
话本小说网通用爬虫 v3.0 发布 - GUI界面全面升级,更智能、更易用!
一、前言
距离上一版本发布已经有一段时间了,这次带来了话本小说网通用爬虫 v3.0的重大更新!完全重写了GUI界面,优化了布局,新增了大量实用功能。无论你是技术小白还是爬虫爱好者,都能轻松上手!
二、更新亮点
✨ 全新特性
- URL智能补全 - 再也不用纠结输入格式
- 横向布局优化 - 告别纵向滚动,一屏全览
- 作者信息展示 - 开源免费,拒绝贩卖
- 常见问题解答 - 内置FAQ,即查即用
- 免责声明 - 合法使用,尊重版权
- 日志过滤增强 - 级别+关键词双重过滤
- 章节自动去重 - 解决重复章节问题
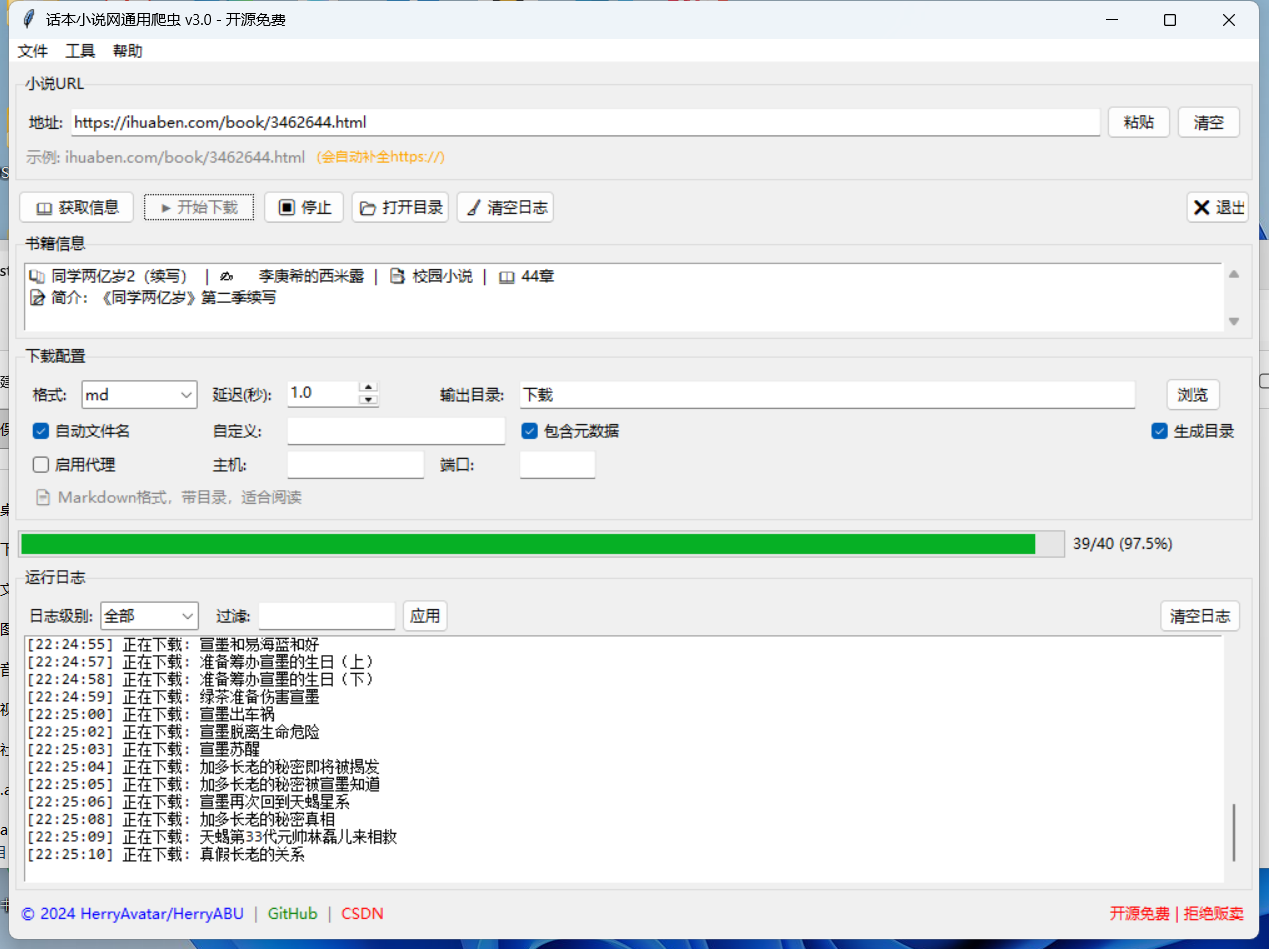
三、界面预览
┌─────────────────────────────────────────────────┐
│ 文件 工具 帮助 │
├─────────────────────────────────────────────────┤
│ 小说URL [地址框........................] [粘贴][清空] │
│ 示例: ihuaben.com/book/3462644.html (会自动补全) │
├─────────────────────────────────────────────────┤
│ [获取信息] [开始下载] [停止] [打开目录] [清空日志] [退出] │
├─────────────────────────────────────────────────┤
│ 书籍信息:书名 | 作者 | 分类 | 章节数 │
├─────────────────────────────────────────────────┤
│ 格式:[md▼] 延迟:[1.0▼] 输出目录:[下载...] [浏览] │
│ [✓]自动文件名 自定义:[______] [✓]元数据 [✓]目录 │
│ [ ]启用代理 主机:[______] 端口:[____] │
│ 📄 Markdown格式,带目录,适合阅读 │
├─────────────────────────────────────────────────┤
│ [████████░░░░░░░░░░░░] 12/40 (30%) │
├─────────────────────────────────────────────────┤
│ 日志级别:[全部▼] 过滤:[______] [应用] [清空日志] │
│ [12:30:45] 正在下载: 第1章 重聚 │
│ [12:30:46] 下载成功 │
├─────────────────────────────────────────────────┤
│ © 2024 HerryAvatar/HerryABU | GitHub | CSDN │
│ 开源免费 │
└─────────────────────────────────────────────────┘
四、核心功能详解
1. URL智能补全
再也不用纠结输入格式了,程序会自动处理:
# 输入这些格式都能自动补全
ihuaben.com/book/3462644.html
www.ihuaben.com/book/3462644.html
https://ihuaben.com/book/3462644.html
# 都会自动变成
https://www.ihuaben.com/book/3462644.html
2. 四种输出格式
| 格式 | 说明 | 适用场景 |
|---|---|---|
| MD | Markdown带目录 | 阅读、排版 |
| TXT | 纯文本 | 通用格式 |
| 独立章节 | 每章一个文件 | 管理方便 |
| JSON | 数据结构化 | 二次开发 |
3. 智能去重
针对部分网站存在的重复章节问题,程序会自动去重:
# 下载时会提示
找到 43 个章节(已去重)
# 实际保存的是去重后的40章
4. 日志过滤系统
- 级别过滤:信息/成功/警告/错误
- 关键词过滤:搜索特定内容
- 实时查看:下载过程一目了然
五、常见问题解答
Q: 章节数获取的与下载的不一样?
