
很多 TSDB 选型只关注“存得下、查得快”,但一旦系统进入平台化阶段(多个工厂/多个业务/外部协作),真正的难点会转向“权限、审计、隔离与治理”。本文用工程视角讨论这些能力该怎么评估,并结合 IoTDB 的路径模型给出落地方式。
1. 为什么平台化之后,TSDB 的评估重点会变?
在 PoC 阶段,你可能只需要满足:

但当系统进入“平台化”(多条产线、多家工厂、多个团队共用数据底座)时,需求会发生明显变化:
- 权限与隔离:A 工厂的数据不能被 B 工厂看到;同一工厂内不同角色权限不同
- 审计与追责:谁查了哪些数据、谁改了哪些配置、谁做了删除操作,要能追踪
- 配额与成本控制:某团队写入量暴涨不能拖垮全局;热数据与冷数据要分层治理
- 数据治理:命名规范、schema 演进、数据质量指标、缺失点统计
在这个阶段,TSDB 的选型标准就不再只是“性能好不好”,而是“能否持续运营、能否治理、能否让复杂组织协同”。
2. 多租户的三种常见方案:用哪一种取决于你的组织结构
多租户隔离没有唯一答案,常见有三种方案:
- 物理隔离:每个租户一套独立集群(隔离强,成本高)
- 逻辑隔离(同集群不同命名空间):共享资源,依赖权限与配额治理(成本低,治理要求高)
- 混合方案:核心租户独立部署,长尾租户共享集群
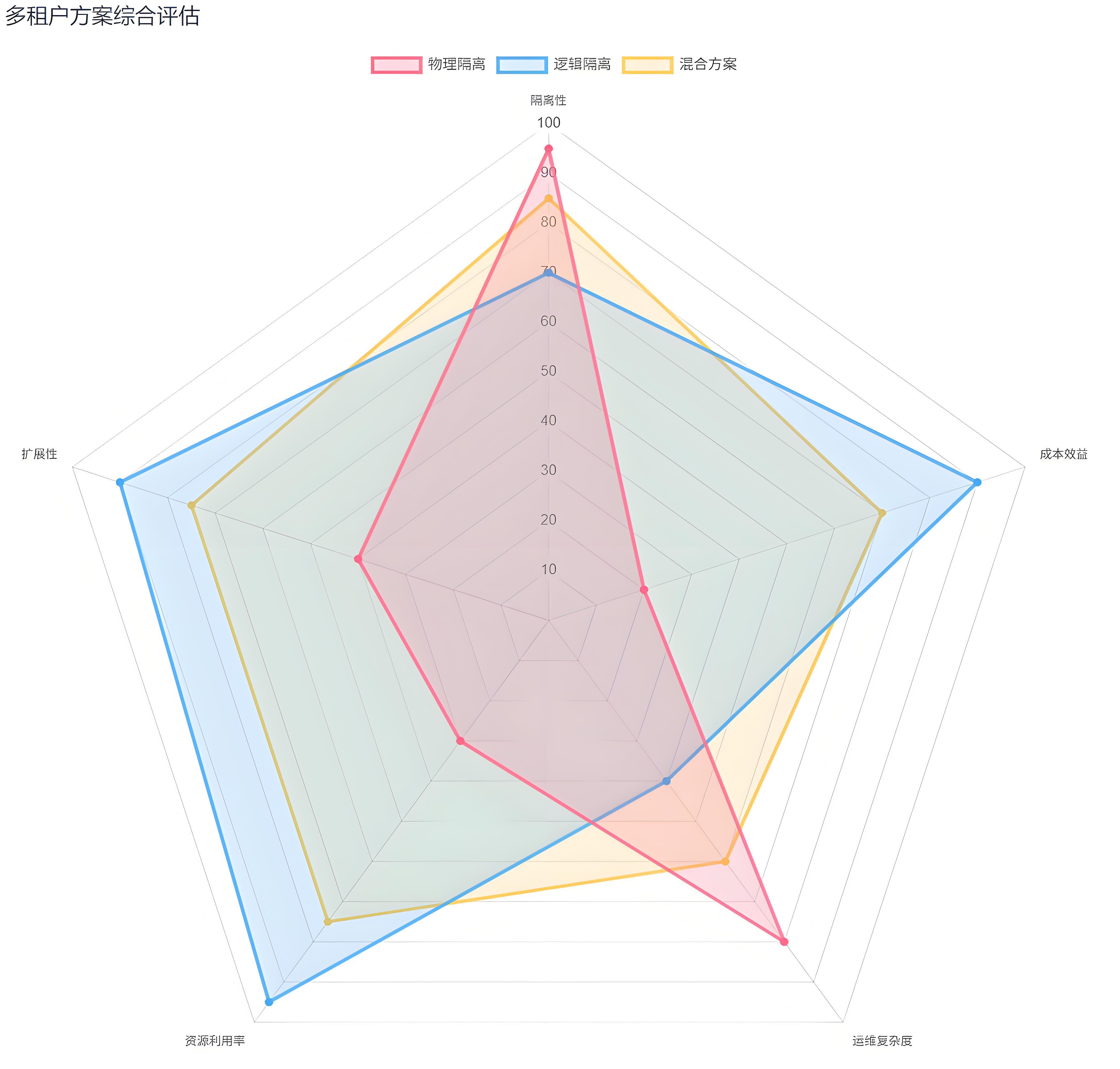
IoTDB 的路径模型天然适合第二种(逻辑隔离):把租户/工厂作为路径前缀,形成天然的“数据域”。
例如:
root.tenantA.plant01.line02.device07.temperature
root.tenantB.plant03.line01.device11.temperature
当路径前缀确定后,权限与审计就有了明确边界:用户被授权访问哪些前缀,就意味着能访问哪些数据域。
3. 用路径前缀做权限边界:把“组织结构”落到“可执行规则”
下面是一张常见的权限划分思路图:集团、工厂、车间、产线分别对应不同的路径域与角色。
这类结构的好处是:
- 权限规则与物理层级一致,便于沟通与落地
- 新增设备只要落在正确的路径域里,权限自动生效
- 审计记录中可直接看到访问的数据域范围
4. SQL 示例:用户、角色与授权(示意)
不同版本/部署模式下,具体权限语句可能存在差异,但“创建用户、创建角色、授权、撤权”的基本流程通常类似。下面给出一组“平台化系统常用”的示意 SQL(用于表达治理思路):
-- 创建用户与角色
CREATE USER plant01_viewer 'strong_password';
CREATE ROLE plant01_operator;
-- 授权:让 operator 读写某个工厂域
GRANT READ, WRITE ON root.tenantA.plant01.** TO ROLE plant01_operator;
-- 绑定用户到角色
GRANT ROLE plant01_operator TO USER plant01_viewer;
-- 撤权:回收某条产线访问
REVOKE READ ON root.tenantA.plant01.wf01.line02.** FROM ROLE plant01_operator;
