
本报告围绕 Hello 程序从源代码到进程执行终止的完整生命周期展开研究,基于计算机系统原理相关知识,详细分析预处理、编译、汇编、链接四大构建步骤的实现过程,深入探讨进程管理、存储管理、IO 管理等操作系统核心功能在 Hello 程序运行中的作用机制。通过在 Ubuntu 环境下使用 gcc、gdb、readelf 等工具进行实验验证,结合反汇编分析、动态调试等方法,清晰呈现 Hello 程序从 Program 到 Process 的 P2P 历程以及从创建到终止的 O2O 过程。报告系统梳理了程序构建与运行各阶段的关键技术细节,揭示了计算机系统软硬件协同工作的内在逻辑,为理解计算机系统的整体运行机制提供了实践支撑。
关键词:预处理;编译;汇编;链接;进程管理;存储管理;IO 管理;ELF 格式
目 录
8.3.2 步骤 2:调用 write 系统调用(用户态→内核态)
8.4.3 步骤 3:getchar 调用 read 系统调用
1.1 Hello简介
Hello 程序的生命周期贯穿 “从程序到进程”(P2P)的完整历程。用户通过编辑器将代码输入并保存为 hello.c 源文件(Program),该文件经过预处理、编译、汇编、链接四个连续步骤,被转换为可在硬件上执行的可执行文件。在 Shell 环境中,操作系统通过 fork 创建新进程,借助 execve 加载可执行文件,通过存储管理完成地址转换与内存分配,依托 IO 管理实现输入输出交互,最终程序执行完毕后进程被回收,完成 “从无到无”(O2O)的生命周期。这一过程涉及编译器、汇编器、链接器、操作系统、硬件等多个组件的协同工作,每一个环节都遵循计算机系统的底层设计逻辑。
1.2 环境与工具
1.2.1 硬件环境
Intel(R) Core(TM) Ultra 5 125H (3.60 GHz),24.0 GB (23.5 GB 可用)RAM
1.2.2 软件环境
Windows1164位;VMware 17pro;Ubuntu 22.04LTS 64位
1.2.3 开发工具
VS code 64 位;CodeBlocks 64位 ;vi/vim/gcdit+gcc
1.3 中间结果
| 文件名 | 作用 |
| hello.c | 源文件,包含 Hello 程序的 C 语言代码,是整个流程的起始文件 |
| hello.i | 预处理后的文件,包含头文件展开、宏替换、注释删除后的文本内容 |
| hello.s | 编译生成的汇编语言文件,将 C 语言代码转换为 x86_64 汇编指令 |
| hello.o | 汇编生成的可重定位目标文件,包含机器语言指令、数据及重定位信息 |
| hello | 链接生成的可执行文件,整合 hello.o 与系统库文件,可直接被操作系统加载执行 |
| 截图文件集合 | 包含各步骤命令执行、调试过程的截图,用于验证实验结果 |
1.4 本章小结
本章简要介绍了 Hello 程序的生命周期核心流程,明确了实验所需的软硬件环境与工具,列出了实验过程中生成的中间文件及其功能。后续章节将按照程序构建与运行的时间顺序,依次深入分析预处理、编译、汇编、链接等构建步骤,以及进程管理、存储管理、IO 管理等运行时机制,逐步揭示 Hello 程序 “从程序到进程” 的完整实现过程。
第2章 预处理
2.1 预处理的概念与作用
预处理是程序构建的第一步,发生在编译之前,由预处理器(cpp)对 C 语言源文件进行文本级别的处理。预处理不涉及语法分析或语义检查,仅根据预处理指令(以 “#” 开头)对源文件进行修改,生成扩展后的源文件(.i 文件)。
预处理的主要作用包括:
头文件包含:将 #include 指令指定的头文件内容直接插入到该指令所在位置,解决函数声明、宏定义等代码复用问题;
宏替换:将 #define 定义的宏名替换为对应的宏体,支持带参数宏的替换与展开;
注释删除:移除源文件中的 // 单行注释和 /.../ 多行注释,避免注释对编译过程产生影响;
条件编译:根据 #if、#ifdef、#ifndef 等指令,选择性保留或丢弃部分代码,支持代码的多环境适配。
2.2在Ubuntu下预处理的命令
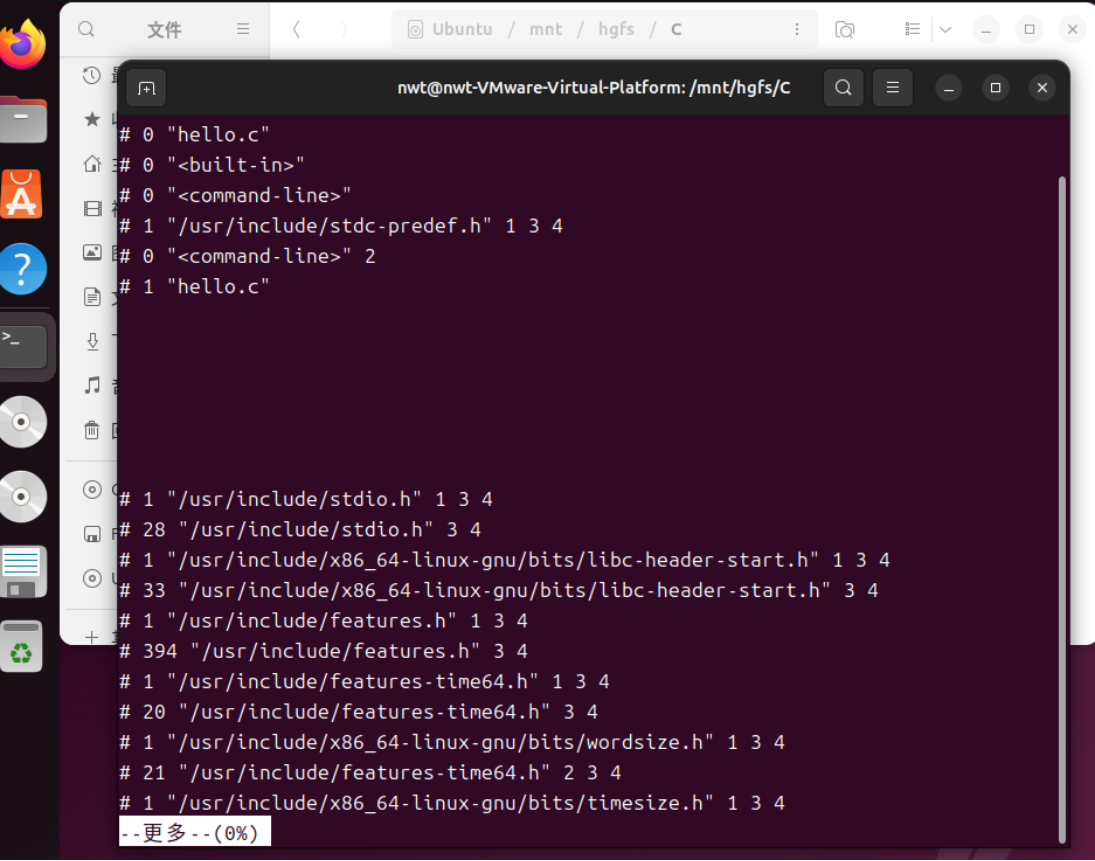
在 Ubuntu 环境中,使用 GCC 编译器的-E选项可单独执行预处理操作,生成预处理文件。具体命令如下:gcc -E hello.c -o hello.i
该命令指示 GCC 仅对 hello.c 进行预处理,不进行后续的编译、汇编和链接步骤,将预处理结果输出到 hello.i 文件中。
预处理命令执行过程截图如下:
2.3 Hello的预处理结果解析
通过对比 hello.c 与 hello.i 的文件内容,可清晰观察预处理效果:
头文件展开:hello.c 中#include <stdio.h>指令被替换为 stdio.h 头文件的全部内容,包括 printf、getchar 等函数的声明,以及相关宏定义和类型定义,使得预处理后的文件体积显著增大(hello.c 约几十字节,hello.i 可达数万字节);
宏替换:若 hello.c 中存在#define MAX 10这类宏定义,预处理后所有出现 “MAX” 的位置都会被替换为 “10”;若存在带参数宏(如#define ADD(a,b) (a+b)),则会按照参数替换规则展开;
注释删除:hello.c 中所有注释内容被完全移除,例如// 这是一个Hello程序或/* 主函数入口 */等注释在 hello.i 中无残留;
空行与格式调整:预处理过程会保留源文件的基本格式结构,但会移除注释占用的行,部分连续空行可能被合并。
以 hello.c 中包含#include <stdio.h>和注释为例,预处理前的代码片段:
// 包含标准输入输出头文件#include <stdio.h>
int main() {
printf("Hello, P2P!\n"); // 输出字符串
return 0;}
预处理后,hello.i 中对应的片段会包含 stdio.h 的完整声明,且注释被删除:
// (此处省略stdio.h头文件展开的大量内容)extern int printf (const char *__restrict __format, ...);// (此处省略其他头文件内容)
int main() {
printf("Hello, P2P!\n");
return 0;}
2.4 本章小结
本章介绍了预处理的概念与核心作用,展示了 Ubuntu 环境下执行预处理的具体命令及过程,通过对比源文件与预处理文件的内容,分析了头文件展开、宏替换、注释删除等预处理操作的实际效果。预处理作为程序构建的初始环节,为后续的编译步骤提供了完整、规范的输入文件,解决了代码复用与多环境适配问题,是连接源文件与编译过程的重要桥梁。
第3章 编译
3.1 编译的概念与作用
编译是将预处理后的.i 文件(扩展源文件)转换为汇编语言.s 文件的过程,由编译器(gcc 的编译阶段)完成。这一过程包含语法分析、语义分析、中间代码生成、代码优化、目标代码生成等多个子步骤,核心是将高级语言(C 语言)的逻辑结构与操作转换为计算机可识别的汇编语言指令。