A: 已经自动去除重复章节,部分网站可能存在重复列表,程序会自动去重,保证最终文件不重复。
Q: 下载速度太慢怎么办?
A: 可以适当调低延迟时间,但建议保持在0.5秒以上,避免请求过快导致IP被封。
Q: 是否收费?
A: 这是开源免费的软件!如果你是从任何渠道购买的,说明你上当受骗了!欢迎到GitHub免费下载。
Q: 支持其他网站吗?
A: 目前仅支持话本小说网(www.ihuaben.com),后续可能会根据需求扩展。
Q: 下载的文件在哪里?
A: 默认保存在当前目录下的"下载"文件夹,也可以自定义输出目录。
Q: 遇到错误怎么办?
A: 可以尝试:
- 检查网络连接
- 调高延迟时间
- 启用代理(如果需要)
- 在GitHub提交issue
六、安装使用
环境要求
- Python 3.6+
- 只需安装requests库(tkinter为Python自带)
安装步骤
源码使用
# 1. 安装依赖
pip install requests beautifulsoup4
# 2. 下载代码
# 从GitHub下载或直接复制下方完整代码
#或直接复制粘贴下面的代码
# 3. 运行程序
python huaben_spider_v3.py
exe直装版
csdn有,见上
快速上手
- 输入URL:粘贴小说目录页链接
- 获取信息:点击"获取信息"查看书籍详情
- 选择格式:MD/TXT/独立章节/JSON
- 开始下载:点击"开始下载",实时查看进度
- 完成:自动提示打开文件夹
七、完整代码
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
话本小说网通用爬虫 - GUI图形界面版
支持任何小说作品的爬取,可视化操作
"""
import tkinter as tk
from tkinter import ttk, filedialog, messagebox, scrolledtext
import threading
import requests
from bs4 import BeautifulSoup
import time
import re
import os
import json
from urllib.parse import urljoin, urlparse
from datetime import datetime
import queue
import webbrowser
class HuabenSpiderGUI:
"""话本小说网爬虫GUI - 最终版"""
def __init__(self, root):
self.root = root
self.root.title("话本小说网通用爬虫 v3.0 - 开源免费")
self.root.geometry("1000x700") # 增加高度以容纳底部信息
self.root.minsize(900, 650)
# 设置图标(如果有的话)
try:
self.root.iconbitmap("spider.ico")
except:
pass
# 变量
self.book_url = tk.StringVar()
self.output_format = tk.StringVar(value="md")
self.delay = tk.DoubleVar(value=1.0)
self.output_dir = tk.StringVar(value="下载")
self.auto_filename = tk.BooleanVar(value=True)
self.custom_filename = tk.StringVar()
self.include_meta = tk.BooleanVar(value=True)
self.include_toc = tk.BooleanVar(value=True)
self.proxy_enabled = tk.BooleanVar(value=False)
self.proxy_host = tk.StringVar()
self.proxy_port = tk.StringVar()
# 数据
self.book_info = {}
self.chapters = []
self.is_running = False
self.current_chapter = 0
self.total_chapters = 0
self.log_queue = queue.Queue()
# 创建UI
self.create_menu()
self.create_widgets()
# 启动日志处理
self.process_log_queue()
# 绑定URL输入框的事件
self.root.bind('<Control-v>', lambda e: self.paste_url())
# 绑定关闭事件
self.root.protocol("WM_DELETE_WINDOW", self.on_closing)
def create_menu(self):
"""创建菜单栏"""
menubar = tk.Menu(self.root)
# 文件菜单
file_menu = tk.Menu(menubar, tearoff=0)
file_menu.add_command(label="打开URL文件", command=self.load_urls_from_file)
file_menu.add_command(label="保存配置", command=self.save_config)
file_menu.add_command(label="加载配置", command=self.load_config)
file_menu.add_separator()
file_menu.add_command(label="退出", command=self.on_closing)
menubar.add_cascade(label="文件", menu=file_menu)
# 工具菜单
tools_menu = tk.Menu(menubar, tearoff=0)
tools_menu.add_command(label="清空日志", command=self.clear_log)
tools_menu.add_command(label="打开下载目录", command=self.open_download_dir)
tools_menu.add_separator()
tools_menu.add_command(label="检查更新", command=self.check_update)
menubar.add_cascade(label="工具", menu=tools_menu)
# 帮助菜单
help_menu = tk.Menu(menubar, tearoff=0)
help_menu.add_command(label="使用说明", command=self.show_help)
help_menu.add_command(label="常见问题", command=self.show_faq)
help_menu.add_command(label="免责声明", command=self.show_disclaimer)
help_menu.add_separator()
help_menu.add_command(label="关于作者", command=self.show_about)
help_menu.add_command(label="访问GitHub", command=lambda: webbrowser.open("https://github.com/HerryABU/"))
help_menu.add_command(label="访问CSDN", command=lambda: webbrowser.open("https://blog.csdn.net/Herryfyh"))
menubar.add_cascade(label="帮助", menu=help_menu)
self.root.config(menu=menubar)
def create_widgets(self):
"""创建主界面"""
# 主框架
main_frame = ttk.Frame(self.root, padding="5")
main_frame.pack(fill=tk.BOTH, expand=True)
# ===== 顶部:URL输入和操作 =====
top_frame = ttk.LabelFrame(main_frame, text="小说URL", padding="5")
top_frame.pack(fill=tk.X, pady=2)
# URL输入行
url_frame = ttk.Frame(top_frame)
url_frame.pack(fill=tk.X, pady=2)
ttk.Label(url_frame, text="地址:").pack(side=tk.LEFT, padx=2)
url_entry = ttk.Entry(url_frame, textvariable=self.book_url)
url_entry.pack(side=tk.LEFT, fill=tk.X, expand=True, padx=2)
ttk.Button(url_frame, text="粘贴", width=6,
command=self.paste_url).pack(side=tk.LEFT, padx=2)
ttk.Button(url_frame, text="清空", width=6,
