
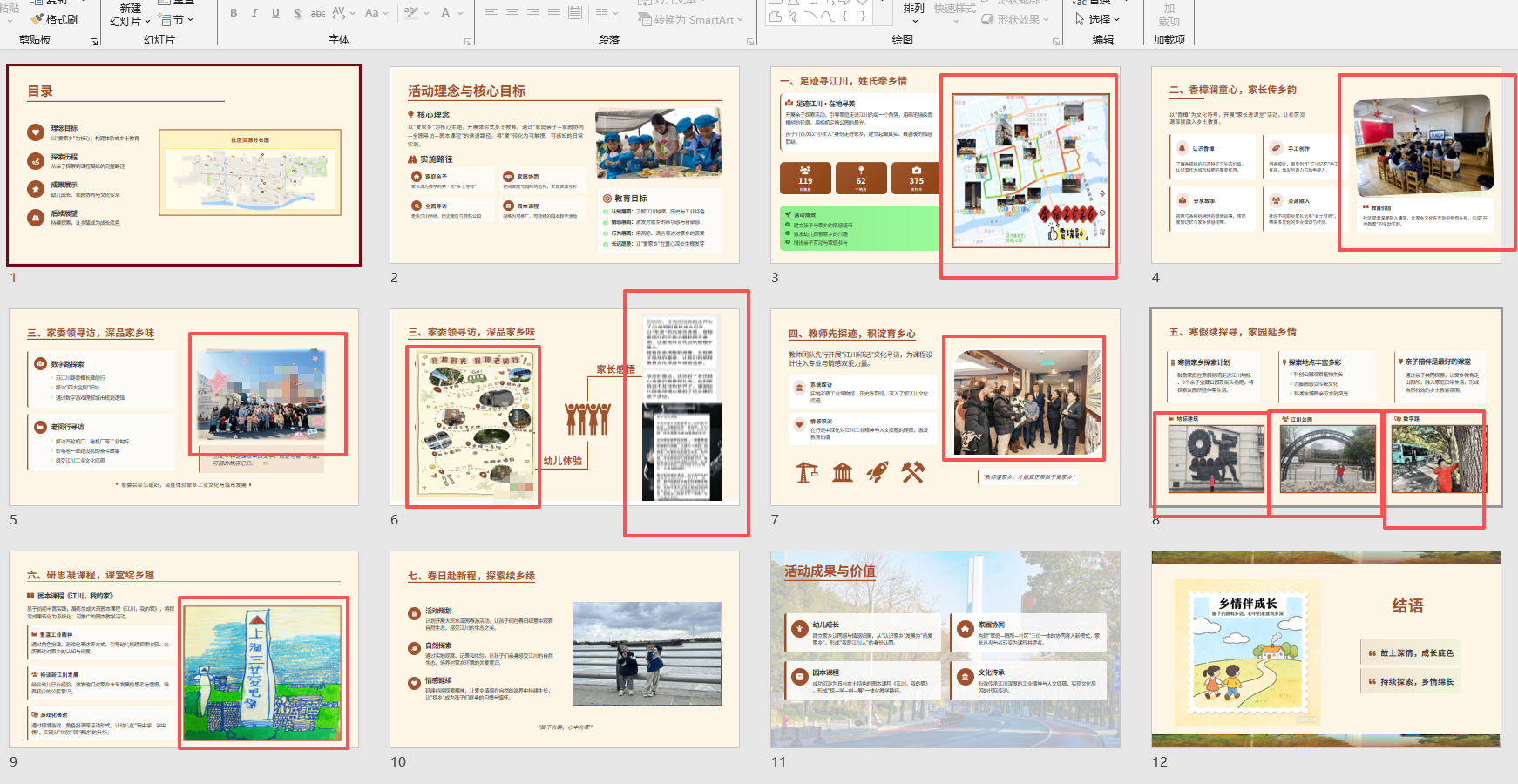
背景需求
前一篇介绍了用“豆包”提取演讲稿大纲文字+“天工AI”制作PPT模板。
PPT版面(颜色、结构)和文字都处理好了,接下去就是处理图片,以下打图片素材1.13G
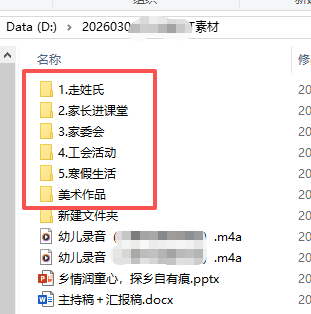
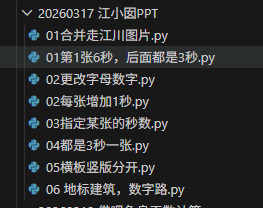
用到的代码位置
一、合并照片
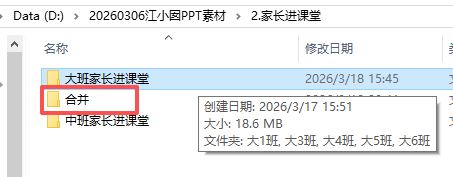
打开第一个“走姓氏”一看,发现有“年级”子文件夹,每个年级下还有“班级”子文件夹,
本次我想做的图片依旧是“把一个文件夹图片做成3秒间隔的GIF图片组”
以前给我的图片都是一个文件夹里有5-20张图片,这样直接用程序做成GIF动图。
现在一看,需要的图片在三级文件夹内,手动一个个复制太繁琐,容易遗漏。
因此,我需要用python把三级文件夹内图片都合并在一起,便于挑选。
deepseek
'''
合并三级文件夹下图片,如“走姓氏”=“大班”=“大1班照片”里面的图片
deepseek,阿夏
20250318
'''
import os
import shutil
from pathlib import Path
from datetime import datetime
def merge_images_advanced(source_folder, target_folder_name='合并',
add_prefix=True, overwrite=False,
include_extensions=None):
"""
高级版:合并图片文件
Args:
source_folder: 源文件夹路径
target_folder_name: 目标文件夹名称
add_prefix: 是否添加文件夹名前缀避免重名
overwrite: 是否覆盖已存在的文件
include_extensions: 要包含的文件扩展名列表
"""
# 默认图片格式
if include_extensions is None:
include_extensions = {'.jpg', '.jpeg', '.png', '.gif', '.bmp', '.tiff', '.webp', '.JPG', '.PNG', '.JPEG'}
source_path = Path(source_folder)
target_path = source_path / target_folder_name
# 创建目标文件夹
target_path.mkdir(exist_ok=True)
copied_count = 0
skipped_count = 0
error_count = 0
# 记录日志
log_file = target_path / f"合并日志_{datetime.now().strftime('%Y%m%d_%H%M%S')}.txt"
with open(log_file, 'w', encoding='utf-8') as log:
log.write(f"图片合并日志 - {datetime.now()}\n")
log.write(f"源文件夹: {source_path}\n")
log.write(f"目标文件夹: {target_path}\n")
log.write("-" * 50 + "\n\n")
# 遍历一级子文件夹
for first_level in source_path.iterdir():
# 跳过目标文件夹本身和非文件夹
if first_level == target_path or not first_level.is_dir():
continue
print(f"\n处理一级文件夹: {first_level.name}")
log.write(f"\n处理一级文件夹: {first_level.name}\n")
# 处理一级文件夹中的图片
for item in first_level.iterdir():