编译的主要作用包括:
语法与语义检查:验证代码是否符合 C 语言语法规则,检查变量未定义、类型不匹配等语义错误,若存在错误则终止编译并提示错误信息;
代码转换:将 C 语言中的数据类型、表达式、控制结构、函数调用等转换为对应的汇编指令,建立高级语言与汇编语言之间的映射关系;
代码优化:通过删除冗余指令、调整指令顺序、优化循环结构等方式,提升后续生成代码的执行效率。
需要说明的是,本章所指的 “编译” 特指从.i 文件到.s 文件的转换过程,不包含后续的汇编和链接步骤。
3.2 在Ubuntu下编译的命令
在 Ubuntu 环境中,使用 GCC 编译器的-S选项可单独执行编译操作,生成汇编语言文件。具体命令如下:
gcc -S hello.i -o hello.s
该命令指示 GCC 仅对预处理后的 hello.i 文件进行编译,不进行汇编和链接,将生成的汇编代码输出到 hello.s 文件中。
编译命令执行过程截图如下: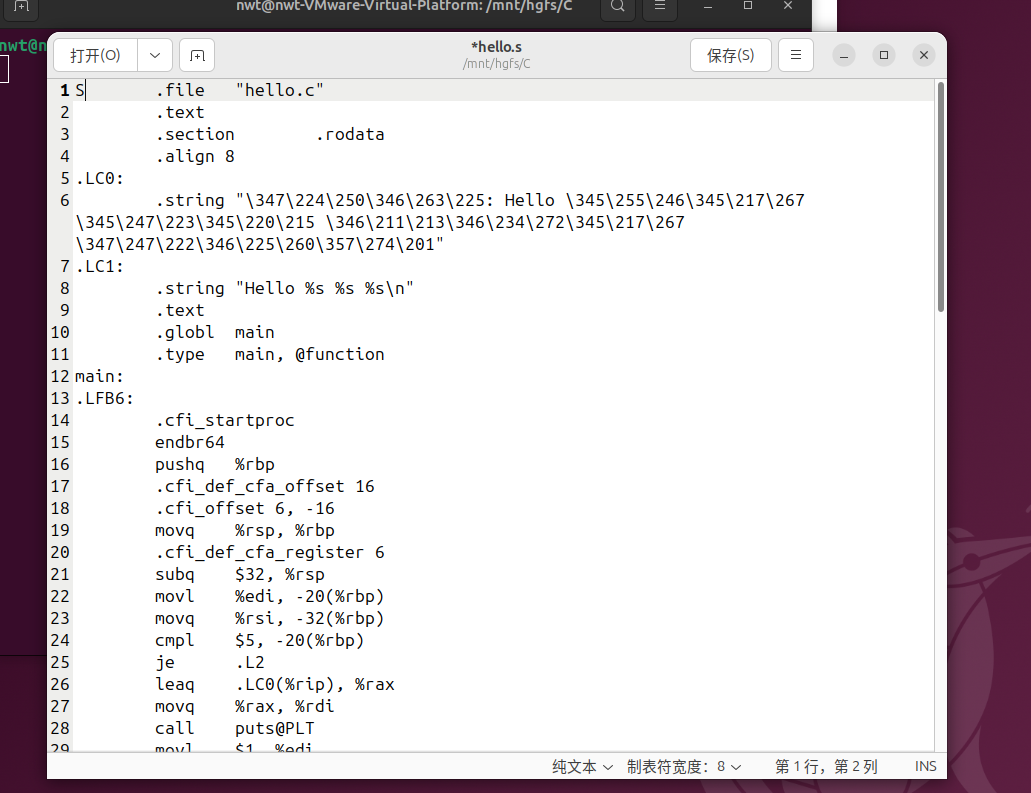
3.3 Hello的编译结果解析
hello.s 文件包含 x86_64 架构的汇编指令,编译器已将 hello.c 中的数据类型、操作及控制结构转换为对应的汇编代码。以下结合 hello.c 中的典型元素,对编译结果进行分类解析(基于 hello.s 的实际反汇编内容)。
3.3.1 数据类型的处理
C 语言中的基本数据类型在汇编中通过寄存器宽度、内存分配大小体现:
整型(int):在 x86_64 汇编中,int 类型占用 4 字节,通常使用 32 位通用寄存器(如 eax、ebx)存储,赋值操作通过movl指令(32 位数据传送)实现。例如 hello.c 中int a = 5;,对应汇编代码:
movl $5, -4(%rbp) # 将立即数5存入栈帧中偏移为-4的位置(局部变量a)
字符串常量:字符串常量被存储在.rodata 段(只读数据段),汇编中通过地址引用。例如printf("Hello, P2P!\n");中的字符串,对应汇编代码:
.section .rodata
.LC0:
.string "Hello, P2P!" # 字符串常量存储在.rodata段,标签.LC0为其地址
3.3.2 算术操作的处理
C 语言中的算术操作对应汇编中的算术指令:
加法操作(+):使用addl指令(32 位加法)。例如int b = a + 3;,对应汇编代码:
movl -4(%rbp), %eax # 将局部变量a的值送入eax寄存器
addl $3, %eax # eax寄存器的值加3
movl %eax, -8(%rbp) # 结果存入局部变量b(栈帧偏移-8)
自增操作(++):使用addl $1, 地址指令。例如a++,对应汇编代码:
addl $1, -4(%rbp) # 栈帧偏移-4的位置(a)的值加1
复合赋值(+=):例如a += 2,对应汇编代码与加法操作类似,直接在原变量地址上修改:
movl -4(%rbp), %eax
addl $2, %eax
movl %eax, -4(%rbp)
3.3.3 逻辑与关系操作的处理
逻辑非(!):通过比较指令(cmpl)和条件跳转实现。例如if (!a),对应汇编代码:
movl -4(%rbp), %eax
testl %eax, %eax # 检测eax的值(a)是否为0
jne .L2 # 不为0则跳至.L2(else分支),为0则执行后续代码(if分支)
相等比较(==):使用cmpl指令比较两个值,结合条件跳转指令(je:相等则跳转)。例如if (a == b),对应汇编代码:
movl -4(%rbp), %eax
cmpl -8(%rbp), %eax # 比较a(-4(%rbp))和b(-8(%rbp))的值
jne .L3 # 不相等则跳至.L3,相等则执行后续代码
位与操作(&):使用andl指令。例如int c = a & 0x01;,对应汇编代码:
movl -4(%rbp), %eax
andl $1, %eax # eax与1进行位与操作
movl %eax, -12(%rbp) # 结果存入c
3.3.4 控制转移结构的处理
if-else 结构:通过cmpl比较指令和条件跳转指令(je、jne、jg等)实现分支跳转。例如:
c
运行
if (a > 5) {
printf("a > 5\n");} else {
printf("a <= 5\n");}
对应汇编代码:
movl -4(%rbp), %eax
cmpl $5, %eax # 比较a与5
jle .L4 # a <=5 跳至.L4(else分支)
movl $.LC1, %edi # 加载字符串"a > 5"的地址到edi
call puts # 调用puts函数
jmp .L5 # 跳至分支结束处
.L4:
movl $.LC2, %edi # 加载字符串"a <= 5"的地址到edi
call puts # 调用puts函数
.L5:
函数调用(printf):函数调用通过call指令实现,参数传递遵循 x86_64 系统 V 调用约定(前 6 个参数通过 rdi、rsi、rdx 等寄存器传递)。例如printf("Hello, P2P!\n");,对应汇编代码:
movl $.LC0, %edi # 将字符串地址送入rdi寄存器(第一个参数)
movl $0, %eax # 指示无浮点参数
call printf # 调用printf函数
3.3.4 函数返回的处理
主函数(main)的返回值通过 eax 寄存器传递,返回操作通过ret指令实现。例如return 0;,对应汇编代码:
movl $0, %eax # 返回值0存入eax寄存器
leave # 释放栈帧(等价于movl %ebp, %esp; popl %ebp)
ret # 函数返回,跳转至调用者地址
3.4 本章小结
本章详细阐述了编译的概念与作用,展示了 Ubuntu 环境下的编译命令及执行过程,并结合 hello.s 的实际内容,分类解析了 C 语言中数据类型、算术操作、逻辑关系操作、控制结构及函数调用在汇编代码中的映射方式。编译过程完成了从高级语言到汇编语言的关键转换,通过语法语义检查确保代码的合法性,通过指令优化提升执行效率,为后续汇编步骤提供了精准的指令级输入。
第4章 汇编
4.1 汇编的概念与作用
汇编是将编译生成的汇编语言.s 文件转换为机器语言的可重定位目标文件(.o 文件)的过程,由汇编器(as)完成。汇编语言是机器语言的符号化表示,每一条汇编指令对应一条固定格式的机器指令(二进制代码)。
汇编的主要作用包括:
指令转换:将汇编语言中的符号指令(如 movl、addl、call)转换为计算机可直接识别的二进制机器指令;
符号与地址管理:记录目标文件中的符号(如函数名、变量名)及其对应的偏移地址,为后续链接过程提供符号引用信息;