command=lambda: self.book_url.set("")).pack(side=tk.LEFT, padx=2)
# 示例URL
example_frame = ttk.Frame(top_frame)
example_frame.pack(fill=tk.X, pady=2)
ttk.Label(example_frame, text="示例: ihuaben.com/book/3462644.html",
foreground="gray").pack(side=tk.LEFT)
ttk.Label(example_frame, text="(会自动补全https://)",
foreground="orange", font=("微软雅黑", 8)).pack(side=tk.LEFT, padx=5)
# 操作按钮行
btn_frame = ttk.Frame(main_frame)
btn_frame.pack(fill=tk.X, pady=5)
ttk.Button(btn_frame, text="📖 获取信息", width=12,
command=self.fetch_book_info).pack(side=tk.LEFT, padx=2)
self.start_button = ttk.Button(btn_frame, text="▶ 开始下载", width=12,
command=self.start_download)
self.start_button.pack(side=tk.LEFT, padx=2)
self.stop_button = ttk.Button(btn_frame, text="⏹ 停止", width=8,
command=self.stop_download, state=tk.DISABLED)
self.stop_button.pack(side=tk.LEFT, padx=2)
ttk.Button(btn_frame, text="📂 打开目录", width=10,
command=self.open_download_dir).pack(side=tk.LEFT, padx=2)
ttk.Button(btn_frame, text="🧹 清空日志", width=10,
command=self.clear_log).pack(side=tk.LEFT, padx=2)
ttk.Button(btn_frame, text="❌ 退出", width=6,
command=self.on_closing).pack(side=tk.RIGHT, padx=2)
# ===== 书籍信息 =====
info_frame = ttk.LabelFrame(main_frame, text="书籍信息", padding="5")
info_frame.pack(fill=tk.X, pady=2)
self.info_text = tk.Text(info_frame, height=3, wrap=tk.WORD, font=("微软雅黑", 9))
self.info_text.pack(side=tk.LEFT, fill=tk.BOTH, expand=True)
info_scrollbar = ttk.Scrollbar(info_frame, orient=tk.VERTICAL, command=self.info_text.yview)
info_scrollbar.pack(side=tk.RIGHT, fill=tk.Y)
self.info_text.config(yscrollcommand=info_scrollbar.set)
# 初始信息
self.update_info_display({})
# ===== 配置选项 =====
config_frame = ttk.LabelFrame(main_frame, text="下载配置", padding="5")
config_frame.pack(fill=tk.X, pady=2)
# 第1行:格式、延迟、输出目录
ttk.Label(config_frame, text="格式:").grid(row=0, column=0, sticky=tk.W, padx=5, pady=2)
format_combo = ttk.Combobox(config_frame, textvariable=self.output_format,
values=["md", "txt", "separate", "json"],
state="readonly", width=10)
format_combo.grid(row=0, column=1, sticky=tk.W, padx=5, pady=2)
ttk.Label(config_frame, text="延迟(秒):").grid(row=0, column=2, sticky=tk.W, padx=5, pady=2)
delay_spin = ttk.Spinbox(config_frame, from_=0.1, to=5.0, increment=0.1,
textvariable=self.delay, width=8)
delay_spin.grid(row=0, column=3, sticky=tk.W, padx=5, pady=2)
ttk.Label(config_frame, text="输出目录:").grid(row=0, column=4, sticky=tk.W, padx=5, pady=2)
dir_entry = ttk.Entry(config_frame, textvariable=self.output_dir, width=25)
dir_entry.grid(row=0, column=5, sticky=tk.W+tk.E, padx=5, pady=2)
ttk.Button(config_frame, text="浏览", width=5,
command=self.select_output_dir).grid(row=0, column=6, padx=2, pady=2)
# 第2行:文件名选项、元数据、目录选项
ttk.Checkbutton(config_frame, text="自动文件名",
variable=self.auto_filename).grid(row=1, column=0, columnspan=2, sticky=tk.W, padx=5, pady=2)
ttk.Label(config_frame, text="自定义:").grid(row=1, column=2, sticky=tk.W, padx=5, pady=2)
name_entry = ttk.Entry(config_frame, textvariable=self.custom_filename, width=20)
name_entry.grid(row=1, column=3, columnspan=2, sticky=tk.W+tk.E, padx=5, pady=2)
ttk.Checkbutton(config_frame, text="包含元数据",
variable=self.include_meta).grid(row=1, column=5, sticky=tk.W, padx=5, pady=2)
ttk.Checkbutton(config_frame, text="生成目录",
variable=self.include_toc).grid(row=1, column=6, sticky=tk.W, padx=5, pady=2)
# 第3行:代理设置
proxy_check = ttk.Checkbutton(config_frame, text="启用代理",
variable=self.proxy_enabled)
proxy_check.grid(row=2, column=0, columnspan=2, sticky=tk.W, padx=5, pady=2)
ttk.Label(config_frame, text="主机:").grid(row=2, column=2, sticky=tk.W, padx=5, pady=2)
proxy_host_entry = ttk.Entry(config_frame, textvariable=self.proxy_host, width=15)
proxy_host_entry.grid(row=2, column=3, sticky=tk.W, padx=5, pady=2)
ttk.Label(config_frame, text="端口:").grid(row=2, column=4, sticky=tk.W, padx=5, pady=2)
proxy_port_entry = ttk.Entry(config_frame, textvariable=self.proxy_port, width=8)
proxy_port_entry.grid(row=2, column=5, sticky=tk.W, padx=5, pady=2)
# 格式说明
self.format_desc = ttk.Label(config_frame, text="", foreground="gray")
self.format_desc.grid(row=3, column=0, columnspan=7, sticky=tk.W, padx=5, pady=2)