if item.is_file() and item.suffix.lower() in [ext.lower() for ext in include_extensions]:
try:
# 生成目标文件名
if add_prefix:
new_filename = f"{first_level.name}_{item.name}"
else:
new_filename = item.name
destination = target_path / new_filename
# 处理重名文件
if destination.exists() and not overwrite:
base, ext = os.path.splitext(new_filename)
counter = 1
while destination.exists():
new_filename = f"{base}_{counter}{ext}"
destination = target_path / new_filename
counter += 1
# 复制文件
shutil.copy2(item, destination)
copied_count += 1
msg = f" 复制: {item.name} -> {new_filename}"
print(msg)
log.write(msg + "\n")
except Exception as e:
error_count += 1
msg = f" 错误: 复制 {item.name} 失败 - {str(e)}"
print(msg)
log.write(msg + "\n")
# 处理二级子文件夹
elif item.is_dir():
for second_level_item in item.iterdir():
if second_level_item.is_file() and second_level_item.suffix.lower() in [ext.lower() for ext in include_extensions]:
try:
if add_prefix:
new_filename = f"{first_level.name}_{item.name}_{second_level_item.name}"
else:
new_filename = second_level_item.name
destination = target_path / new_filename
if destination.exists() and not overwrite:
base, ext = os.path.splitext(new_filename)
counter = 1
while destination.exists():
new_filename = f"{base}_{counter}{ext}"
destination = target_path / new_filename
counter += 1
shutil.copy2(second_level_item, destination)
copied_count += 1
msg = f" 复制: {item.name}/{second_level_item.name} -> {new_filename}"
print(msg)
log.write(msg + "\n")
except Exception as e:
error_count += 1
msg = f" 错误: 复制 {second_level_item.name} 失败 - {str(e)}"
print(msg)
log.write(msg + "\n")
# 写入总结
log.write("\n" + "=" * 50 + "\n")
log.write(f"合并完成!\n")
log.write(f"成功复制: {copied_count} 个文件\n")
log.write(f"跳过: {skipped_count} 个文件\n")
log.write(f"错误: {error_count} 个\n")
print(f"\n合并完成!")