选型评审时建议重点验证:
- 权限粒度是否能覆盖“前缀域 + 操作类型”(读/写/管理)
- 权限变更是否即时生效,是否需要重启
- 是否支持最小权限原则(默认拒绝,按需授权)
5. 审计怎么评估:不仅要“能查”,还要“能解释”
审计不是多打一行日志,而是要形成“可解释链路”。建议在选型阶段至少回答这些问题:
- 写入审计:能否定位某一时间段的写入来源(客户端、IP、应用标识)?
- 查询审计:能否记录“谁查询了什么范围的数据、返回量级是多少”?
- 管理操作审计:创建/删除序列、修改 TTL、执行删除语句等高风险操作是否留痕?
- 留存策略与合规:审计数据自身保留多久?能否导出到集中日志平台?
如果你计划走共享集群的多租户路线,审计能力的权重应该很高,因为这是事故定位与责任边界的基础。
6. 配额与成本治理:把资源当作“平台资产”运营
多租户系统最怕的不是某个租户写得多,而是写得多还没有边界。选型评审建议明确“资源治理”的验收项:
- 写入限流:是否能对某租户/某数据域限制写入速率?
- 存储配额:是否能对数据域设定最大磁盘占用或最大序列数?
- 生命周期策略(TTL):能否对不同数据域设置不同保留期?
在工程上,一个务实的做法是:把热/温/冷数据的保留期作为平台规则固化下来。例如:
- 高频振动:保留 90 天
- 低频状态:保留 2 年
- 汇总指标:保留 5 年
这样平台的成本与价值会更可控。
7. 落地建议:用“模板 + 校验”避免野生测点污染
平台化系统里最常见的数据治理问题是“野生测点”——采集侧升级后多了字段,未经评审就写进库里。长期会导致:
- 查询不可控(字段名过多、含义不一)
- 元数据膨胀(序列数增长失控)
- 权限规则与数据域无法对齐
建议的工程解法是两层:
- 数据库侧:尽量使用统一 schema/模板管理同类设备测点集合
- 接入侧:对写入数据做 schema 校验与映射(temp→temperature 等)
这部分能力是否“好用”,往往比你想象得更影响系统长期质量。
8. 一次完整的“多租户演练”怎么做:选型阶段就能验证
选型 PoC 阶段建议做一个小演练,覆盖平台治理的关键链路:
这个演练能快速回答:隔离是否可靠?权限是否易用?审计是否可用?这些是平台化系统的关键门槛。
9. 结语:当数据进入“协作”,数据库就必须进入“治理”
很多团队在选型时把治理问题留到“以后再说”,但平台化之后再补权限、补审计、补配额,代价会非常高:应用要重写、数据要迁移、组织协作要重新梳理。
更好的策略是:在选型阶段就把“治理”当作核心指标之一。IoTDB 的路径模型让“数据域边界”更容易表达,配合权限、审计与生命周期策略,可以把“数据可用”升级为“数据可控”。这类能力对长期运营的平台型系统尤为关键。
资源链接
- IoTDB 下载:https://iotdb.apache.org/zh/Download/

- 企业版官网:https://timecho.com

转载自CSDN-专业IT技术社区
原文链接:https://blog.csdn.net/2302_78391795/article/details/158841390