def update_format_desc(*args):
desc = {
"md": "📄 Markdown格式,带目录,适合阅读",
"txt": "📃 纯文本格式,通用性强",
"separate": "📁 每章一个文件,方便管理",
"json": "📊 JSON数据格式,包含完整信息"
}.get(self.output_format.get(), "")
self.format_desc.config(text=desc)
self.output_format.trace('w', update_format_desc)
update_format_desc()
# 设置网格权重
config_frame.columnconfigure(5, weight=1)
# ===== 进度条 =====
progress_frame = ttk.Frame(main_frame)
progress_frame.pack(fill=tk.X, pady=5)
self.progress_bar = ttk.Progressbar(progress_frame, mode='determinate')
self.progress_bar.pack(side=tk.LEFT, fill=tk.X, expand=True, padx=2)
self.status_label = ttk.Label(progress_frame, text="就绪", width=20)
self.status_label.pack(side=tk.RIGHT, padx=2)
# ===== 日志区域 =====
log_frame = ttk.LabelFrame(main_frame, text="运行日志", padding="5")
log_frame.pack(fill=tk.BOTH, expand=True, pady=2)
# 日志工具栏
log_toolbar = ttk.Frame(log_frame)
log_toolbar.pack(fill=tk.X, pady=2)
ttk.Label(log_toolbar, text="日志级别:").pack(side=tk.LEFT, padx=2)
self.log_level = tk.StringVar(value="全部")
log_level_combo = ttk.Combobox(log_toolbar, textvariable=self.log_level,
values=["全部", "信息", "成功", "警告", "错误"],
state="readonly", width=8)
log_level_combo.pack(side=tk.LEFT, padx=2)
ttk.Label(log_toolbar, text="过滤:").pack(side=tk.LEFT, padx=(10, 2))
self.log_filter = tk.StringVar()
filter_entry = ttk.Entry(log_toolbar, textvariable=self.log_filter, width=15)
filter_entry.pack(side=tk.LEFT, padx=2)
ttk.Button(log_toolbar, text="应用", width=4,
command=lambda: None).pack(side=tk.LEFT, padx=2)
ttk.Button(log_toolbar, text="清空日志", width=8,
command=self.clear_log).pack(side=tk.RIGHT, padx=2)
# 日志文本框
self.log_text = scrolledtext.ScrolledText(log_frame, height=10, wrap=tk.WORD,
font=("Consolas", 9))
self.log_text.pack(fill=tk.BOTH, expand=True)
# 配置日志标签
self.log_text.tag_config("info", foreground="black")
self.log_text.tag_config("success", foreground="green")
self.log_text.tag_config("warning", foreground="orange")
self.log_text.tag_config("error", foreground="red")
self.log_text.tag_config("title", foreground="blue", font=("Consolas", 10, "bold"))
# ===== 底部信息栏 =====
bottom_frame = ttk.Frame(main_frame)
bottom_frame.pack(fill=tk.X, pady=5)
# 作者信息
author_frame = ttk.Frame(bottom_frame)
author_frame.pack(side=tk.LEFT, fill=tk.X, expand=True)
ttk.Label(author_frame, text="© 2024 HerryAvatar/HerryABU",
foreground="blue", cursor="hand2").pack(side=tk.LEFT, padx=2)
ttk.Label(author_frame, text="|", foreground="gray").pack(side=tk.LEFT, padx=2)
github_label = ttk.Label(author_frame, text="GitHub",
foreground="green", cursor="hand2")
github_label.pack(side=tk.LEFT, padx=2)
github_label.bind("<Button-1>", lambda e: webbrowser.open("https://github.com/HerryABU/"))
ttk.Label(author_frame, text="|", foreground="gray").pack(side=tk.LEFT, padx=2)
csdn_label = ttk.Label(author_frame, text="CSDN",
foreground="red", cursor="hand2")
csdn_label.pack(side=tk.LEFT, padx=2)
csdn_label.bind("<Button-1>", lambda e: webbrowser.open("https://blog.csdn.net/Herryfyh"))
# 开源信息
ttk.Label(bottom_frame, text="开源免费 | 拒绝贩卖",
foreground="red").pack(side=tk.RIGHT, padx=5)
def normalize_url(self, url):
"""规范化URL,自动补全https://"""
url = url.strip()
if not url:
return url
# 如果已经是完整URL,直接返回
if url.startswith(('http://', 'https://')):
return url
# 如果以www开头,补全https://
if url.startswith('www.'):
return f"https://{url}"
# 如果以ihuaben.com开头,补全https://www.
if url.startswith('ihuaben.com'):
return f"https://www.{url}"
# 其他情况,尝试补全https://www.ihuaben.com/
if 'ihuaben.com' in url:
return f"https://{url}" if not url.startswith('http') else url
return url
def paste_url(self):
"""粘贴并规范化URL"""
try:
clipboard = self.root.clipboard_get()
normalized = self.normalize_url(clipboard)
self.book_url.set(normalized)
except:
pass
def update_info_display(self, info):
"""更新书籍信息显示"""
self.info_text.delete(1.0, tk.END)
if not info:
self.info_text.insert(tk.END, "暂无书籍信息,请输入URL后点击'获取信息'")
return
text = f"📚 {info.get('book_name', '未知')} | ✍️ {info.get('author', '未知')} | 📑 {info.get('category', '未知')} | 📖 {info.get('total_chapters', 0)}章"
if info.get('description'):
text += f"\n📝 {info['description'][:100]}"
if len(info['description']) > 100:
text += "..."