print(f"成功复制: {copied_count} 个文件")
print(f"跳过: {skipped_count} 个文件")
print(f"错误: {error_count} 个")
print(f"日志文件已保存: {log_file}")
return copied_count
# 使用示例
if __name__ == "__main__":
# 设置源文件夹路径打卡,一级文件夹名字"走姓氏",(收集的是“走姓氏”=“大/中/托?小班”=“大/中/托/小XX班照片”
source_folder = r"D:\20260306社区资源PPT素材\1.走姓氏"
# 直接调用函数,不需要手动创建合并文件夹
# 函数会自动创建合并文件夹
merge_images_advanced(
source_folder,
target_folder_name="合并", # 合并文件夹名称
add_prefix=True, # 添加前缀避免重名
overwrite=False, # 不覆盖现有文件
include_extensions={'.jpg', '.jpeg', '.png', '.gif', '.bmp', '.tiff', '.webp'} # 图片格式
)
# 如果您想使用基本版(第一个回答中的函数),可以这样调用:
# merge_images(source_folder, "合并")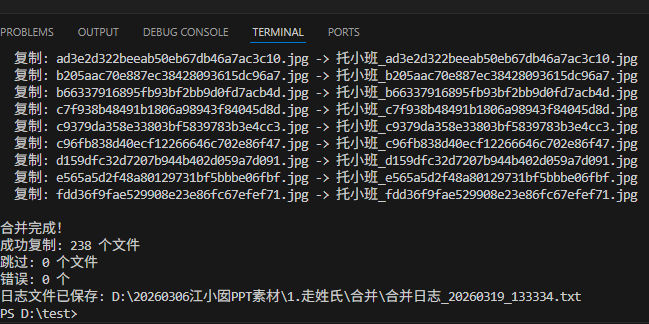
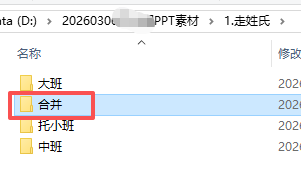

同样方式制作(修改一级文件夹)
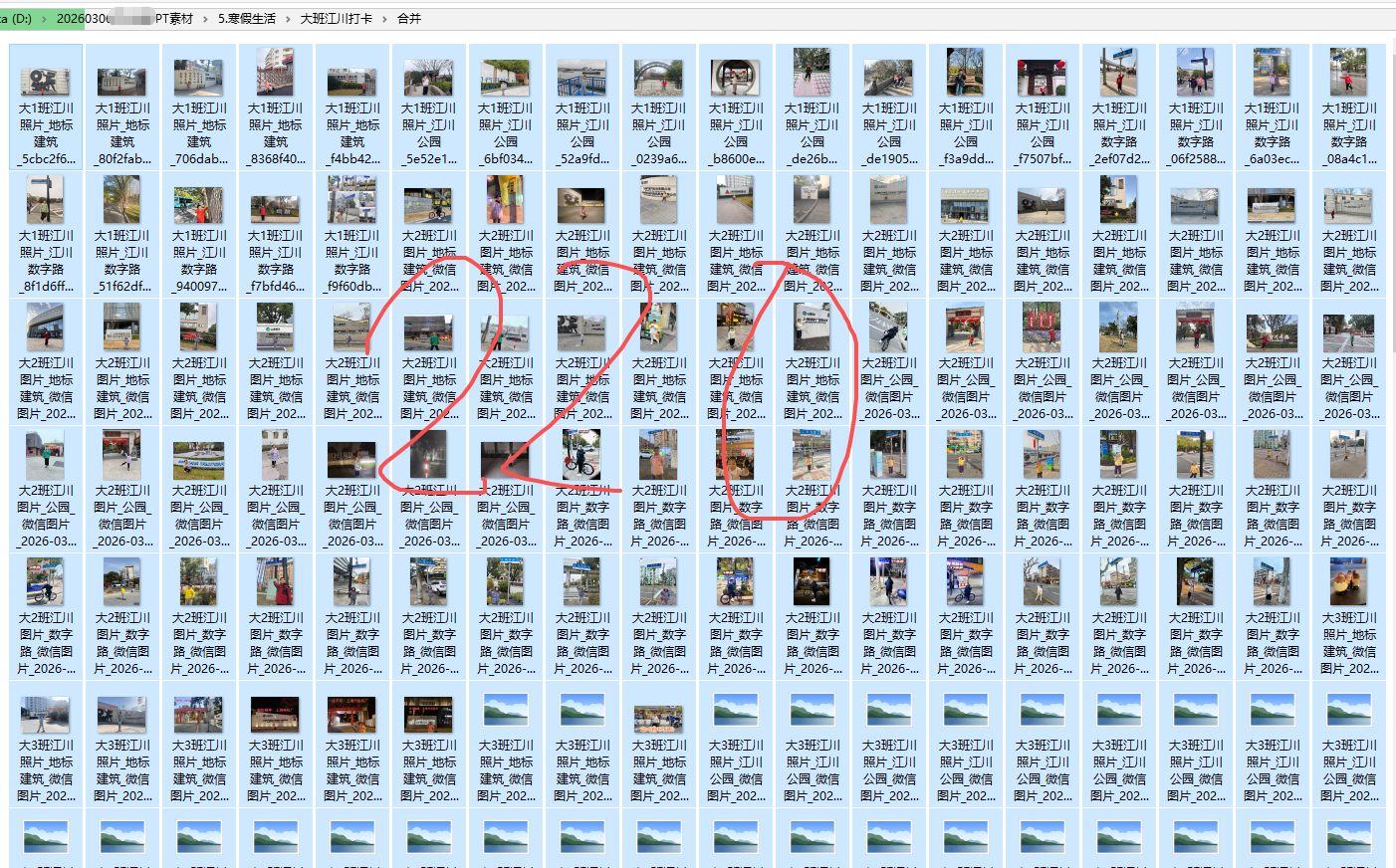
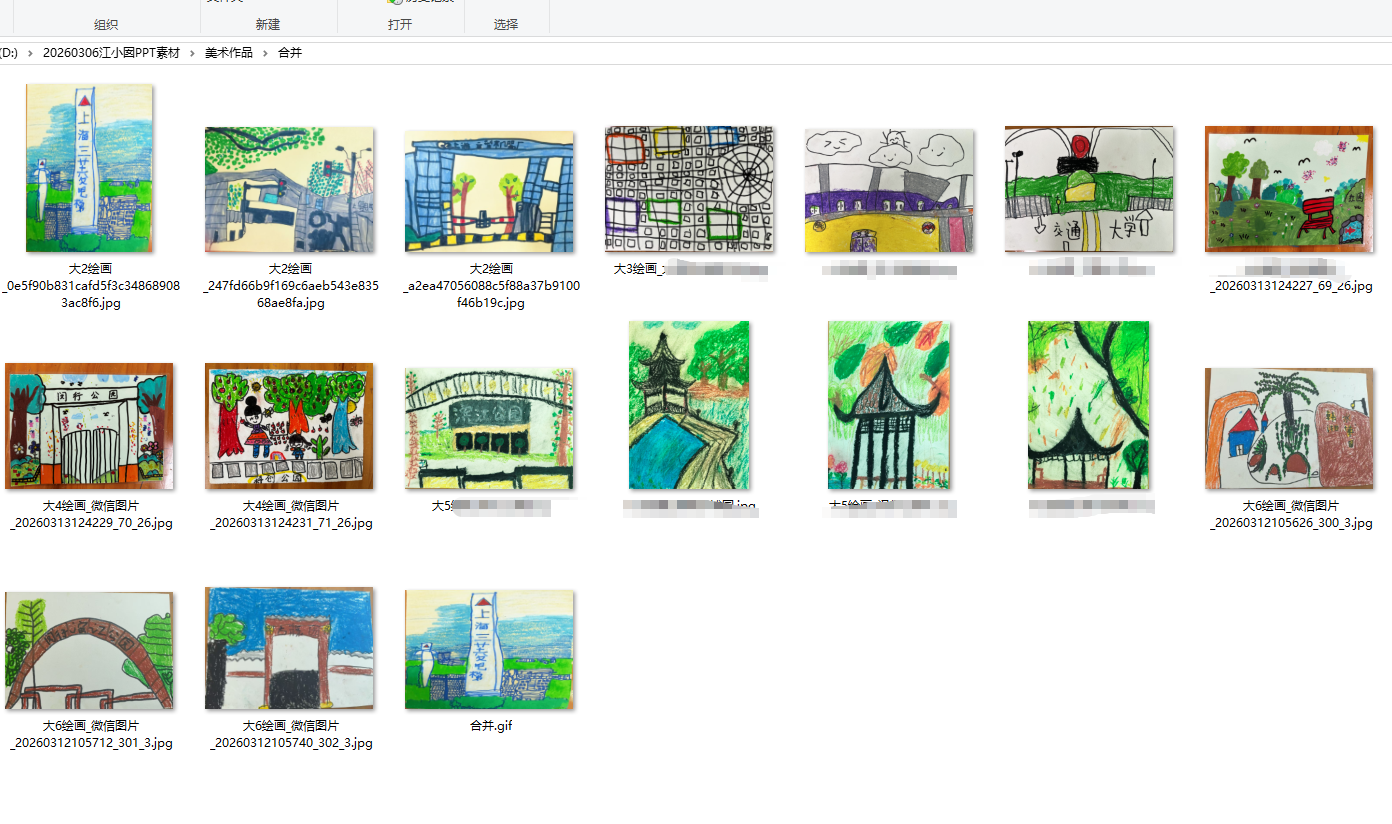
用合并“三级文件夹下”图片的代码,可以快速将所有图片合并到一个文件夹里,便于挑选图片,然后合并制作gif
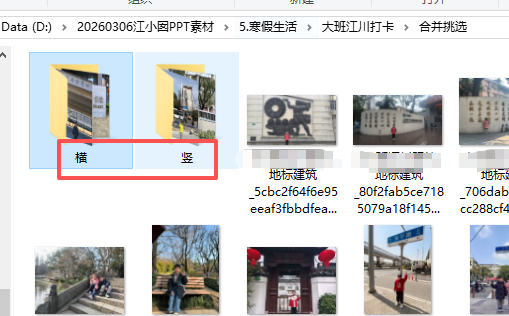
二、区分图片横板竖版,根据图片名称,分类合并图片到指定文件夹
”寒假生活“里面有“四级文件夹”里才是图片
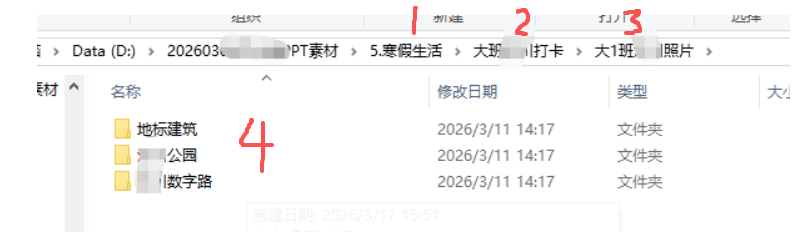
所以,从“大班XX地点打卡”作为“一级文件夹”,合并每个大班的3类照片,到合并文件夹内
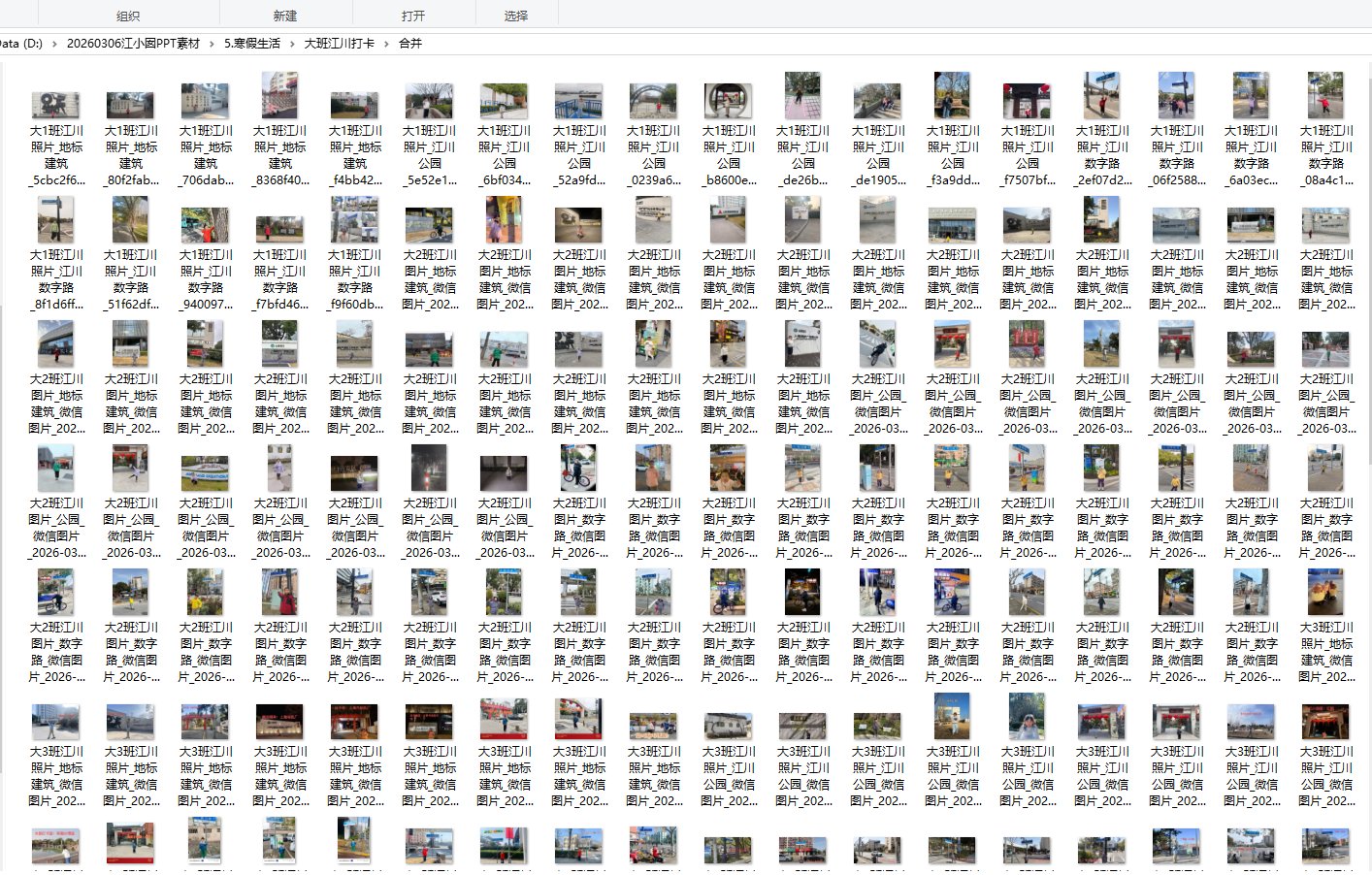
然后我发现这些图片有的横板、有的竖版。为了统一GIF的大小,需要分类横板图片、竖版图片




'''
把照片根据横板竖版拆分两个,考虑exif
deepseek 阿夏
20260319
'''
import os
import shutil
from PIL import Image, ImageOps
import glob
def get_correct_dimensions(image_path):
"""
获取考虑EXIF方向后的正确尺寸
Returns:
(实际宽度, 实际高度, 是否需要旋转)
"""
with Image.open(image_path) as img:
# 获取原始尺寸
width, height = img.size
# 获取EXIF方向信息
try:
exif = img._getexif()
if exif:
# EXIF方向标签通常是274
orientation = exif.get(274, 1)
# 显示EXIF信息用于调试
orientation_map = {
1: "正常",