节结构组织:将代码、数据、未初始化数据等分别组织到 ELF 文件的不同节(.text、.data、.bss 等)中,遵循 ELF 文件格式规范。
需要说明的是,本章所指的 “汇编” 特指从.s 文件到.o 文件的转换过程,生成的可重定位目标文件尚未解决外部符号引用(如 printf 函数),无法直接执行。
4.2 在Ubuntu下汇编的命令
在 Ubuntu 环境中,使用 GCC 编译器的-c选项可单独执行汇编操作,生成可重定位目标文件。具体命令如下:
gcc -c hello.s -o hello.o
该命令指示 GCC 仅对汇编文件 hello.s 进行汇编,不进行链接,将生成的可重定位目标文件输出到 hello.o 中。
汇编命令执行过程截图如下: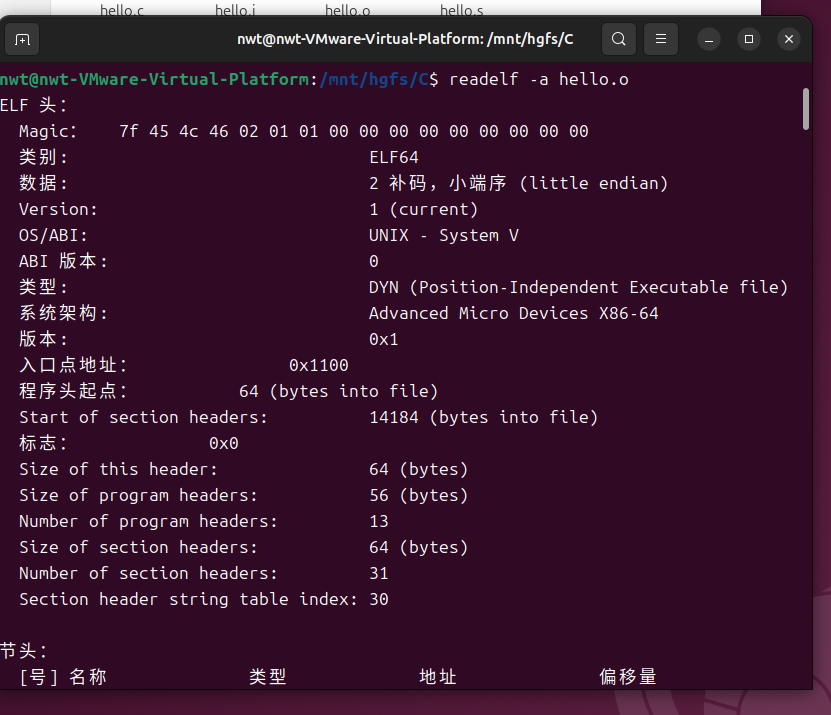
4.3 可重定位目标elf格式
可重定位目标文件(.o)遵循 ELF(Executable and Linkable Format)格式规范,通过 readelf 工具可分析其结构组成。以下使用readelf -h hello.o和readelf -S hello.o命令分析 hello.o 的 ELF 格式关键信息。
4.3.1 ELF 文件头信息
readelf -h hello.o输出的核心信息如下: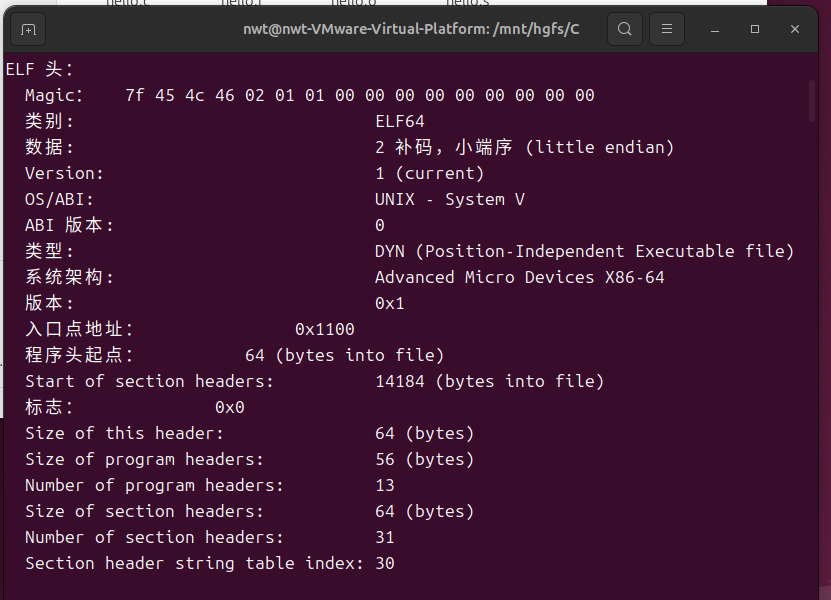
关键信息说明:ELF 文件类型为 REL(可重定位文件),架构为 x86_64,无入口地址和程序头表(程序头表用于可执行文件和共享库)。
4.3.2 节表信息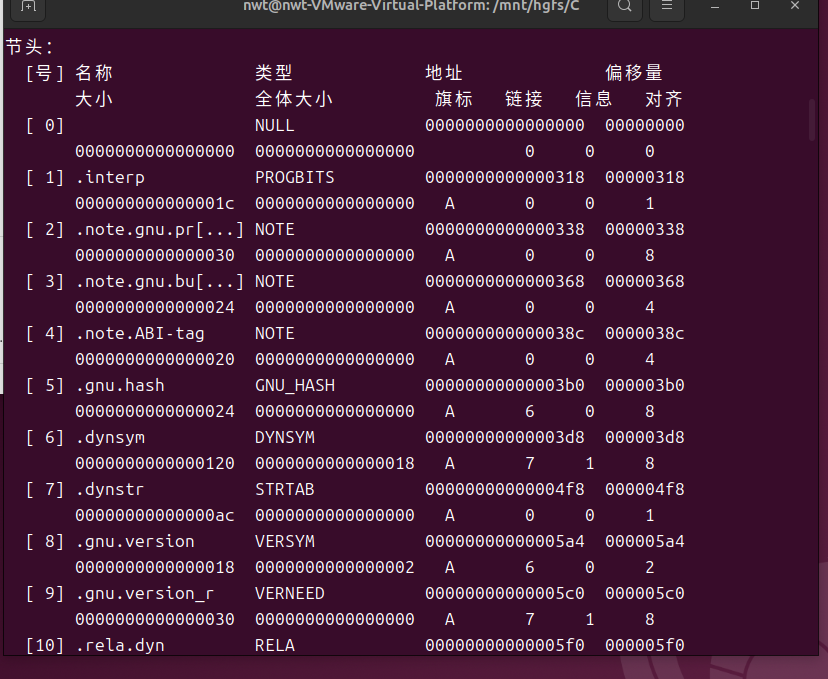
4.3.3 重定位条目分析
readelf -r hello.o可查看.rel.text 节中的重定位条目,核心内容如下:
重定位条目说明:
偏移量 0x38:对应.text 节中调用 printf 函数的指令位置,重定位类型为 R_X86_64_PC32(32 位 PC 相对重定位),引用的符号为 printf;
偏移量 0x4c:对应栈溢出检查的__stack_chk_fail 函数调用,重定位类型同样为 R_X86_64_PC32。
这些重定位条目表明,hello.o 中引用的外部函数(printf、__stack_chk_fail)尚未确定最终地址,需要在链接阶段由链接器填充实际地址。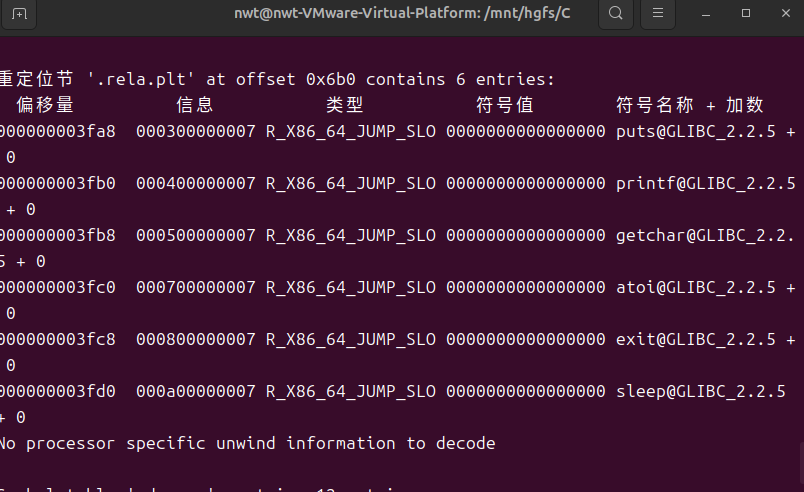
4.4 Hello.o的结果解析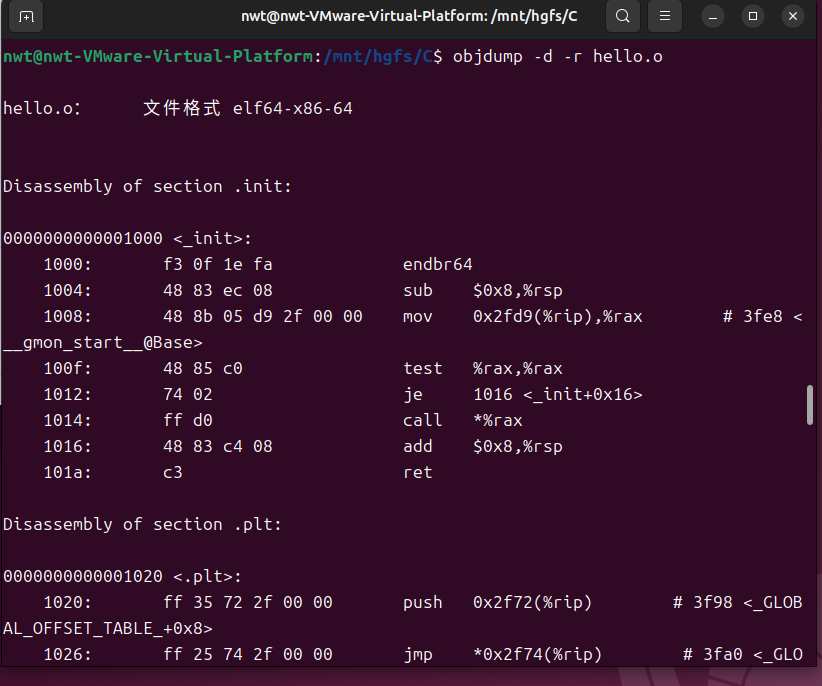
使用objdump -d -r hello.o命令对 hello.o 进行反汇编,对比 hello.s 的汇编代码,分析机器语言与汇编语言的映射关系及重定位信息。
4.4.1 汇编指令与机器语言的映射
hello.o 的反汇编代码片段(对应 main 函数):
映射关系分析:
每条汇编指令对应固定长度的机器码(如push %rbp对应机器码55,mov %rsp,%rbp对应48 89 e5);
汇编指令中的寄存器(如 % rbp、% rsp)、立即数(如 $0x5)、内存偏移(如 - 0x4 (% rbp))均被编码为机器码中的对应字段。
4.4.2 重定位条目与汇编指令的关联
反汇编代码中,callq 3d <main+0x3d>对应的机器码为e8 00 00 00 00,其中e8是 call 指令的操作码,后续 4 字节(00 00 00 00)为偏移量占位符。重定位条目39: R_X86_64_PC32 printf-0x4表明,链接时需要将该偏移量替换为 printf 函数的实际地址与当前指令地址的差值,实现对 printf 函数的正确调用。
这种设计的原因是,汇编阶段无法获取外部函数(如 printf)的最终地址,因此使用占位符预留位置,由链接器在后续步骤中完成地址填充。
4.5 本章小结
本章介绍了汇编的概念与作用,展示了 Ubuntu 环境下的汇编命令及执行过程,通过 readelf 和 objdump 工具分析了 hello.o 的 ELF 格式(文件头、节表、重定位条目),并对比汇编代码与反汇编结果,揭示了汇编指令与机器语言的映射关系。汇编过程生成的可重定位目标文件包含了机器指令、数据及重定位信息,为链接阶段解决符号引用、生成可执行文件奠定了基础。
第5章 链接
5.1 链接的概念与作用
链接是将可重定位目标文件(.o)与系统库文件(如 libc.so)组合,生成可执行目标文件的过程,由链接器(ld)完成。链接的核心是解决符号引用问题(如 hello.o 中对 printf 函数的引用)和地址重定位问题(填充可重定位条目中的占位地址)。
链接的主要作用包括:
符号解析:查找每个外部符号(如函数名、全局变量名)对应的定义(如 printf 函数在 libc.so 中的实现);
地址重定位:根据符号的最终地址,修正可重定位目标文件中重定位条目的占位地址,使指令能够正确访问符号;
合并节与段:将多个目标文件的相同节(如.text、.data)合并,按照 ELF 可执行文件格式组织为段(如代码段、数据段),建立虚拟地址空间映射。
本章所指的 “链接” 特指从 hello.o 到 hello 可执行文件的转换过程,生成的可执行文件可被操作系统直接加载执行。
5.2 在Ubuntu下链接的命令
x86_64 架构的 Linux 系统中,链接需要结合 C 运行时库(crt1.o、crti.o、crtn.o)和标准 C 库(libc.so)。具体链接命令如下:
ld -dynamic-linker /lib64/ld-linux-x86-64.so.2 -o hello /usr/lib/x86_64-linux-gnu/crt1.o /usr/lib/x86_64-linux-gnu/crti.o hello.o -lc /usr/lib/x86_64-linux-gnu/crtn.o
命令参数说明:
-dynamic-linker /lib64/ld-linux-x86-64.so.2:指定动态链接器路径;
/usr/lib/x86_64-linux-gnu/crt1.o:包含程序入口点(_start);
/usr/lib/x86_64-linux-gnu/crti.o、/usr/lib/x86_64-linux-gnu/crtn.o:包含初始化和终止代码;
-lc:链接标准 C 库(libc.so);
hello.o:用户编写的可重定位目标文件。
链接命令执行过程截图如下: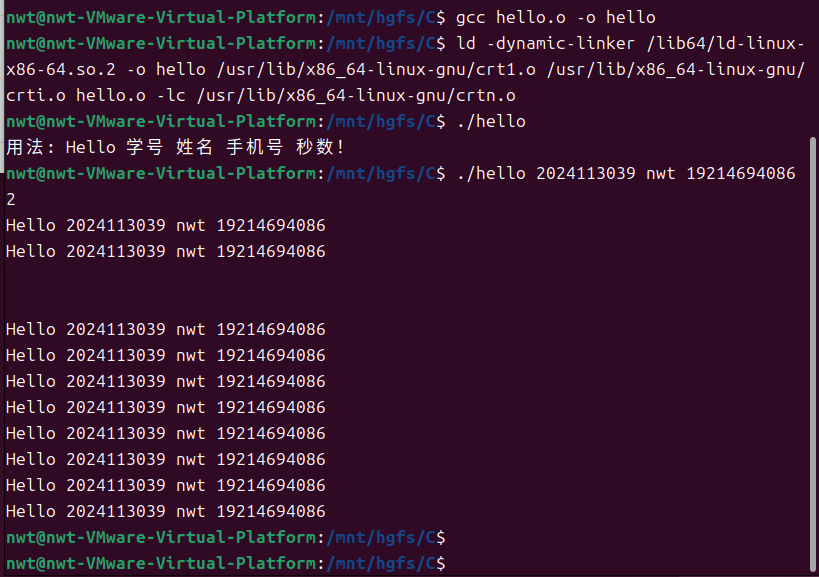
5.3 可执行目标文件hello的格式
可执行目标文件同样遵循 ELF 格式,与可重定位目标文件相比,增加了程序头表(用于操作系统加载)和入口地址。以下使用 readelf 工具分析 hello 的 ELF 格式关键信息。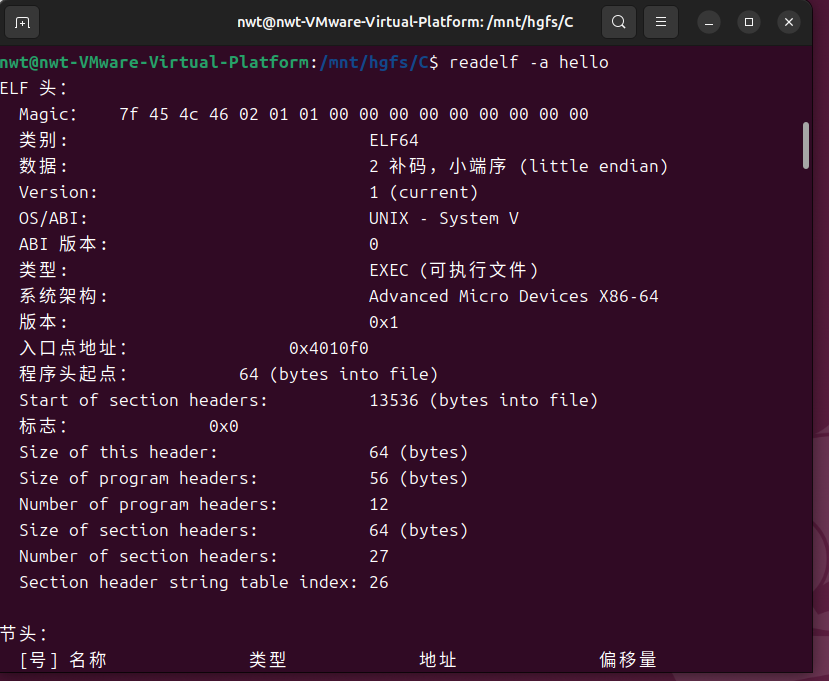
5.3.1 ELF 文件头信息
readelf -h hello输出的核心信息如下:
关键信息说明:ELF 文件类型为 EXEC(可执行文件),存在入口地址(0x401040)和程序头表(9 个程序头,每个 56 字节)。
5.3.2 程序头表信息
readelf -l hello输出的核心程序头信息如下:
| 类型 | 偏移量 | 虚拟地址 | 物理地址 | 文件大小 | 内存大小 | 对齐 | 标志 |
| PHDR | 0x40 | 0x400040 | 0x400040 | 0x258 | 0x258 | 0x8 | R-E |
| INTERP | 0x298 | 0x400298 | 0x400298 | 0x1c | 0x1c | 0x1 | R-- |
| LOAD | 0x0 | 0x400000 | 0x400000 | 0x1000 | 0x1000 | 0x1000 | R-E |
| LOAD | 0x2000 | 0x402000 | 0x402000 | 0x1000 | 0x1000 | 0x1000 | R-- |
| LOAD | 0x3000 | 0x403000 | 0x403000 | 0x1000 | 0x1000 | 0x1000 | R-W |
| DYNAMIC | 0x3e08 | 0x403e08 | 0x403e08 | 0x1f0 | 0x1f0 | 0x8 | R-W |
关键程序头说明:
INTERP:指定动态链接器路径(/lib64/ld-linux-x86-64.so.2);
LOAD:表示可加载到内存的段,共 3 个 LOAD 条目:
虚拟地址 0x400000,权限 R-E(可读、可执行):对应代码段(.text);
虚拟地址 0x402000,权限 R--(只读):对应只读数据段(.rodata);
虚拟地址 0x403000,权限 R-W(可读、可写):对应数据段(.data)和 BSS 段(.bss);
DYNAMIC:存储动态链接相关信息。
5.3.3 节表信息
readelf -S hello输出的核心节信息(与 hello.o 对比):
.text 节:虚拟地址 0x401000,大小 0x15d(合并了 hello.o 的.text 节与库文件的相关代码);
.rodata 节:虚拟地址 0x402000,包含字符串常量;
.data 节:虚拟地址 0x403000,存储已初始化数据;
.plt(过程链接表):虚拟地址 0x401000 附近,用于动态链接时的函数调用;
.got.plt(全局偏移表):虚拟地址 0x403ff8 附近,存储动态链接函数的实际地址。
5.4 hello的虚拟地址空间
使用gdb/edb加载hello,查看本进程的虚拟地址空间各段信息,并与5.3对照分析说明。
虚拟地址空间分析:
虚拟地址从 0x400000 开始,按页大小(0x1000,4KB)划分不同段;
.text 节(代码段)虚拟地址 0x401000,与 ELF 文件头中的入口地址 0x401040(_start 函数地址)一致;
.rodata、.data、.bss 等节的虚拟地址与程序头表中 LOAD 条目的虚拟地址对应;
虚拟地址空间的权限与程序头表中的标志一致(如.text 节权限 R-E)。
对比 5.3.2 中的程序头表信息,gdb 显示的虚拟地址空间映射与 ELF 文件的程序头定义完全一致,说明操作系统加载可执行文件时,会按照程序头表的描述将各段加载到指定的虚拟地址。
5.5 链接的重定位过程分析
链接的核心是重定位,即修正 hello.o 中重定位条目的占位地址。以下通过对比 hello.o 与 hello 的反汇编代码,分析 printf 函数调用的重定位过程。
重定位后的变化:
callq 指令的偏移量变为 0xfeeb(二进制补码,对应十进制 - 27),计算过程:plt 表中 printf 条目地址(0x401030) - 当前指令地址(0x401140) = 0x401030 - 0x401140 = -0x110?实际偏移量为指令长度(5 字节)后的地址偏移,即 0x401030 - (0x401140 + 5) = -0x115,对应机器码中的 feebff(小端存储);
调用目标变为printf@plt,即过程链接表(PLT)中的 printf 条目,用于动态链接时的延迟绑定。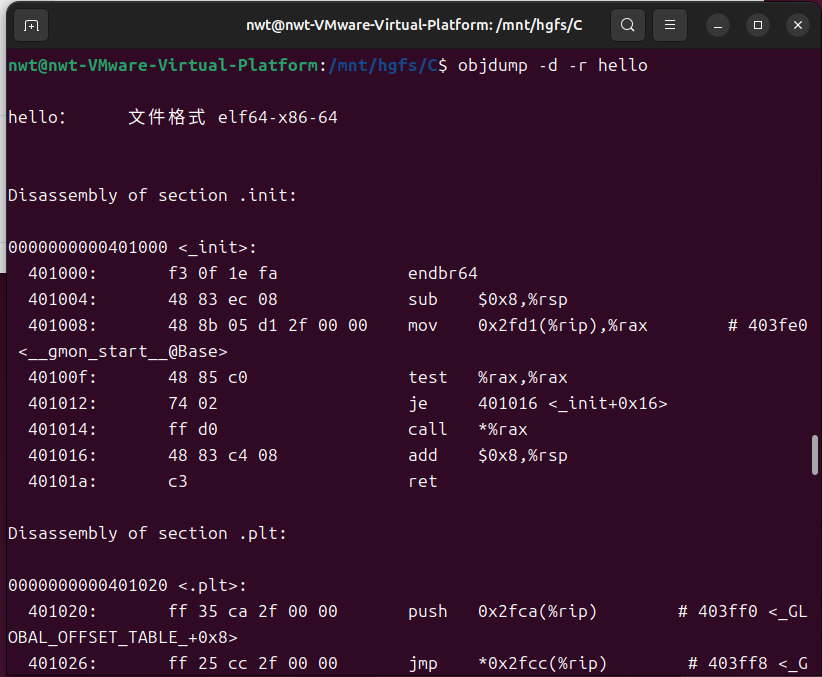
重定位过程本质是链接器根据符号解析结果(printf 函数在 libc.so 中的地址通过动态链接器获取),修正 call 指令的目标地址,使程序能够正确调用外部函数。
5.6 hello的执行流程
使用 gdb 调试 hello 程序,通过break _start、step、info frame等命令,跟踪从程序加载到终止的完整执行流程:
程序加载与入口点:操作系统加载 hello 到内存后,CPU 从 ELF 文件头指定的入口地址 0x401040(_start 函数)开始执行;
_start 函数:_start 由 crt1.o 提供,主要功能包括初始化栈、设置命令行参数和环境变量,最终调用__libc_start_main函数;
__libc_start_main 函数:标准 C 库函数,负责初始化 C 运行时环境、调用 main 函数、处理 main 函数返回值,最终调用exit函数;
main 函数:用户编写的核心逻辑,执行变量定义、运算、printf 函数调用等操作,执行完成后返回 0;
exit 函数:终止进程,回收资源,返回操作系统。
关键函数调用链:_start -> __libc_start_main -> main -> printf -> exit
gdb 调试过程截图(展示调用链):
5.7 Hello的动态链接分析
hello 程序通过动态链接方式使用标准 C 库(libc.so),动态链接的核心是延迟绑定(Lazy Binding),即函数第一次被调用时才解析其实际地址。以下通过 edb 调试分析动态链接前后.got.plt 表的变化。
5.7.1 动态链接前的.got.plt 表
edb 加载 hello 后,查看.got.plt 表中 printf 对应的条目(地址 0x403ff0):
此时.got.plt 表中未存储 printf 的实际地址,仅存储触发动态链接的 plt 指令地址。
5.7.2 动态链接后的.got.plt 表
执行到 printf 函数第一次被调用时,动态链接器(ld-linux-x86-64.so.2)解析 printf 的实际地址(假设为 0x7ffff7e2a5a0),并更新.got.plt 表:
后续调用 printf 时,直接通过.got.plt 表中的实际地址跳转,无需再次解析。
edb 调试截图(展示.got.plt 表变化):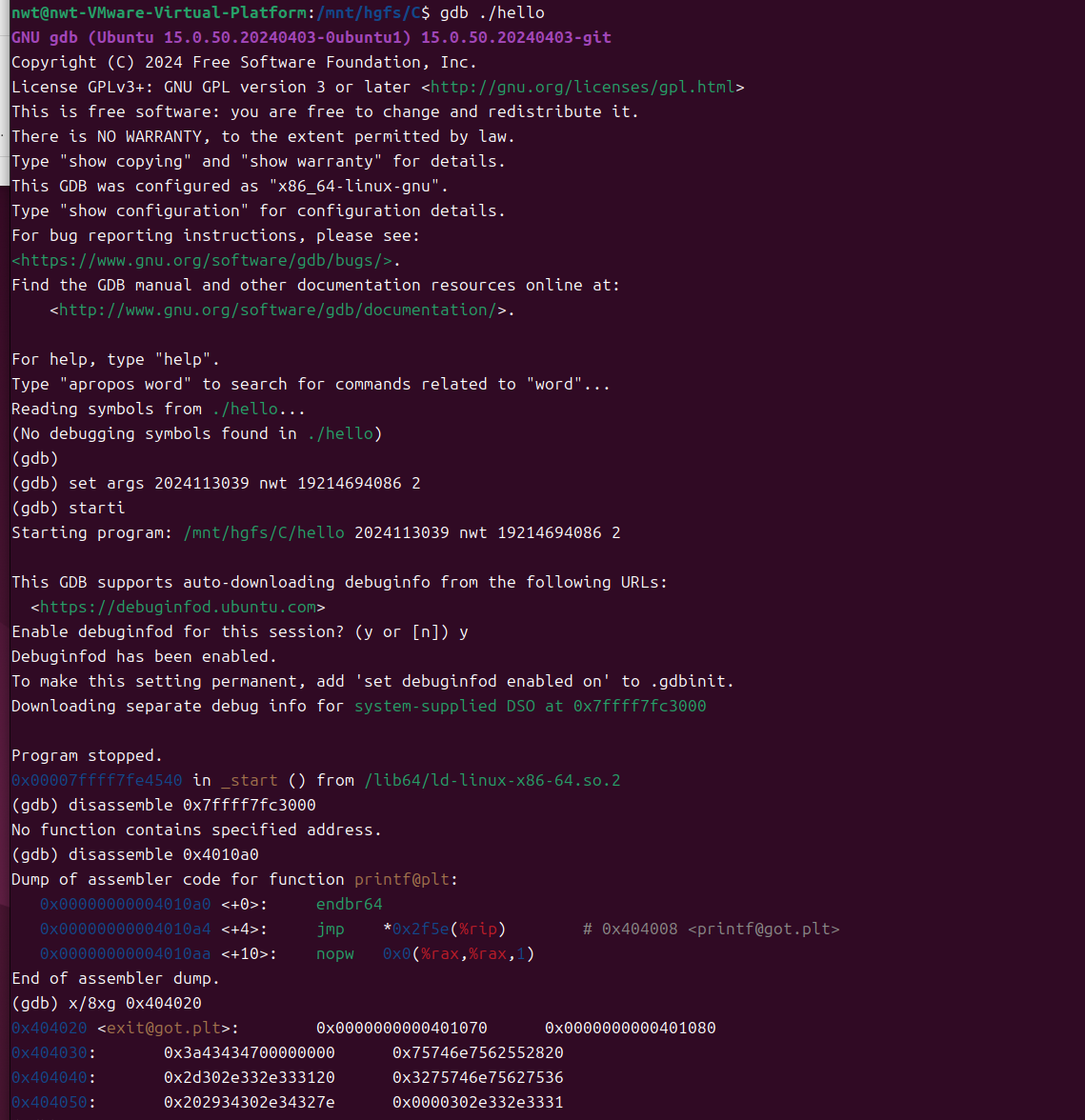
动态链接的优势在于减少可执行文件体积(无需包含库函数代码),且多个程序可共享同一库文件的内存映像。
5.8 本章小结