self.info_text.insert(tk.END, text)
def select_output_dir(self):
"""选择输出目录"""
directory = filedialog.askdirectory(title="选择输出目录")
if directory:
self.output_dir.set(directory)
def load_urls_from_file(self):
"""从文件加载URL列表"""
filename = filedialog.askopenfilename(
title="选择URL文件",
filetypes=[("文本文件", "*.txt"), ("所有文件", "*.*")]
)
if filename:
try:
with open(filename, 'r', encoding='utf-8') as f:
urls = [line.strip() for line in f if line.strip()]
if urls:
# 规范化第一个URL
normalized = self.normalize_url(urls[0])
self.book_url.set(normalized)
self.log(f"已加载 {len(urls)} 个URL,使用第一个", "info")
else:
messagebox.showwarning("警告", "文件中没有找到URL")
except Exception as e:
messagebox.showerror("错误", f"读取文件失败: {e}")
def save_config(self):
"""保存配置到文件"""
filename = filedialog.asksaveasfilename(
title="保存配置",
defaultextension=".json",
filetypes=[("JSON文件", "*.json")]
)
if filename:
config = {
'output_format': self.output_format.get(),
'delay': self.delay.get(),
'output_dir': self.output_dir.get(),
'auto_filename': self.auto_filename.get(),
'custom_filename': self.custom_filename.get(),
'include_meta': self.include_meta.get(),
'include_toc': self.include_toc.get(),
'proxy_enabled': self.proxy_enabled.get(),
'proxy_host': self.proxy_host.get(),
'proxy_port': self.proxy_port.get()
}
try:
with open(filename, 'w', encoding='utf-8') as f:
json.dump(config, f, ensure_ascii=False, indent=2)
messagebox.showinfo("成功", "配置已保存")
except Exception as e:
messagebox.showerror("错误", f"保存失败: {e}")
def load_config(self):
"""从文件加载配置"""
filename = filedialog.askopenfilename(
title="加载配置",
filetypes=[("JSON文件", "*.json")]
)
if filename:
try:
with open(filename, 'r', encoding='utf-8') as f:
config = json.load(f)
self.output_format.set(config.get('output_format', 'md'))
self.delay.set(config.get('delay', 1.0))
self.output_dir.set(config.get('output_dir', '下载'))
self.auto_filename.set(config.get('auto_filename', True))
self.custom_filename.set(config.get('custom_filename', ''))
self.include_meta.set(config.get('include_meta', True))
self.include_toc.set(config.get('include_toc', True))
self.proxy_enabled.set(config.get('proxy_enabled', False))
self.proxy_host.set(config.get('proxy_host', ''))
self.proxy_port.set(config.get('proxy_port', ''))
messagebox.showinfo("成功", "配置已加载")
except Exception as e:
messagebox.showerror("错误", f"加载失败: {e}")
def fetch_book_info(self):
"""获取书籍信息"""
url = self.normalize_url(self.book_url.get().strip())
if not url:
messagebox.showwarning("警告", "请输入小说URL")
return
self.book_url.set(url) # 更新为规范化后的URL
thread = threading.Thread(target=self._fetch_book_info_thread, args=(url,))
thread.daemon = True
thread.start()
def _fetch_book_info_thread(self, url):
"""获取书籍信息的线程函数"""
self.log("正在获取书籍信息...", "info")
try:
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'}
proxies = None
if self.proxy_enabled.get() and self.proxy_host.get() and self.proxy_port.get():
proxies = {
'http': f'http://{self.proxy_host.get()}:{self.proxy_port.get()}',
'https': f'http://{self.proxy_host.get()}:{self.proxy_port.get()}'
}
response = requests.get(url, headers=headers, proxies=proxies, timeout=10)
response.encoding = 'utf-8'
soup = BeautifulSoup(response.text, 'html.parser')
# 提取信息
book_info = {}
# 书名
title_elem = soup.find('h1', class_='text-danger')
if title_elem:
book_info['book_name'] = title_elem.text.strip()
else:
meta = soup.find('meta', attrs={'property': 'og:novel:book_name'})
if meta:
book_info['book_name'] = meta.get('content', '').strip()
# 作者
author_elem = soup.find('a', href=re.compile(r'/user/\d+'))
if author_elem:
book_info['author'] = author_elem.text.strip()
else:
meta = soup.find('meta', attrs={'property': 'og:novel:author'})
if meta:
book_info['author'] = meta.get('content', '').strip()
# 分类
meta = soup.find('meta', attrs={'property': 'og:novel:category'})
if meta:
book_info['category'] = meta.get('content', '').strip()
# 简介
desc_elem = soup.find('div', class_='aboutbook')
if desc_elem:
book_info['description'] = desc_elem.text.strip()
else:
meta = soup.find('meta', attrs={'name': 'description'})
if meta:
book_info['description'] = meta.get('content', '').strip()
# 统计章节数
chapter_items = soup.find_all('span', class_='chapterTitle')
book_info['total_chapters'] = len(chapter_items)
self.book_info = book_info
self.root.after(0, self.update_info_display, book_info)
self.log(f"获取成功: {book_info.get('book_name', '未知')} - {book_info.get('total_chapters', 0)}章", "success")
except Exception as e:
self.root.after(0, messagebox.showerror, "错误", f"获取失败: {e}")
self.log(f"获取失败: {e}", "error")