2: "水平翻转",
3: "旋转180°",
4: "垂直翻转",
5: "旋转90°并水平翻转",
6: "旋转90°",
7: "旋转90°并垂直翻转",
8: "旋转270°"
}
orientation_desc = orientation_map.get(orientation, f"未知({orientation})")
print(f" EXIF方向: {orientation_desc}")
# 如果图片需要旋转90°或270°,则实际显示尺寸应该交换宽高
if orientation in [5, 6, 7, 8]:
# 这些方向表示图片需要旋转,所以实际的宽高是相反的
actual_width, actual_height = height, width
print(f" 注意: 图片需要旋转,实际显示尺寸应为 {actual_width} x {actual_height}")
return actual_width, actual_height, True
else:
return width, height, False
except Exception as e:
print(f" 读取EXIF信息失败: {e}")
pass
return width, height, False
def fix_image_orientation(image_path, destination_path):
"""
修复图片方向并保存
"""
with Image.open(image_path) as img:
try:
# 使用ImageOps.exif_transpose自动根据EXIF信息旋转图片
fixed_img = ImageOps.exif_transpose(img)
# 保存修复后的图片
fixed_img.save(destination_path)
return True
except Exception as e:
print(f" 修复图片方向失败: {e}")
# 如果修复失败,直接复制原图
shutil.copy2(image_path, destination_path)
return False
def classify_images_by_orientation(source_folder, fix_orientation=True):
"""
根据图片实际显示方向分类复制图片(修复重复处理问题)
Args:
source_folder: 源文件夹路径
fix_orientation: 是否修复图片方向(将图片旋转到正确方向)
"""
# 创建目标文件夹
horizontal_folder = os.path.join(source_folder, "横")
vertical_folder = os.path.join(source_folder, "竖")
os.makedirs(horizontal_folder, exist_ok=True)
os.makedirs(vertical_folder, exist_ok=True)
# 使用集合来记录已处理的文件,避免重复
processed_files = set()
# 支持的图片格式 - 使用小写统一匹配
image_extensions = ['*.jpg', '*.jpeg', '*.png', '*.gif', '*.bmp', '*.tiff',
'*.webp'] # 移除大写版本,下面会统一处理
stats = {
'horizontal': 0,