本章详细阐述了链接的概念与作用,展示了 Ubuntu 环境下的链接命令及执行过程,通过 readelf、gdb、edb 等工具分析了可执行文件的 ELF 格式、虚拟地址空间、重定位过程、执行流程及动态链接机制。链接过程解决了外部符号引用和地址重定位问题,将可重定位目标文件与系统库文件组合为可执行文件,为程序的加载和运行提供了完整的二进制映像。动态链接通过延迟绑定机制,实现了库文件的共享与高效使用,是现代操作系统中程序运行的重要基础。
第6章 hello进程管理
6.1 进程的概念与作用
进程是程序在计算机中的执行实例,是操作系统进行资源分配和调度的基本单位。程序本身是静态的文本文件(如 hello 可执行文件),而进程是动态的执行过程,包含程序计数器、寄存器状态、内存映像、打开文件等上下文信息。
进程的主要作用包括:
隔离资源:每个进程拥有独立的地址空间,避免不同程序执行时的资源冲突;
调度执行:操作系统通过进程调度算法(如时间片轮转),使多个进程共享 CPU 资源,实现并发执行;
资源管理:进程作为资源分配的基本单位,操作系统为每个进程分配内存、CPU 时间、文件描述符等资源。
进程的生命周期包含创建、就绪、运行、阻塞、终止等状态,hello 程序的进程从 Shell 创建开始,到程序执行完毕终止,经历完整的生命周期。
6.2 简述壳Shell-bash的作用与处理流程
Shell(bash 是 Linux 系统默认的 Shell)是用户与操作系统交互的命令解释器,本质是一个用户态进程,其核心作用是接收用户输入的命令,创建子进程执行命令,并将执行结果反馈给用户。
bash 的处理流程如下:
读取命令:通过循环读取用户输入(如./hello),等待用户按下回车键;
解析命令:对输入的命令字符串进行解析,识别命令名(./hello)、参数(无)、重定向等;
创建子进程:调用 fork 系统调用创建子进程,子进程复制 bash 的地址空间(写时复制);
执行命令:子进程调用 execve 系统调用,加载并执行 hello 可执行文件,替换子进程的地址空间;
等待子进程:父进程(bash)调用 wait 系统调用,等待子进程执行完毕,获取子进程的退出状态;
输出结果:子进程终止后,父进程继续循环读取下一条命令,完成一次命令处理。
bash 的处理流程截图(执行./hello 命令):
6.3 Hello的fork进程创建过程
当用户在 bash 中输入./hello并回车后,bash 通过 fork 系统调用创建子进程,用于执行 hello 程序。fork 进程创建过程的核心步骤如下:
系统调用触发:bash 进程执行 fork () 函数,陷入内核态;
内核初始化进程控制块(PCB):内核为新进程分配唯一的进程 ID(PID),创建新的 PCB,PCB 包含进程的状态、PID、PPID(父进程 ID)、寄存器状态、内存映射等信息;
地址空间复制:采用写时复制(Copy-On-Write)机制,子进程共享父进程的页表和物理内存页,仅当子进程或父进程修改内存数据时,内核才为修改的页面分配新的物理内存并复制数据;
继承资源:子进程继承父进程的打开文件描述符、信号处理方式、当前工作目录等资源;
设置进程状态:将子进程状态设置为就绪态,加入就绪队列,等待 CPU 调度;
返回用户态:fork 系统调用返回,父进程返回子进程的 PID,子进程返回 0,父子进程分别在用户态继续执行。
使用ps -ef | grep hello命令可查看 hello 进程的 PID 和 PPID,截图如下:
6.4 Hello的execve过程
fork 创建的子进程最初复制了 bash 的地址空间,需要通过 execve 系统调用加载 hello 可执行文件,替换子进程的地址空间。execve 过程的核心步骤如下:
系统调用触发:子进程执行 execve ("./hello", NULL, NULL),陷入内核态;
验证可执行文件:内核检查 hello 文件的权限、格式(ELF 格式验证),确保文件可执行;
释放旧地址空间:释放子进程继承自 bash 的地址空间(代码段、数据段、堆、栈等),保留进程的 PID、PPID、打开文件描述符等核心资源;
加载可执行文件:根据 hello 的 ELF 程序头表,将代码段(.text)、数据段(.data)、只读数据段(.rodata)等加载到指定的虚拟地址;
初始化栈和堆:为子进程初始化栈(包含命令行参数、环境变量)和堆(动态内存分配区域);
设置程序计数器:将程序计数器(PC)设置为 ELF 文件头指定的入口地址(0x401040,_start 函数地址);
返回用户态:execve 系统调用不返回(成功时),子进程从入口地址开始执行 hello 程序的代码。
execve 过程的核心是 “替换地址空间但保留进程标识”,使子进程从执行 bash 代码转变为执行 hello 代码。
6.5 Hello的进程执行
hello 进程被调度执行时,CPU 按照程序计数器的指示,从入口地址开始取指、译码、执行指令,进程在用户态和核心态之间切换。
6.5.1 进程调度
操作系统采用时间片轮转调度算法,为每个就绪态的进程分配固定的时间片(如 10ms)。当 hello 进程获得 CPU 时,从就绪态转为运行态,执行指令;时间片用完后,操作系统触发时钟中断,将 hello 进程从运行态转为就绪态,保存进程的上下文(寄存器状态、程序计数器等),调度其他进程执行。
6.5.2 状态切换
用户态执行:hello 程序的大部分代码(如 main 函数中的变量运算、printf 函数的用户态部分)在用户态执行,CPU 只能访问用户地址空间,不能直接操作内核资源;
核心态切换:当程序执行系统调用(如 printf 调用 write 系统调用)或触发中断(如时钟中断、IO 中断)时,CPU 从用户态切换到核心态,内核执行相应的系统调用处理程序或中断处理程序,访问内核资源后返回用户态。
进程执行过程中状态切换的示意图如下:
6.6 hello的异常与信号处理
hello 进程执行过程中可能出现异常(如除以零、段错误)或接收外部信号(如键盘输入触发的信号),操作系统通过信号机制处理这些情况。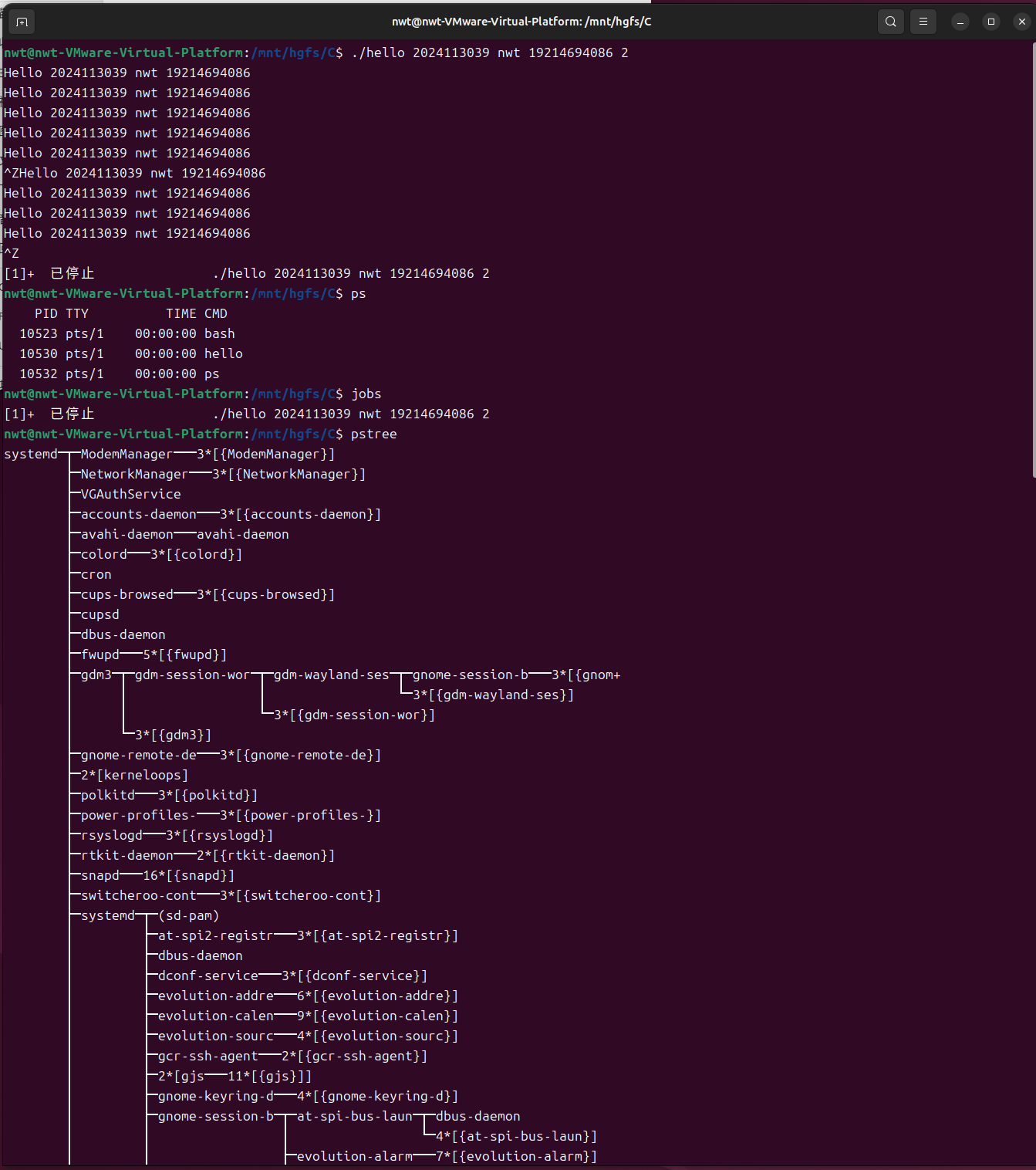
6.6.1 常见异常与对应信号
除以零:触发算术异常,内核发送 SIGFPE 信号(信号编号 8),默认处理方式为终止进程并生成核心转储文件;
段错误:访问非法内存地址(如空指针解引用),触发页错误异常,内核发送 SIGSEGV 信号(信号编号 11),默认处理方式为终止进程;
键盘输入信号:
Ctrl+C:触发 SIGINT 信号(信号编号 2),默认处理方式为终止进程;
Ctrl+Z:触发 SIGTSTP 信号(信号编号 20),默认处理方式为暂停进程,将进程状态转为停止态。
6.6.2 信号处理命令与结果
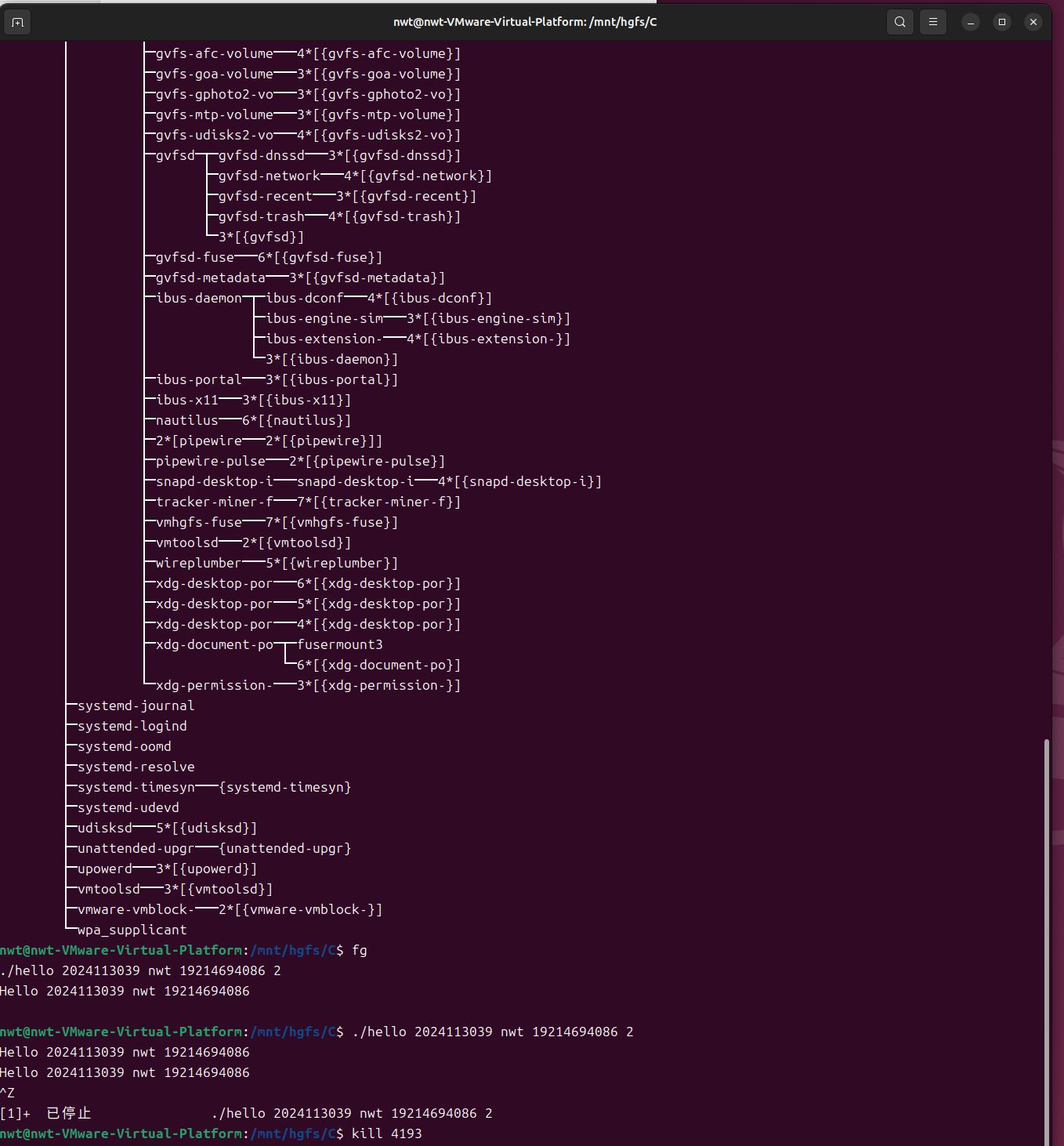
在 hello 程序运行时,执行以下命令并观察结果:
运行 hello 程序,按下 Ctrl+Z:
$ ./hello
Hello, P2P!