def start_download(self):
"""开始下载"""
url = self.normalize_url(self.book_url.get().strip())
if not url:
messagebox.showwarning("警告", "请输入小说URL")
return
self.book_url.set(url) # 更新为规范化后的URL
# 准备下载目录
download_dir = self.output_dir.get()
if not os.path.exists(download_dir):
try:
os.makedirs(download_dir)
except:
download_dir = "下载"
if not os.path.exists(download_dir):
os.makedirs(download_dir)
self.output_dir.set(download_dir)
self.start_button.config(state=tk.DISABLED)
self.stop_button.config(state=tk.NORMAL)
self.is_running = True
thread = threading.Thread(target=self._download_thread, args=(url, download_dir))
thread.daemon = True
thread.start()
def _download_thread(self, url, download_dir):
"""下载线程函数"""
self.log("=" * 60, "title")
self.log("开始下载任务", "title")
self.log(f"URL: {url}", "info")
self.log(f"输出目录: {download_dir}", "info")
self.log("-" * 40, "info")
try:
spider = GUIHuabenSpider(
url=url,
output_format=self.output_format.get(),
delay=self.delay.get(),
download_dir=download_dir,
auto_filename=self.auto_filename.get(),
custom_filename=self.custom_filename.get(),
include_meta=self.include_meta.get(),
include_toc=self.include_toc.get(),
proxy_enabled=self.proxy_enabled.get(),
proxy_host=self.proxy_host.get(),
proxy_port=self.proxy_port.get(),
gui=self
)
result = spider.run()
if result:
self.log("=" * 60, "success")
self.log("下载完成!", "success")
self.log(f"文件保存在: {result}", "success")
self.root.after(0, lambda: self.ask_open_dir(result))
else:
self.log("下载失败或已停止", "error")
except Exception as e:
self.log(f"下载异常: {e}", "error")
finally:
self.is_running = False
self.root.after(0, self.reset_buttons)
def reset_buttons(self):
"""重置按钮状态"""
self.start_button.config(state=tk.NORMAL)
self.stop_button.config(state=tk.DISABLED)
self.progress_bar['value'] = 0
self.status_label.config(text="就绪")
def stop_download(self):
"""停止下载"""
self.is_running = False
self.log("正在停止下载...", "warning")
self.stop_button.config(state=tk.DISABLED)
def update_progress(self, current, total):
"""更新进度条"""
self.current_chapter = current
self.total_chapters = total
if total > 0:
progress = (current / total) * 100
self.progress_bar['value'] = progress
self.status_label.config(text=f"{current}/{total} ({progress:.1f}%)")
def log(self, message, tag="info"):
"""添加日志"""
timestamp = datetime.now().strftime("%H:%M:%S")
log_msg = f"[{timestamp}] {message}\n"
self.log_queue.put((log_msg, tag))
def process_log_queue(self):
"""处理日志队列"""
try:
while True:
msg, tag = self.log_queue.get_nowait()
# 根据日志级别过滤
level = self.log_level.get()
if level != "全部":
tag_map = {"信息": "info", "成功": "success", "警告": "warning", "错误": "error"}
if level in tag_map and tag != tag_map[level]:
continue
# 根据关键词过滤
filter_text = self.log_filter.get().strip()
if filter_text and filter_text.lower() not in msg.lower():
continue
self.log_text.insert(tk.END, msg, tag)
self.log_text.see(tk.END)
except:
pass
finally:
self.root.after(100, self.process_log_queue)
def clear_log(self):
"""清空日志"""
self.log_text.delete(1.0, tk.END)
def open_download_dir(self):
"""打开下载目录"""
directory = self.output_dir.get()
if os.path.exists(directory):
os.startfile(directory)
else:
messagebox.showwarning("警告", "目录不存在")
def ask_open_dir(self, filepath):
"""询问是否打开目录"""
if messagebox.askyesno("完成", f"下载完成!\n文件保存在:\n{filepath}\n\n是否打开所在文件夹?"):
dir_path = os.path.dirname(filepath) if os.path.isfile(filepath) else filepath
if os.path.exists(dir_path):
os.startfile(dir_path)
def check_update(self):
"""检查更新"""
messagebox.showinfo("检查更新", "当前版本:v3.0\n\n最新版本请访问GitHub:\nhttps://github.com/HerryABU/ \n最新版本请访问csdn:\nhttps://blog.csdn.net/Herryfyh/")
def show_help(self):
"""显示帮助信息"""
help_text = """
话本小说网通用爬虫使用说明
1. 基本使用
- 输入小说URL(如:ihuaben.com/book/3462644.html)
- 程序会自动补全为 https://www.ihuaben.com/book/3462644.html
- 点击"获取信息"查看书籍详情
- 选择输出格式和配置
- 点击"开始下载"
2. 输出格式说明
- Markdown: 带目录的MD文件,适合阅读
- TXT: 纯文本文件,通用格式
- 独立章节: 每章一个文件,方便管理
- JSON: 包含所有数据的JSON格式
3. 配置说明
- 请求延迟: 避免请求过快被封
- 输出目录: 文件保存位置
- 自动文件名: 使用书名作为文件名
- 自定义文件名: 手动指定文件名
- 包含元数据: 是否包含书名/作者等信息
- 生成目录: 是否在Markdown中生成目录
4. 注意事项
- 请尊重版权,仅用于学习交流
- 不要频繁爬取,控制请求频率
- 如遇问题可调整延迟时间
"""
messagebox.showinfo("使用说明", help_text)
def show_faq(self):
"""显示常见问题"""
faq_text = """
常见问题解答
Q: 章节数获取的与下载的不一样?
A: 已经自动去除重复章节,部分网站可能存在重复列表,程序会自动去重。
Q: 下载速度太慢怎么办?
A: 可以适当调低延迟时间,但建议保持在0.5秒以上,避免被封IP。
Q: 是否收费?
A: 这是开源免费的软件,如果你是从任何渠道购买的,说明你上当受骗了!
Q: 支持其他网站吗?
A: 目前仅支持话本小说网(www.ihuaben.com)。
Q: 下载的文件在哪里?
A: 可以在输出目录中查看,默认是当前目录下的"下载"文件夹。
Q: 遇到错误怎么办?
A: 可以尝试:
- 检查网络连接
- 调高延迟时间
- 启用代理(如果需要)
- 在GitHub提交issue
Q: 如何更新到最新版本?