'horizontal_with_exif': 0, # 有EXIF旋转的横图
'vertical': 0,
'vertical_with_exif': 0, # 有EXIF旋转的竖图
'square': 0,
'skipped_duplicate': 0, # 跳过的重复文件
'error': 0
}
print("开始处理图片(已启用EXIF方向识别)...")
print("="*70)
# 先收集所有图片文件,避免重复
all_images = []
for extension in image_extensions:
# 使用大小写不敏感的匹配
all_images.extend(glob.glob(os.path.join(source_folder, extension)))
all_images.extend(glob.glob(os.path.join(source_folder, extension.upper())))
# 去重(使用规范化路径)
unique_images = set()
for image_path in all_images:
# 获取绝对路径并规范化
abs_path = os.path.abspath(image_path)
unique_images.add(abs_path)
print(f"找到 {len(unique_images)} 个唯一图片文件")
for image_path in unique_images:
# 检查是否已经在子文件夹中
if (os.path.dirname(image_path) == horizontal_folder or
os.path.dirname(image_path) == vertical_folder):
continue
# 检查是否已经处理过
if image_path in processed_files:
stats['skipped_duplicate'] += 1
continue
try:
filename = os.path.basename(image_path)
print(f"\n处理: {filename}")
# 获取考虑EXIF后的实际尺寸
actual_width, actual_height, has_exif_rotation = get_correct_dimensions(image_path)
# 获取原始尺寸(避免重复打开图片)
with Image.open(image_path) as img:
original_width, original_height = img.size
print(f" 原始尺寸: {original_width} x {original_height}")
print(f" 实际显示尺寸: {actual_width} x {actual_height}")
# 根据实际显示尺寸判断方向
if actual_width > actual_height:
# 横图
target_folder = horizontal_folder
stats['horizontal'] += 1
if has_exif_rotation:
stats['horizontal_with_exif'] += 1
orientation_type = "横图"
elif actual_width < actual_height:
# 竖图
target_folder = vertical_folder
stats['vertical'] += 1
if has_exif_rotation:
stats['vertical_with_exif'] += 1
orientation_type = "竖图"
else:
# 正方形
stats['square'] += 1
print(f" ⚠️ 正方形图片,保持不变")
# 标记为已处理
processed_files.add(image_path)
continue
# 生成目标路径(处理重名)
destination = os.path.join(target_folder, filename)
if os.path.exists(destination):
base, ext = os.path.splitext(filename)
counter = 1
while os.path.exists(os.path.join(target_folder, f"{base}_{counter}{ext}")):
counter += 1
destination = os.path.join(target_folder, f"{base}_{counter}{ext}")
# 复制或修复图片
if fix_orientation and has_exif_rotation:
# 如果需要修复方向,保存旋转后的图片
success = fix_image_orientation(image_path, destination)
if success:
print(f" ✅ 归类为: {orientation_type} (已修复EXIF方向)")
else:
print(f" ✅ 归类为: {orientation_type} (EXIF修复失败,直接复制)")
else:
# 直接复制
shutil.copy2(image_path, destination)
print(f" ✅ 归类为: {orientation_type}")
# 标记为已处理
processed_files.add(image_path)
except Exception as e:
stats['error'] += 1
print(f" ❌ 处理图片时出错: {str(e)}")
# 即使出错也标记,避免重复尝试
processed_files.add(image_path)
# 打印详细统计信息
print("\n" + "="*70)
print("处理完成!详细统计信息:")
print(f"📊 横图总数: {stats['horizontal']}")
if stats['horizontal_with_exif'] > 0:
print(f" └─ 其中包含EXIF旋转信息的: {stats['horizontal_with_exif']}")
print(f"📊 竖图总数: {stats['vertical']}")
if stats['vertical_with_exif'] > 0:
print(f" └─ 其中包含EXIF旋转信息的: {stats['vertical_with_exif']}")
print(f"📊 正方形图片: {stats['square']}")
print(f"📊 跳过的重复文件: {stats['skipped_duplicate']}")
print(f"📊 处理失败: {stats['error']}")
print(f"📊 总共处理: {len(processed_files)} 个文件")
print("="*70)
if fix_orientation:
print("\n✨ 已自动修复所有包含EXIF旋转信息的图片方向!")