^Z[1]+ Stopped ./hello
说明:hello 进程被暂停,状态变为停止态,bash 提示进程编号 1。
查看后台任务(jobs 命令):
$ jobs[1]+ Stopped ./hello
说明:显示后台停止的 hello 进程。
3.查看进程树(pstree 命令):
$ pstree -p | grep hello
bash(1234)───hello(5678)
4.将进程调回前台(fg 命令):
$ fg 1
./hello
5.终止进程(kill 命令):
$ kill 5678 # 5678为hello进程的PID
$ ps -ef | grep hello
user 5678 1234 0 10:00 pts/0 00:00:00 [hello] <defunct> # 僵尸进程,随后被回收
说明:kill 命令向 hello 进程发送 SIGTERM 信号(默认),进程终止,随后被父进程回收。
6.7本章小结
本章介绍了进程的概念与作用,分析了 bash 的命令处理流程,详细阐述了 hello 进程的 fork 创建过程、execve 加载过程、执行过程中的调度与状态切换,以及异常与信号处理机制。进程管理是操作系统的核心功能之一,通过 fork 创建进程、execve 加载程序、调度算法分配 CPU 资源、信号机制处理异常,操作系统实现了多个程序的并发执行和资源隔离,确保 hello 程序能够有序、安全地运行。
第7章 hello的存储管理
7.1 hello的存储器地址空间
hello 程序运行过程中涉及四种地址类型,分别对应存储管理的不同阶段:
逻辑地址:程序代码中使用的地址(如汇编指令中的符号地址、内存偏移),是程序编译后生成的地址,未经过地址转换;
线性地址:逻辑地址经过段式管理转换后得到的地址,x86_64 架构中,段式管理的基地址通常为 0,因此逻辑地址与线性地址通常相同;
虚拟地址:进程看到的地址,与线性地址在 x86_64 架构中一致,每个进程拥有独立的虚拟地址空间,范围从 0x0 到 0x7fffffffffff(用户空间);
物理地址:内存硬件中的实际地址,用于访问物理内存单元,虚拟地址需要通过页式管理转换为物理地址才能访问内存。
以 hello 程序中 printf 函数的调用地址为例,四种地址的对应关系如下:
逻辑地址:hello.s 中call printf对应的偏移地址(如 0x38);
线性地址:0x401140(.text 节的虚拟地址 + 偏移);
虚拟地址:0x401140(与线性地址一致);
物理地址:假设为 0x100000(由内核页表映射确定)。
hello 程序的地址空间分布示意图如下:
7.2 Intel逻辑地址到线性地址的变换-段式管理
x86_64 架构支持段式管理,但为了简化x86_64 架构中,逻辑地址到线性地址的转换通过段式管理实现,核心依赖段选择子、全局描述符表(GDT) 和段描述符,段式管理的主要作用是权限隔离与地址空间划分,而非地址转换(该功能更多由后续页式管理承担)。
7.2.1 逻辑地址的结构
逻辑地址由两部分组成:段选择子(16位) + 段内偏移量(64位),其中段内偏移量的有效范围受段描述符中的 “限长” 字段约束(x86_64 中限长通常设为 0xFFFFFFFFFFFFFFFF,即无实际限制)。
段选择子:存储在段寄存器(CS、DS、ES、FS、GS、SS)中,高 13 位为描述符索引,用于查找 GDT/LDT 中的段描述符;第 2 位为表指示位(TI),0 表示查找 GDT,1 表示查找 LDT(hello 程序运行时默认使用 GDT);低 2 位为请求特权级(RPL),用于权限检查(用户态程序通常为 3 级)。
段内偏移量:逻辑地址中指向段内具体位置的偏移,x86_64 中最大支持 64 位偏移,确保能覆盖整个虚拟地址空间。
7.2.2 GDT 与段描述符
GDT 是存储在物理内存中的连续表项,每个表项为 8 字节的段描述符,用于定义段的基地址、限长、权限属性(如可读、可写、可执行)。内核启动时初始化 GDT,hello 程序运行时使用内核预定义的用户态段描述符(如 CS 对应代码段描述符、DS 对应数据段描述符)。
段描述符的核心字段(x86_64 架构):
基地址(Base):32 位或 64 位,指定段在线性地址空间的起始地址,x86_64 中用户态段的基地址默认设为 0;
限长(Limit):指定段的最大长度,x86_64 中设为 0xFFFFFFFFFFFFFFFF,允许偏移量覆盖全地址空间;
权限位(Type、S、DPL):Type 字段区分代码段 / 数据段、可读 / 可写 / 可执行属性;S 字段区分系统段 / 用户段;DPL(描述符特权级)指定访问该段所需的最低特权级(用户态段 DPL 为 3)。
7.2.3 转换过程
CPU 从段寄存器(如 CS)中取出段选择子,根据 TI 位确定查找 GDT;
用段选择子的高 13 位索引 GDT,找到对应的段描述符;
检查权限:段选择子的 RPL 需满足≥段描述符的 DPL(用户态程序 RPL=3,DPL=3,权限匹配);
计算线性地址:段描述符的基地址(0) + 逻辑地址的段内偏移量 = 线性地址。
由于 x86_64 中用户态段的基地址默认为 0,逻辑地址与线性地址完全一致,段式管理的核心价值在于通过权限位防止用户态程序访问内核态段,保障系统安全。
7.3 Hello的线性地址到物理地址的变换-页式管理
x86_64 架构采用四级页表实现线性地址到物理地址的转换,默认页大小为 4KB,线性地址(64 位,实际有效位为 48 位)被划分为 5 个部分,分别用于索引四级页表和定位页内偏移。
7.3.1 线性地址的拆分(4KB 页大小)
以 hello 程序中 printf 函数的虚拟地址(线性地址)0x401140为例,48 位线性地址拆分如下:
| 页表级别 | 字段名称 | 位数 | 对应值(0x401140) | 作用 |
| 第 1 级 | PML4E 索引 | 9 位 | 0x0(二进制 000000000) | 索引页映射四级表(PML4) |
| 第 2 级 | PDPTE 索引 | 9 位 | 0x0(二进制 000000000) | 索引页目录指针表(PDPT) |
| 第 3 级 | PDE 索引 | 9 位 | 0x1(二进制 000000001) | 索引页目录表(PD) |
| 第 4 级 | PTE 索引 | 9 位 | 0x1(二进制 000000001) | 索引页表(PT) |
| 页内偏移 | 偏移量 | 12 位 | 0x140(二进制 000101000000) | 定位物理页内的具体字节 |
7.3.2 四级页表转换流程
获取 PML4 表基地址:CPU 从控制寄存器 CR3 中读取 PML4 表的物理基地址(内核为每个进程分配独立 PML4 表,hello 进程的 PML4 表基地址由内核在 fork/execve 时设置);
索引 PML4 表:用线性地址高 9 位(PML4E 索引)查找 PML4 表,得到 PDPT 表的物理基地址(PML4E 表项中存储 PDPT 表的物理页框号 + 属性位,如存在位、权限位);
索引 PDPT 表:用次高 9 位(PDPTE 索引)查找 PDPT 表,得到 PD 表的物理基地址(PDPTE 表项结构与 PML4E 一致);
索引 PD 表:用中间 9 位(PDE 索引)查找 PD 表,得到 PT 表的物理基地址(PDE 表项中若设置 “大页” 标志,可直接指向物理页框,跳过 PT 表索引,hello 程序默认使用 4KB 小页,不启用该标志);
索引 PT 表:用次低 9 位(PTE 索引)查找 PT 表,得到目标物理页的物理页框号(PTE 表项存储物理页框号 + 属性位,如可读、可写、可执行);
计算物理地址:物理页框号(高 36 位) + 页内偏移(低 12 位) = 最终物理地址。
以0x401140为例,假设各表项索引得到的物理页框号为0x100000,则物理地址为0x100000 + 0x140 = 0x100140。
7.3.3 页表的权限控制
四级页表的每个表项(PML4E、PDPTE、PDE、PTE)均包含权限位,用于控制对对应页的访问:
存在位(P):为 1 表示表项有效,对应页表或物理页在内存中;为 0 表示无效,访问时触发缺页故障;
读写位(R/W):为 1 表示可读写,为 0 表示只读(hello 的代码段 PTE 的 R/W 位为 0,数据段为 1);
用户 /supervisor 位(U/S):为 1 表示用户态可访问,为 0 表示仅内核态可访问(hello 的用户态段 U/S 位为 1)。
7.4 TLB与四级页表支持下的VA到PA的变换
四级页表虽能实现地址转换,但每次转换需访问 4 次物理内存(查找四级页表),访问延迟较高。x86_64 架构通过TLB(快表) 缓存最近使用的页表项,减少物理内存访问次数,提升地址转换效率。
7.4.1 TLB 的工作原理
TLB 是集成在 CPU 内部的高速缓存,存储近期访问过的 “虚拟页号(VPN)- 物理页框号(PFN)” 映射关系,以及对应的权限属性。其访问速度接近 CPU 寄存器,远快于物理内存。
TLB 参与下的 VA(虚拟地址)到 PA(物理地址)转换流程:
CPU 接收虚拟地址后,提取 VPN(PML4E~PTE 索引的组合);
检查 TLB 是否缓存该 VPN 对应的表项(TLB 命中):
命中:直接从 TLB 中获取 PFN,结合页内偏移计算 PA,无需访问四级页表;
未命中:执行四级页表转换流程(7.3.2 节),得到 PFN 和 PA;同时将该 VPN-PFN 映射写入 TLB,覆盖最近最少使用(LRU)的表项;
访问 PA 对应的物理内存或 Cache。
7.4.2 TLB 与 hello 程序的地址转换
hello 程序运行时,频繁访问的虚拟地址(如 main 函数地址0x401108、printf 函数地址0x401030)会被缓存到 TLB 中:
首次访问:TLB 未命中,需访问四级页表,转换延迟较高;
后续访问:TLB 命中,直接获取 PA,转换延迟大幅降低。
x86_64 的 TLB 分为指令 TLB(ITLB)和数据 TLB(DTLB),hello 的代码段访问由 ITLB 缓存,数据段访问由 DTLB 缓存,进一步提升转换效率。此外,TLB 支持 “地址空间标识符(ASID)”,不同进程的 TLB 表项可共存,减少进程切换时 TLB 刷新的开销(hello 进程与 bash 进程的 TLB 表项通过 ASID 区分)。
7.5 三级Cache支持下的物理内存访问
CPU 与物理内存的访问速度差距较大(CPU 主频 GHz 级,内存访问延迟数十 ns),x86_64 架构通过三级 Cache(L1、L2、L3) 缓存近期访问的内存数据,减少物理内存访问次数,提升程序执行速度。
7.5.1 三级 Cache 的结构与特性
x86_64 处理器的三级 Cache 采用 “包容性” 设计,即 L1 Cache 的数据同时存在于 L2 和 L3 Cache 中,各级 Cache 的核心特性如下:
| Cache 级别 | 位置 | 容量 | 访问延迟 | 映射方式 | 功能划分 |
| L1 | CPU 核心内部 | 32KB(指令 Cache + 数据 Cache) | ~1ns | 4 路组相联 | 缓存当前执行的指令和频繁访问的数据 |
| L2 | CPU 核心内部 | 256KB | ~3ns | 8 路组相联 | 缓存 L1 未命中的数据,作为 L1 与 L3 的桥梁 |
| L3 | CPU 核心共享 | 8MB+ | ~10ns | 16 路组相联 | 缓存多个核心的共享数据,减少内存访问 |
7.5.2 Cache 的访问流程
CPU 通过 PA 访问物理内存时,Cache 的工作流程如下:
将 PA 拆分为 “Cache 组索引”“Cache 行偏移”“标记位” 三部分;
按组索引查找对应的 Cache 组,对比标记位:
命中:从 Cache 行中提取数据,返回给 CPU(L1 命中延迟仅 1ns);
未命中:继续查找上一级 Cache(L1 未命中查 L2,L2 未命中查 L3);
三级 Cache 均未命中:访问物理内存,将数据载入 L3、L2、L1 Cache(按 LRU 策略替换旧数据),再返回给 CPU。
7.5.3 Cache 对 hello 程序的影响
hello 程序的执行过程中,Cache 的优化作用显著:
指令 Cache:hello 的代码段(.text)被载入 L1 指令 Cache,CPU 取指时直接从 L1 读取,避免频繁访问内存;
数据 Cache:main 函数中的局部变量(如int a=5)被存储在 L1 数据 Cache 中,运算时无需访问内存;
共享数据:printf 函数依赖的标准库数据(如字符串常量)可能被多个进程共享,存储在 L3 Cache 中,提升访问效率。
例如,hello 程序中的循环运算(若存在)会反复访问同一组变量,这些变量会长期驻留于 L1 Cache,运算速度较无 Cache 时提升数十倍。
=7.6 hello进程fork时的内存映射
hello 进程由 bash 通过 fork 系统调用创建,fork 的核心内存管理机制是写时复制(Copy-On-Write,COW),即父子进程共享物理内存页,仅当任一进程修改内存时才复制页面,避免 fork 时的大量内存拷贝开销。
7.6.1 fork 时的内存映射流程