A: 请访问
GitHub: https://github.com/HerryABU/
CSDN: https://blog.csdn.net/Herryfyh
"""
messagebox.showinfo("常见问题", faq_text)
def show_disclaimer(self):
"""显示免责声明"""
disclaimer_text = """
免责声明
1. 本软件仅供学习交流使用,严禁用于商业用途。
2. 使用本软件下载的内容,请遵守相关法律法规,
尊重原作者的著作权,仅用于个人学习研究。
3. 本软件作者不对任何因使用本软件而产生的
法律纠纷承担责任。
4. 如果本软件侵犯了您的权益,请联系作者删除。
5. 使用本软件即表示您同意以上条款。
© 2024 HerryAvatar/HerryABU
"""
messagebox.showinfo("免责声明", disclaimer_text)
def show_about(self):
"""显示关于信息"""
about_text = """
话本小说网通用爬虫 v3.0
作者: HerryAvatar/HerryABU
GitHub: https://github.com/HerryABU/
CSDN: https://blog.csdn.net/Herryfyh
一个简单易用的小说下载工具
支持话本小说网所有作品
功能特点:
✓ 图形界面,操作简单
✓ 多格式输出
✓ 进度显示
✓ 代理支持
✓ 配置保存
✓ URL自动补全
✓ 开源免费
仅供学习交流使用
请尊重作者版权
如果觉得好用,欢迎给个Star!
"""
messagebox.showinfo("关于作者", about_text)
def on_closing(self):
"""关闭窗口"""
if self.is_running:
if not messagebox.askyesno("确认", "下载正在进行中,确定要退出吗?"):
return
self.root.destroy()
class GUIHuabenSpider:
"""供GUI使用的爬虫类"""
def __init__(self, url, output_format='md', delay=1.0, download_dir='下载',
auto_filename=True, custom_filename='', include_meta=True,
include_toc=True, proxy_enabled=False, proxy_host='',
proxy_port='', gui=None):
self.url = url
self.output_format = output_format
self.delay = delay
self.download_dir = download_dir
self.auto_filename = auto_filename
self.custom_filename = custom_filename
self.include_meta = include_meta
self.include_toc = include_toc
self.proxy_enabled = proxy_enabled
self.proxy_host = proxy_host
self.proxy_port = proxy_port
self.gui = gui
self.base_url = "https://www.ihuaben.com"
self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'}
self.proxies = None
if proxy_enabled and proxy_host and proxy_port:
self.proxies = {
'http': f'http://{proxy_host}:{proxy_port}',
'https': f'http://{proxy_host}:{proxy_port}'
}
self.book_info = {}
self.chapters = []
def log(self, msg, tag="info"):
if self.gui:
self.gui.log(msg, tag)
def _get_soup(self, url):
try:
response = requests.get(url, headers=self.headers, proxies=self.proxies, timeout=10)
response.encoding = 'utf-8'
return BeautifulSoup(response.text, 'html.parser')
except Exception as e:
self.log(f"请求失败: {url} - {e}", "error")
return None
def extract_chapter_list(self, soup):
chapters = []
seen_urls = set() # 用于去重
# 方法1: 查找chapter-list
chapter_container = soup.find('div', class_='chapter-list')
if chapter_container:
items = chapter_container.find_all('p')
for item in items:
num_span = item.find('span', class_='number')
title_span = item.find('span', class_='chapterTitle')
if num_span and title_span:
link = title_span.find('a')
if link:
chapter_url = urljoin(self.base_url, link.get('href'))
if chapter_url not in seen_urls:
seen_urls.add(chapter_url)
chapters.append({
'number': num_span.text.strip(),
'title': link.get('title', link.text.strip()),
'url': chapter_url
})
# 方法2: 直接查找所有章节链接
if not chapters:
links = soup.find_all('a', href=re.compile(r'/book/\d+/\d+\.html'))
for i, link in enumerate(links, 1):
chapter_url = urljoin(self.base_url, link.get('href'))
if chapter_url not in seen_urls:
seen_urls.add(chapter_url)
chapters.append({
'number': str(i),
'title': link.text.strip(),
'url': chapter_url
})
return chapters
def extract_chapter_content(self, chapter_url):
soup = self._get_soup(chapter_url)
if not soup:
return None
content_div = soup.find('div', id='contentsource')
if not content_div:
content_div = soup.find('div', id='content')
if not content_div:
return None
paragraphs = content_div.find_all('p')
if not paragraphs:
return content_div.get_text('\n', strip=True)
lines = []
for p in paragraphs:
if not p.text.strip():
continue
role_links = p.find_all('a', href=re.compile(r'/juese/'))
if role_links:
text = ''
for link in role_links:
text += link.text.strip() + ':'
text += p.get_text()
lines.append(text)
else:
lines.append(p.text.strip())
return '\n\n'.join(lines)
def save_as_markdown(self, filename):
with open(filename, 'w', encoding='utf-8') as f:
if self.include_meta and self.book_info:
f.write(f"# {self.book_info.get('book_name', '未知')}\n\n")
if self.book_info.get('author'):
f.write(f"**作者:** {self.book_info['author']}\n\n")
if self.book_info.get('category'):
f.write(f"**分类:** {self.book_info['category']}\n\n")
f.write(f"**总章节数:** {len(self.chapters)}\n\n")
f.write("---\n\n")
if self.include_toc:
f.write("## 目录\n\n")
for i, ch in enumerate(self.chapters, 1):
f.write(f"{i}. [{ch['title']}](#chapter-{i})\n")
f.write("\n---\n\n")
for i, ch in enumerate(self.chapters, 1):
if not self.gui or self.gui.is_running:
self.log(f"正在下载: {ch['title']}", "info")
content = self.extract_chapter_content(ch['url'])
f.write(f'## <span id="chapter-{i}">第{ch["number"]}章 {ch["title"]}</span>\n\n')
f.write(content or "*内容获取失败*")
f.write("\n\n---\n\n")
if self.gui:
self.gui.update_progress(i, len(self.chapters))
time.sleep(self.delay)
else:
self.log("下载已停止", "warning")
break
return filename
