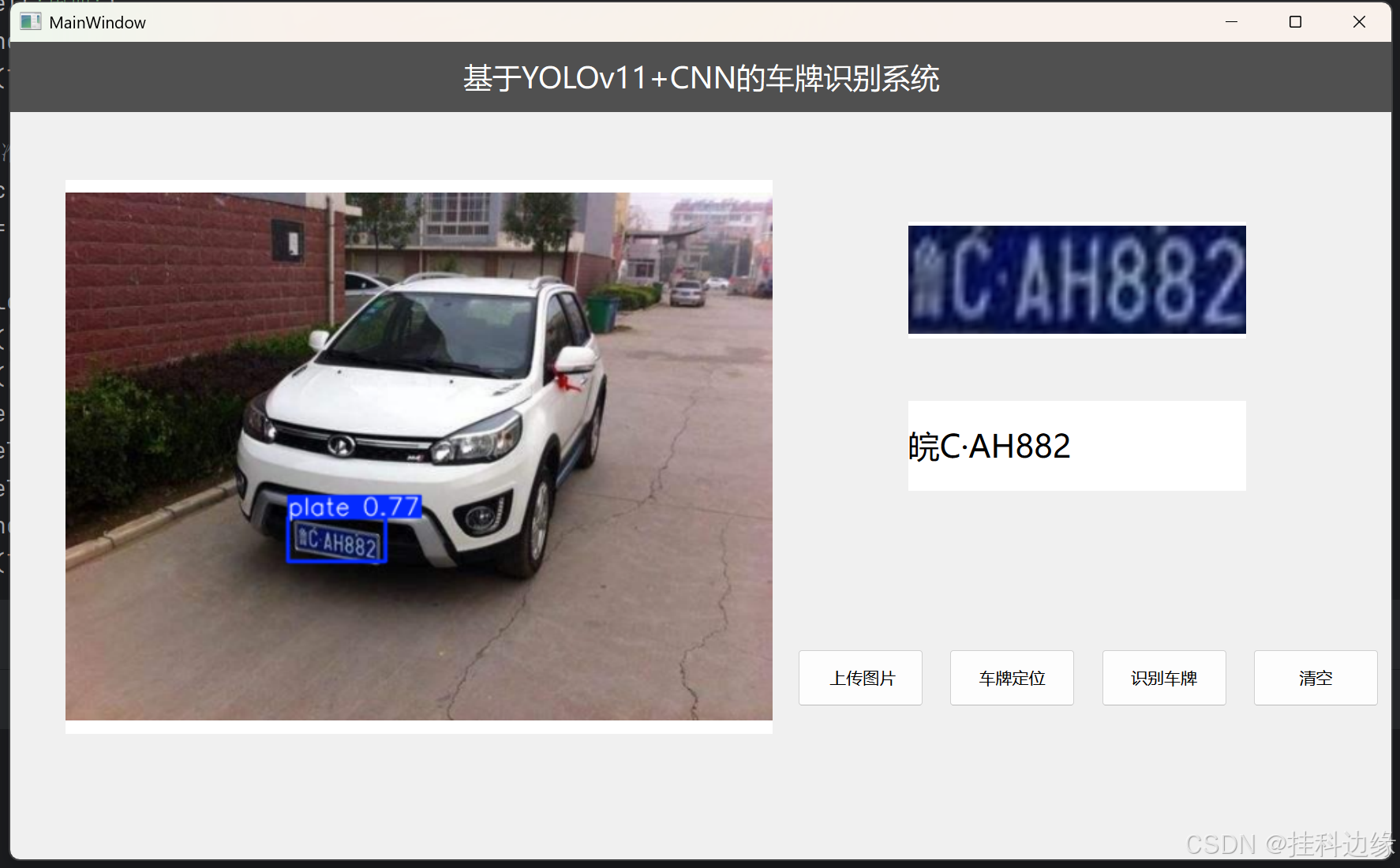
之后实现后端代码即可,最终运行MainUI.py结果如下:
五、总结和源码获取
- 当前系统的优势与不足:倾斜角度较大和模糊的图片识别效果不佳
- 未来改进方向:更换更换的车牌识别模型,如 LprNet、PaddleOCR 等模型
CCPD原始数据集我只拿30000张,需要 训练好的模型+完整源码+原始数据集+处理好的数据集 在文章末尾发送 车牌识别 即可获取
转载自CSDN-专业IT技术社区
原文链接:https://blog.csdn.net/weixin_44779079/article/details/149123571