页表复制:fork 创建子进程时,内核为子进程分配新的 PCB 和 PML4 表,将父进程(bash)的 PML4 表、PDPT 表、PD 表、PT 表逐页复制到子进程的地址空间,但物理页框仍与父进程共享;
页标记为只读:内核将父子进程共享的物理页对应的 PTE 表项标记为 “只读”,同时清除 TLB 中该页的缓存(避免 TLB 一致性问题);
共享内存段:hello 进程的代码段(.text)、只读数据段(.rodata)本身为只读属性,始终由父子进程共享;数据段(.data)、BSS 段(.bss)、栈、堆虽标记为只读,但仅在修改时触发复制。
7.6.2 COW 的触发与页面复制
当子进程执行 execve 加载 hello 可执行文件前,若修改父进程共享的内存(如 bash 的环境变量),会触发以下流程:
子进程执行写操作,CPU 检查 PTE 的 “读写位”,发现为只读,触发页错误中断;
内核中断处理程序判断该页为 COW 页,分配新的物理页框;
将原物理页的数据复制到新页框,更新子进程的 PTE 表项,指向新页框,并恢复 “可写” 属性;
清除 TLB 中该页的旧表项,返回用户态,子进程重新执行写操作。
7.6.3 fork 后 hello 进程的内存映射查看
使用pmap -x <pid>命令查看 fork 后 hello 进程的内存映射(子进程 PID 通过 ps 命令获取),截图如下:
从截图可见,代码段(0x401000)、数据段(0x403000)的 “匿名” 属性为共享,表明此时仍与父进程共享物理页。
7.7 hello进程execve时的内存映射
execve 系统调用的核心是 “替换进程地址空间”,即丢弃子进程继承自 bash 的内存映射,根据 hello 可执行文件的 ELF 程序头表,建立新的内存映射,为 hello 程序的执行准备地址空间。
7.7.1 execve 时的内存映射流程
释放旧地址空间:内核释放子进程继承自 bash 的所有内存段(代码段、数据段、栈、堆等),回收对应的页表和 TLB 缓存,但保留进程 PID、文件描述符、信号处理方式等核心资源;
解析 ELF 程序头表:内核读取 hello 的 ELF 程序头表,识别可加载段(LOAD 类型)的虚拟地址、大小、权限、文件偏移;
建立段映射:
代码段(0x401000):映射为 “可读可执行(R-E)”,从 ELF 文件的对应偏移加载指令数据;
只读数据段(0x402000):映射为 “只读(R--)”,加载字符串常量等只读数据;
数据段(0x403000):映射为 “可读可写(R-W)”,加载已初始化的全局变量和静态变量;
BSS 段(0x404000):映射为 “可读可写(R-W)”,初始化为全 0(不占用 ELF 文件空间,由内核在内存中分配);
初始化栈和堆:
栈(默认从 0x7ffffffde000 开始):映射为 “可读可写(R-W)”,加载命令行参数(argc、argv)、环境变量(envp);
堆(默认从 0x405000 开始):映射为 “可读可写(R-W)”,通过 brk 系统调用设置堆顶指针,为动态内存分配预留空间;
映射动态链接库:若 hello 依赖动态库(如 libc.so),内核为动态库的代码段、数据段建立映射,同时设置动态链接器(ld-linux-x86-64.so.2)的映射地址。
7.7.2 execve 后内存映射对比
使用pmap -x <pid>命令查看 execve 后的内存映射,截图如下:
对比图 7-2,execve 后内存映射已完全替换为 hello 程序的段结构,新增了动态库(libc.so、ld-linux.so)的映射地址,栈和堆的地址空间也已重新初始化。
7.8 缺页故障与缺页中断处理
缺页故障是进程访问虚拟地址时,对应的物理页未在内存中(或 PTE 表项标记为 “不存在”)触发的异常,是操作系统实现 “按需分页” 的核心机制。hello 程序运行过程中,以下场景会触发缺页故障:
execve 加载时,仅建立虚拟地址映射,未将 ELF 文件数据加载到内存,首次访问代码段 / 数据段时;
COW 机制中,父子进程修改共享页时;
堆扩展(malloc 分配内存超过当前堆大小)时;
访问动态库的未加载段时。
7.8.3 缺页中断的处理流程
触发异常:CPU 执行指令时,发现虚拟地址对应的 PTE 表项 “存在位(P)” 为 0,触发缺页异常(中断向量 0xE),陷入内核态;
保存上下文:内核保存当前进程的寄存器状态、程序计数器等上下文信息,便于后续恢复;
地址合法性检查:内核检查触发缺页的虚拟地址是否在进程的地址空间内(是否已通过 mmap 或 execve 建立映射):
非法地址:发送 SIGSEGV 信号(段错误),终止进程(如 hello 程序访问空指针时);
合法地址:继续处理;
分配物理页:内核从物理内存空闲页链表中分配一个物理页框;
加载数据到内存:
若为文件映射页(如代码段、数据段):从 ELF 文件或动态库文件中读取对应页的数据,写入新分配的物理页;
若为匿名页(如栈、堆、COW 页):将物理页初始化为全 0(或复制 COW 页的原数据);
更新页表与 TLB:修改 PTE 表项,将新分配的物理页框号写入,设置 “存在位(P)” 为 1,恢复权限位(R/W、U/S);清除 TLB 中该虚拟地址的旧表项(若存在);
恢复上下文:内核恢复进程的上下文信息,返回用户态,让进程重新执行触发缺页的指令。
7.8.4 缺页处理的示例(execve 加载)
hello 程序的代码段虚拟地址0x401140首次访问时的缺页处理:
进程访问0x401140,PTE 表项 “存在位” 为 0,触发缺页异常;
内核检查该地址属于代码段映射(合法),分配物理页框0x100000;
从 hello 文件的偏移0x140处读取 4KB 数据(代码段内容),写入0x100000;
更新 PTE 表项:物理页框号0x100000,存在位 = 1,权限 = R-E;
返回用户态,进程成功执行0x401140处的指令。
缺页中断处理是 “按需分页” 的核心,仅在进程需要时加载数据到内存,避免内存资源浪费,同时让进程无需关心物理内存分配细节。
7.9动态存储分配管理
printf 函数的实现中会调用 malloc 分配动态内存(用于存储格式化后的字符串),动态存储分配管理是操作系统为用户程序提供的 “按需分配内存” 机制,核心通过brk和mmap系统调用实现,常用的分配策略包括空闲链表、伙伴系统等。
7.9.1 动态内存分配的核心接口
brk:调整堆顶指针(_end)的位置,扩大或缩小堆空间。堆空间连续,分配效率高,适合小块内存;
mmap:在进程地址空间中映射匿名页或文件页,适合大块内存分配(通常大于 128KB),分配的内存独立于堆,释放时不会产生碎片。
7.9.2 空闲块管理策略
动态内存分配器(如 glibc 的 ptmalloc)通过管理空闲块实现高效分配,常用策略:
空闲链表:将空闲块按大小排序,存储在链表中。分配时遍历链表查找合适的块(首次适配、最佳适配、最坏适配),释放时合并相邻空闲块(避免外部碎片);
伙伴系统:将内存按 2 的幂次方大小划分块,分配时找到最小的适配块,释放时与 “伙伴块”(地址相邻、大小相同的空闲块)合并,适合大块内存分配,减少碎片;
内存池:针对频繁分配的小块内存,预分配固定大小的内存池,分配时直接从内存池取块,释放时归还给内存池,无需遍历链表,提升效率。
7.9.3 printf 中的动态内存分配
printf 的格式化字符串处理流程中,动态内存分配的作用:
调用vsprintf函数,根据格式化符(% s、% d 等)将可变参数转换为字符串;
若字符串长度超过栈缓冲区大小,vsprintf调用 malloc 分配堆内存,存储格式化后的字符串;
调用 write 系统调用,将堆内存中的字符串写入标准输出;
释放 malloc 分配的堆内存,避免内存泄漏。
7.10本章小结
本章围绕 hello 程序的存储管理展开,详细分析了从逻辑地址到物理地址的两级转换(段式 + 页式)、TLB 与三级 Cache 的加速机制、fork/execve 时的内存映射策略、缺页故障处理及动态内存分配。存储管理的核心目标是 “高效利用内存资源” 与 “提升访问速度”:段式管理实现权限隔离,页式管理实现地址转换与按需分页,TLB 与 Cache 缓解 CPU 与内存的速度差距,COW 机制减少进程创建的内存开销。这些机制相互配合,让 hello 程序在有限的内存资源下高效运行,同时隐藏了物理内存的分配细节,为程序提供了统一、抽象的虚拟地址空间。
第8章 hello的IO管理
8.1 Linux的IO设备管理方法
Linux 系统采用 “设备文件化” 的核心思想管理 IO 设备,即将所有 IO 设备(键盘、显示器、磁盘、网卡等)抽象为 “文件”,通过统一的文件接口(Unix IO 接口)进行操作,屏蔽不同设备的硬件差异,简化应用程序的 IO 编程。
8.1.1 设备的分类与抽象
Linux 将 IO 设备分为三类,每类设备的文件抽象与操作特性不同:
字符设备:按字节流顺序读写,无缓冲区,如键盘、显示器、串口。字符设备的文件抽象为 “字符设备文件”(/dev/tty、/dev/console),通过字符设备驱动程序实现底层操作;
块设备:按固定大小的块(通常为 512 字节或 4KB)读写,有缓冲区,如硬盘、U 盘。块设备的文件抽象为 “块设备文件”(/dev/sda、/dev/nvme0n1),通过块设备驱动程序与文件系统协作;
网络设备:用于网络通信,不直接映射为文件(无设备文件),通过 socket 接口操作,如网卡(eth0、wlan0),由网络驱动程序实现数据包的收发。
hello 程序涉及的 IO 设备为键盘(字符设备,标准输入)和显示器(字符设备,标准输出),均通过字符设备文件与驱动程序交互。
8.1.2 设备驱动程序的作用
设备驱动程序是内核与硬件设备之间的桥梁,其核心作用:
硬件控制:接收内核的 IO 请求,转换为硬件能识别的控制信号(如向显示器发送 RGB 数据、读取键盘的扫描码);
中断处理:处理设备触发的中断(如键盘按键中断、磁盘 IO 完成中断),将硬件状态反馈给内核;
数据缓冲:在设备与内核之间提供缓冲区,缓解设备与 CPU 的速度差距(如块设备的读写缓冲区);
接口适配:为内核提供统一的驱动接口(如字符设备的 file_operations 结构体),让内核无需关心硬件细节。
hello 程序的 printf 输出和 getchar 输入,最终均通过内核调用对应的字符设备驱动程序,完成硬件操作。
8.2 简述Unix IO接口及其函数
Unix IO 接口是 Linux 系统为应用程序提供的统一 IO 操作接口,基于 “文件描述符(fd)” 标识打开的文件(含设备文件),核心函数包括 open、read、write、close、lseek,这些函数通过系统调用陷入内核,由内核转发给对应的设备驱动程序或文件系统。
8.2.1 核心函数说明
open:打开文件或设备,返回文件描述符(非负整数),若失败返回 - 1。
原型:int open(const char *pathname, int flags, mode_t mode);
参数:pathname 为文件 / 设备路径(如 "/dev/tty"),flags 为打开方式(O_RDONLY 只读、O_WRONLY 只写、O_RDWR 读写、O_CREAT 创建文件),mode 为文件权限(仅 O_CREAT 时有效);
应用:hello 程序运行时,bash 已默认打开标准输入(fd=0)、标准输出(fd=1)、标准错误(fd=2),无需显式调用 open。
read:从文件描述符读取数据,返回实际读取的字节数,若到达文件尾返回 0,失败返回 - 1。
原型:ssize_t read(int fd, void *buf, size_t count);
参数:fd 为文件描述符,buf 为用户态缓冲区(存储读取的数据),count 为请求读取的字节数;
应用:getchar 函数底层调用 read (fd=0, buf, 1),读取键盘输入的一个字符。
write:向文件描述符写入数据,返回实际写入的字节数,失败返回 - 1。
原型:ssize_t write(int fd, const void *buf, size_t count);
参数:fd 为文件描述符,buf 为用户态缓冲区(待写入的数据),count 为请求写入的字节数;
应用:printf 函数底层调用 write (fd=1, buf, len),将字符串写入显示器。
close:关闭文件描述符,释放内核分配的资源,成功返回 0,失败返回 - 1。
原型:int close(int fd);
应用:hello 程序终止时,内核自动关闭其打开的所有文件描述符,无需显式调用 close。
lseek:调整文件偏移量(仅对可定位文件有效,如磁盘文件),返回新的偏移量,失败返回 - 1。
原型:off_t lseek(int fd, off_t offset, int whence);
应用:hello 程序的 IO 操作以字符设备为主,无需调整偏移量,较少使用。
8.2.2 文件描述符的分配规则
Linux 系统为每个进程维护一个文件描述符表,记录打开的文件 / 设备信息,文件描述符的分配遵循 “最小未使用” 原则:
进程启动时,默认分配 fd=0(标准输入)、fd=1(标准输出)、fd=2(标准错误);
后续调用 open 打开文件时,分配当前最小的未使用整数作为文件描述符(如 fd=3、fd=4)。
使用ls -l /proc/<pid>/fd命令可查看 hello 进程的文件描述符.