def save_as_txt(self, filename):
with open(filename, 'w', encoding='utf-8') as f:
if self.include_meta and self.book_info:
f.write(f"书名:{self.book_info.get('book_name', '未知')}\n")
if self.book_info.get('author'):
f.write(f"作者:{self.book_info['author']}\n")
f.write(f"总章节数:{len(self.chapters)}\n")
f.write("=" * 50 + "\n\n")
for i, ch in enumerate(self.chapters, 1):
if not self.gui or self.gui.is_running:
self.log(f"正在下载: {ch['title']}", "info")
content = self.extract_chapter_content(ch['url'])
f.write(f"第{ch['number']}章 {ch['title']}\n")
f.write("-" * 30 + "\n")
f.write(content or "内容获取失败")
f.write("\n\n" + "=" * 50 + "\n\n")
if self.gui:
self.gui.update_progress(i, len(self.chapters))
time.sleep(self.delay)
else:
break
return filename
def save_separate_files(self, dir_path):
os.makedirs(dir_path, exist_ok=True)
readme_path = os.path.join(dir_path, "00_README.md")
with open(readme_path, 'w', encoding='utf-8') as f:
f.write(f"# {self.book_info.get('book_name', '未知')}\n\n")
if self.book_info.get('author'):
f.write(f"**作者:** {self.book_info['author']}\n\n")
f.write(f"**总章节数:** {len(self.chapters)}\n\n")
f.write("## 章节列表\n\n")
for i, ch in enumerate(self.chapters, 1):
safe_title = re.sub(r'[\\/*?:"<>|]', '', ch['title'])
filename = f"{i:03d}_{safe_title}.md"
f.write(f"{i}. [{ch['title']}]({filename})\n")
for i, ch in enumerate(self.chapters, 1):
if not self.gui or self.gui.is_running:
self.log(f"正在下载: {ch['title']}", "info")
content = self.extract_chapter_content(ch['url'])
safe_title = re.sub(r'[\\/*?:"<>|]', '', ch['title'])
filename = os.path.join(dir_path, f"{i:03d}_{safe_title}.md")
with open(filename, 'w', encoding='utf-8') as f:
f.write(f"# 第{ch['number']}章 {ch['title']}\n\n")
f.write("*返回[目录](00_README.md)*\n\n")
f.write("---\n\n")
f.write(content or "*内容获取失败*")
if self.gui:
self.gui.update_progress(i, len(self.chapters))
time.sleep(self.delay)
else:
break
return dir_path
def save_as_json(self, filename):
data = {
'book_info': self.book_info,
'chapters': []
}
for i, ch in enumerate(self.chapters, 1):
if not self.gui or self.gui.is_running:
self.log(f"正在下载: {ch['title']}", "info")
content = self.extract_chapter_content(ch['url'])
data['chapters'].append({
'number': ch['number'],
'title': ch['title'],
'url': ch['url'],
'content': content or ''
})
if self.gui:
self.gui.update_progress(i, len(self.chapters))
time.sleep(self.delay)
else:
break
with open(filename, 'w', encoding='utf-8') as f:
json.dump(data, f, ensure_ascii=False, indent=2)
return filename
def run(self):
self.log("正在获取目录页...", "info")
soup = self._get_soup(self.url)
if not soup:
self.log("获取目录页失败", "error")
return None
# 提取书籍信息
title_elem = soup.find('h1', class_='text-danger')
if title_elem:
self.book_info['book_name'] = title_elem.text.strip()
author_elem = soup.find('a', href=re.compile(r'/user/\d+'))
if author_elem:
self.book_info['author'] = author_elem.text.strip()
# 提取章节列表
self.chapters = self.extract_chapter_list(soup)
if not self.chapters:
self.log("未找到章节列表", "error")
return None
self.log(f"找到 {len(self.chapters)} 个章节(已去重)", "success")
# 生成文件名
if self.auto_filename or not self.custom_filename:
safe_name = re.sub(r'[\\/*?:"<>|]', '', self.book_info.get('book_name', '小说'))
else:
safe_name = re.sub(r'[\\/*?:"<>|]', '', self.custom_filename)
if self.output_format == 'md':
filename = os.path.join(self.download_dir, f"{safe_name}.md")
result = self.save_as_markdown(filename)
elif self.output_format == 'txt':
filename = os.path.join(self.download_dir, f"{safe_name}.txt")
result = self.save_as_txt(filename)
elif self.output_format == 'separate':
dir_path = os.path.join(self.download_dir, safe_name)
result = self.save_separate_files(dir_path)
elif self.output_format == 'json':
filename = os.path.join(self.download_dir, f"{safe_name}.json")
result = self.save_as_json(filename)
else:
result = None
return result
def main():
root = tk.Tk()
app = HuabenSpiderGUI(root)
root.mainloop()
if __name__ == "__main__":
main()
八、更新日志
v3.0 (2026-3-8)
- ✨ 新增URL智能补全
- ✨ 优化GUI布局,横向排列
- ✨ 添加作者信息和链接
- ✨ 内置FAQ和免责声明
- ✨ 日志过滤增强
- ✨ 章节自动去重
- 🐛 修复若干bug
v2.0
- ✨ 作者调试版本,未发布
v1.0 (2026-3-8)
- ✨ 命令行版本
- ✨ 基础爬虫功能
九、免责声明
1. 本软件仅供学习交流使用,严禁用于商业用途。
2. 使用本软件下载的内容,请遵守相关法律法规,
尊重原作者的著作权,仅用于个人学习研究。
3. 本软件作者不对任何因使用本软件而产生的
法律纠纷承担责任。
4. 如果本软件侵犯了您的权益,请联系作者删除。
5. 使用本软件即表示您同意以上条款。
十、关于作者
- 作者:HerryAvatar/HerryABU
- GitHub:https://github.com/HerryABU/
- CSDN:https://blog.csdn.net/Herryfyh
如果觉得好用,欢迎给个Star!也欢迎在GitHub上提交Issue和PR,一起让这个工具变得更好!
十一、结语
话本小说网通用爬虫 v3.0 是一次重大的升级,不仅修复了之前版本的问题,还增加了许多实用功能。无论你是想收藏喜欢的小说,还是学习Python爬虫,这个工具都能帮到你。
开源免费,拒绝贩卖! 如果你觉得好用,欢迎分享给更多人,但请务必注明出处。
最后更新:2026年3月8日
版本:v3.0
附:完整代码下载
- GitHub: https://github.com/HerryABU/huaben-spider
- CSDN: https://blog.csdn.net/Herryfyh/article/details/xxxxx
(完整代码已在上一回复中提供,此处不再重复)
转载自CSDN-专业IT技术社区
原文链接:https://blog.csdn.net/Herryfyh/article/details/158812362