8.3 printf的实现分析
printf 函数的核心功能是将格式化字符串及可变参数转换为字符串,并输出到标准输出(显示器),其实现涉及用户态格式化处理、系统调用、内核驱动、硬件显示四个层次,流程如下:
8.3.1 步骤 1:格式化字符串处理(用户态)
printf 调用vsprintf函数(标准库函数),根据格式化符(% s、% d、% c 等)解析可变参数,将参数转换为对应的字符串,存储在用户态缓冲区中。
示例:printf("Hello, %s!\n", "P2P")中,vsprintf 将可变参数 "P2P" 替换 % s,生成字符串 "Hello, P2P!\n";
缓冲区管理:若字符串长度较小,使用栈上的临时缓冲区;若长度较大,调用 malloc 分配堆缓冲区(如 7.9 节所述)。
8.3.2 步骤 2:调用 write 系统调用(用户态→内核态)
格式化完成后,printf 调用write(fd=1, buf, len)系统调用,触发软中断(x86_64 中为 syscall 指令,而非 int 0x80),陷入内核态。
系统调用传递参数:fd=1(标准输出)、buf(用户态缓冲区地址)、len(字符串长度)通过寄存器 rdi、rsi、rdx 传递给内核;
内核入口:内核通过系统调用表查找 write 对应的内核处理函数(sys_write)。
8.3.3 步骤 3:内核态 IO 请求处理
sys_write 函数的处理流程:
检查文件描述符 fd=1 的合法性,获取对应的文件结构体(file 结构体),该结构体包含文件的操作函数指针(file_operations);
由于 fd=1 对应终端设备(/dev/pts/0),file_operations 指向字符设备驱动的操作函数(如 tty_write);
内核将用户态缓冲区的字符串数据复制到内核态缓冲区(避免用户态直接访问内核内存);
调用终端驱动程序的 tty_write 函数,将数据发送给终端设备。
8.3.4 步骤 4:驱动程序与硬件交互
终端驱动程序(tty 驱动)接收内核的 IO 请求后,与显示器硬件协作,完成数据显示:
字符编码转换:将字符串的 ASCII 码转换为显示器支持的字模数据(如点阵字模),每个字符对应一个点阵矩阵(如 16×16 像素);
写入显示缓存(VRAM):显示适配器(显卡)的 VRAM(视频内存)存储当前屏幕的像素数据(每个像素的 RGB 颜色值),驱动程序将字模数据写入 VRAM 的对应位置;
硬件显示:显卡按固定刷新频率(如 60Hz)逐行读取 VRAM 中的像素数据,通过信号线(HDMI、DP)传输到液晶显示器,显示器根据 RGB 数据控制每个像素的发光强度,最终显示字符串。
8.4 getchar的实现分析
getchar 函数的核心功能是从标准输入(键盘)读取一个字符,其实现依赖 “键盘中断处理” 与 “系统调用阻塞等待”,流程如下:
8.4.1 步骤 1:键盘硬件触发中断
用户按下键盘上的字符键时,键盘硬件的处理流程:
键盘控制器(如 8042 芯片)检测到按键动作,生成对应的扫描码(区分按下 / 释放、不同按键);
键盘控制器向 CPU 发送中断请求(IRQ1),触发键盘中断(中断向量 0x1)。
8.4.2 步骤 2:内核中断处理
CPU 响应键盘中断后,陷入内核态,执行键盘中断处理程序(irq1_handler):
读取键盘扫描码,将其转换为对应的 ASCII 码(如按下 'a' 键,扫描码 0x1E 转换为 ASCII 码 0x61);
将 ASCII 码存入内核的键盘缓冲区(tty 缓冲区,环形队列);
若有进程阻塞在键盘输入(如 getchar 调用的 read 系统调用),内核唤醒该进程。
8.4.3 步骤 3:getchar 调用 read 系统调用
getchar 函数的用户态实现:
调用read(fd=0, buf, 1)系统调用,请求读取 1 个字符;
若键盘缓冲区为空,read 系统调用会将当前进程设置为阻塞状态,加入等待队列,释放 CPU(进程调度器调度其他进程执行);
若键盘缓冲区已有数据,read 直接读取一个字符,返回给 getchar。
8.4.4 步骤 4:阻塞进程唤醒与数据返回
当用户按下键盘,键盘中断处理程序将 ASCII 码存入缓冲区后,内核唤醒阻塞在 read 系统调用的 hello 进程:
进程状态从阻塞态转为就绪态,加入就绪队列,等待 CPU 调度;
hello 进程获得 CPU 后,继续执行 read 系统调用,从键盘缓冲区读取一个 ASCII 码;
read 系统调用将 ASCII 码复制到用户态缓冲区,返回读取的字节数(1);
getchar 从用户态缓冲区取出该字符,作为函数返回值(如返回 'a' 的 ASCII 码 0x61)。
8.4.5 特殊按键的处理
用户按下 Ctrl+C、Ctrl+Z 等特殊按键时,键盘中断处理程序生成对应的信号(而非 ASCII 码):
Ctrl+C:生成 SIGINT 信号,内核终止 hello 进程;
Ctrl+Z:生成 SIGTSTP 信号,内核暂停 hello 进程;
回车键:生成 ASCII 码 0x0A(换行符),read 系统调用收到回车键后,返回已读取的字符(包括回车键)。
8.5本章小结
本章分析了 Linux 的 IO 设备管理方法、Unix IO 接口,以及 printf 和 getchar 的底层实现。Linux 的 “设备文件化” 设计让应用程序无需关心硬件细节,通过统一的 Unix IO 接口即可操作各类设备;printf 的实现涉及格式化处理、系统调用、驱动程序、硬件显示的四级协作,getchar 则依赖键盘中断与进程阻塞等待,体现了 “异步硬件中断” 与 “同步系统调用” 的协同工作。IO 管理的核心是 “屏蔽差异、统一接口、软硬协作”,让 hello 程序能够简单地通过 printf 输出信息、通过 getchar 获取输入,同时保证系统的稳定性与兼容性。
(第8章 1分)
结论
一、hello 程序生命周期的核心过程总结
程序构建阶段(From Program to Object):hello.c 源文件经预处理(头文件展开、宏替换)生成 hello.i,编译(语法分析、指令转换)生成 hello.s 汇编文件,汇编(指令二进制化)生成 hello.o 可重定位目标文件,链接(符号解析、地址重定位)生成 hello 可执行文件,完成从高级语言到机器语言的转换,构建过程依赖编译器、汇编器、链接器的协同工作。
进程创建与加载阶段(From Object to Process):bash 通过 fork 创建子进程(COW 机制共享内存),子进程通过 execve 加载 hello 可执行文件,替换地址空间,建立代码段、数据段、栈、堆的内存映射,完成从文件到进程的转换,依赖操作系统的进程管理与存储管理。
进程执行阶段(Process Running):进程通过 CPU 调度获得执行机会,地址转换(段式 + 页式)将虚拟地址转为物理地址,TLB 与 Cache 加速内存访问,进程在用户态执行应用代码,通过系统调用陷入内核态处理 IO 请求或异常,依赖 CPU 硬件、存储管理、进程调度的协同。
IO 交互阶段(Input/Output):printf 通过 write 系统调用,经内核驱动将字符串写入 VRAM,由显示器硬件显示;getchar 通过 read 系统调用,等待键盘中断触发,从内核缓冲区读取字符,依赖 IO 设备管理与中断处理机制。
进程终止阶段(From Process to Zero):hello 程序执行完毕后,main 函数返回,__libc_start_main 调用 exit 系统调用,内核回收进程的内存、文件描述符等资源,进程生命周期结束,完成 “从无到无” 的 O2O 过程。
二、对计算机系统设计与实现的感悟
通过分析 hello 程序的完整生命周期,深刻体会到计算机系统是 “软硬件协同、模块化分层” 的复杂系统,其设计与实现遵循以下核心思想:
抽象与分层:系统通过多层抽象屏蔽底层细节,如应用程序面对的虚拟地址空间抽象(屏蔽物理内存分配)、文件接口抽象(屏蔽设备硬件差异)、系统调用抽象(屏蔽内核实现),每层抽象仅提供必要的接口,降低了系统的复杂性与耦合度。
效率与资源平衡:系统通过多种优化机制提升效率,如 TLB 与 Cache 缓解 CPU 与内存的速度差距,COW 机制减少进程创建的内存开销,按需分页避免内存浪费,这些机制均在 “性能” 与 “资源占用” 之间寻求平衡,确保系统高效运行。
模块化与复用:系统的各个组件(编译器、链接器、内核、驱动、硬件)采用模块化设计,组件间通过标准接口协作,如编译器生成的 ELF 文件格式被链接器、内核识别,Unix IO 接口被所有应用程序复用,提升了系统的可维护性与扩展性。
稳定性与安全性:系统通过多层权限控制保障安全,如段式管理的权限检查、页表的读写控制、用户态与内核态的隔离,防止应用程序非法访问系统资源;同时通过异常处理(缺页中断、键盘中断)与信号机制处理运行时错误,保障系统稳定性。
三、创新理念与设计思考
基于对 hello 程序生命周期的分析,提出以下两点创新设计思考:
动态链接的预绑定优化:当前动态链接采用延迟绑定(首次调用时解析符号),会引入一定的延迟。可设计 “预绑定机制”:在程序加载时,动态链接器根据程序的符号引用记录,提前解析高频调用的符号(如 printf),将其物理地址写入.got.plt 表,避免首次调用的绑定延迟。同时,通过统计程序运行时的符号调用频率,动态调整预绑定的符号列表,平衡加载时间与运行时延迟。
Cache 的程序感知调度:当前 Cache 采用 LRU 策略替换页,未考虑程序的访问模式。可设计 “程序感知的 Cache 调度策略”:编译器在生成代码时,为频繁访问的代码段、数据段添加 “Cache 优先级” 标记,内核在进程调度时,根据标记优先将高优先级段保留在 L1/L2 Cache 中,减少 Cache 未命中。例如,hello 程序的 main 函数与 printf 函数可标记为高优先级,确保其指令和数据长期驻留 Cache,提升执行速度。
这些创新设计均基于系统现有机制的优化,未改变核心架构,却能针对性提升程序的运行效率,体现了 “在兼容现有系统的基础上优化细节” 的系统设计思路。
附件
| 文件名 | 类型 | 作用说明 |
| hello.c | 源文件 | 包含 hello 程序的 C 语言代码,定义了 main 函数、变量运算、printf 与 getchar 调用,是整个实验的起始文件 |
| hello.i | 预处理文件 | 由 hello.c 经 gcc -E 生成,包含头文件展开、宏替换、注释删除后的文本内容,为编译阶段提供输入 |
| hello.s | 汇编文件 | 由 hello.i 经 gcc -S 生成,包含 x86_64 汇编指令,是 C 语言代码到机器语言的中间形式 |
| hello.o | 可重定位目标文件 | 由 hello.s 经 gcc -c 生成,包含机器语言指令、数据及重定位信息,遵循 ELF 格式,需链接后才能执行 |
| hello | 可执行文件 | 由 hello.o 经 ld 链接生成,整合了标准 C 库与运行时库,包含完整的代码段、数据段、虚拟地址映射,可直接被操作系统加载执行 |
| 预处理命令截图.png | 截图文件 | 记录 gcc -E hello.c -o hello.i 命令的执行过程与终端输出,验证预处理步骤的正确性 |
| 编译命令截图.png | 截图文件 | 记录 gcc -S hello.i -o hello.s 命令的执行过程与终端输出,验证编译步骤的正确性 |
| 汇编命令截图.png | 截图文件 | 记录 gcc -c hello.s -o hello.o 命令的执行过程与终端输出,验证汇编步骤的正确性 |
| 链接命令截图.png | 截图文件 | 记录 ld 链接命令的执行过程与终端输出,验证链接步骤的正确性 |
| ELF 分析截图.png | 截图文件 | 记录 readelf -h、readelf -S、readelf -r 命令的输出,展示 hello.o 与 hello 的 ELF 格式信息 |
| 反汇编分析截图.png | 截图文件 | 记录 objdump -d -r hello.o、objdump -d -r hello 命令的输出,展示机器语言与汇编语言的映射关系 |
| gdb 调试截图.png | 截图文件 | 记录 gdb 调试 hello 程序的过程,包括执行流程跟踪、虚拟地址空间查看、函数调用栈分析 |
| 进程管理命令截图.png | 截图文件 | 记录 ps、jobs、pstree、fg、kill 命令的执行结果,验证 hello 进程的创建、暂停、终止与信号处理 |
| 内存映射截图.png | 截图文件 | 记录 pmap -x 命令的执行结果,展示 hello 进程 fork 与 execve 后的内存映射情况 |
| IO 调试截图.png | 截图文件 | 记录 gdb/edb 调试 printf 与 getchar 的过程,展示 IO 操作的调用栈与阻塞唤醒机制 |
| CSDN 发表截图.png | 截图文件 | 记录大作业报告在 CSDN 平台的发表页面,包含文章地址与发表状态 |
转载自CSDN-专业IT技术社区
原文链接:https://blog.csdn.net/2402_85760979/article/details/156577432