print("修复后的图片会以正确的方向保存在目标文件夹中。")
# 如果还想进一步调试,可以使用这个调试版本
def debug_duplicate_files(source_folder):
"""
调试函数:检查文件夹中的重复文件
"""
print("检查重复文件...")
# 收集所有文件
all_files = []
for root, dirs, files in os.walk(source_folder):
for file in files:
if file.lower().endswith(('.jpg', '.jpeg', '.png', '.gif', '.bmp')):
full_path = os.path.join(root, file)
all_files.append(full_path)
# 按文件名分组
files_by_name = {}
for file_path in all_files:
filename = os.path.basename(file_path)
if filename not in files_by_name:
files_by_name[filename] = []
files_by_name[filename].append(file_path)
# 找出重复的文件名
duplicates = {name: paths for name, paths in files_by_name.items() if len(paths) > 1}
if duplicates:
print(f"\n发现 {len(duplicates)} 个重复文件名:")
for name, paths in duplicates.items():
print(f"\n文件: {name}")
for path in paths:
print(f" - {path}")
else:
print("没有发现重复文件名")
# 使用示例
if __name__ == "__main__":
folder_path = r"D:\20260306江小囡PPT素材\5.寒假生活\中班江川打卡\合并挑选"
if os.path.exists(folder_path):
# 可选:先运行调试函数检查重复文件
# debug_duplicate_files(folder_path)
print("请选择模式:")
print("1. 完整模式:根据EXIF正确分类并修复图片方向")
print("2. 简单模式:只根据EXIF正确分类,不修改图片")
# 使用完整模式,但已修复重复处理问题
classify_images_by_orientation(folder_path, fix_orientation=True)
else:
print(f"错误:文件夹 '{folder_path}' 不存在!")现在横板和竖版都正确了,
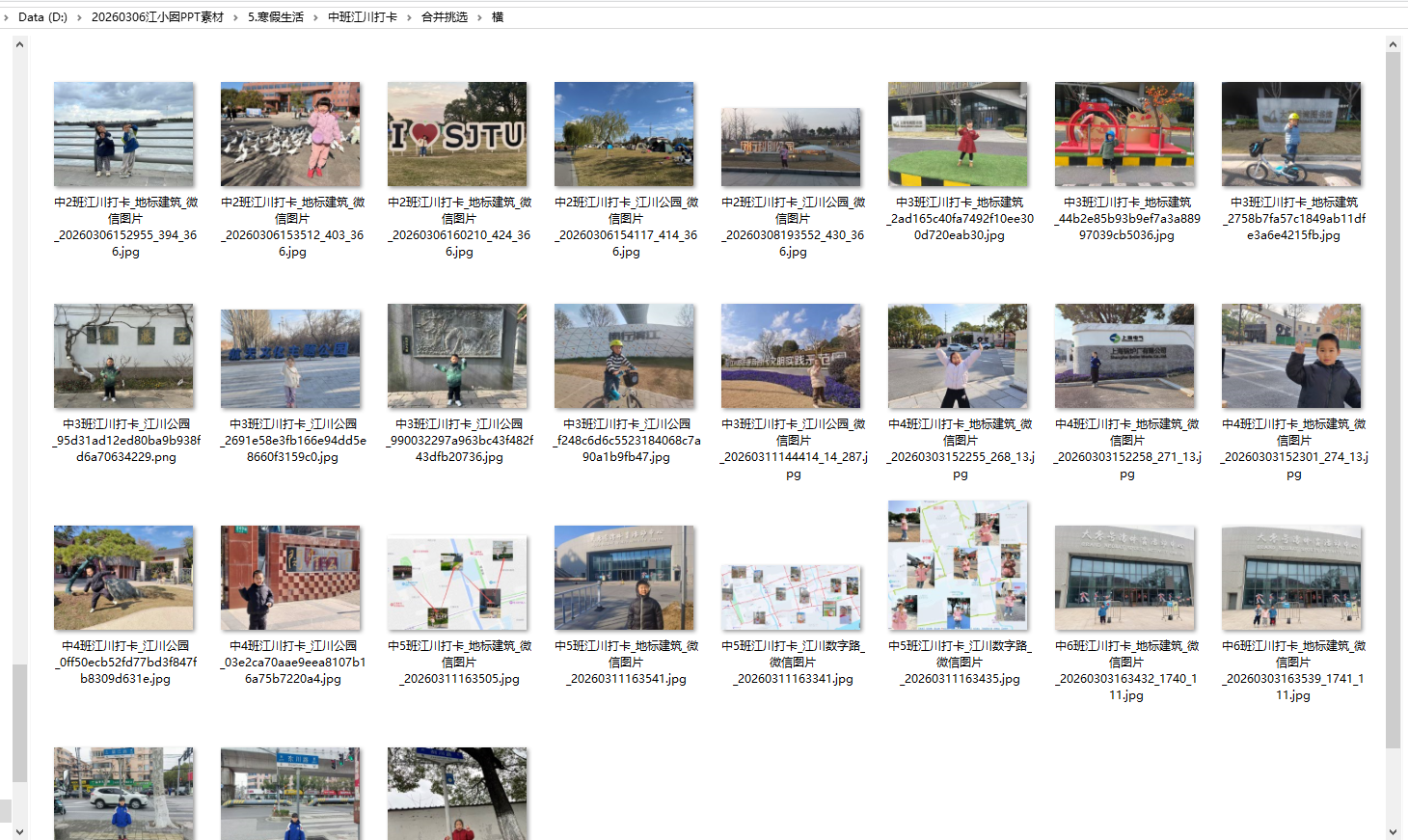
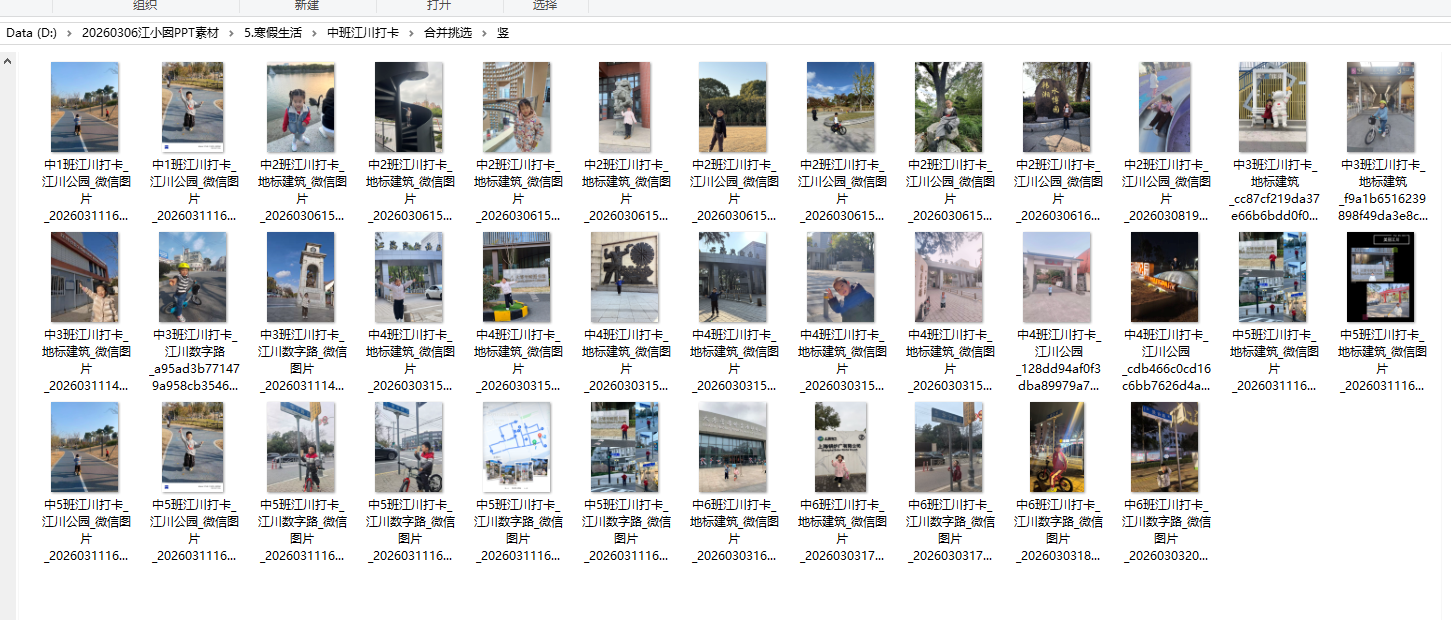
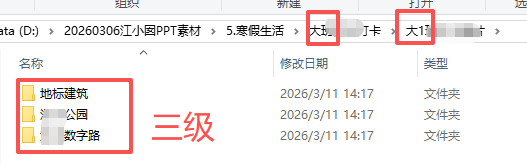
我发现这套照片上有文件名,标注了“建筑名称”,可以把同名放在一个文件夹里。便于合并做 不同建筑 的给GIF

一共就三个地标:
'''
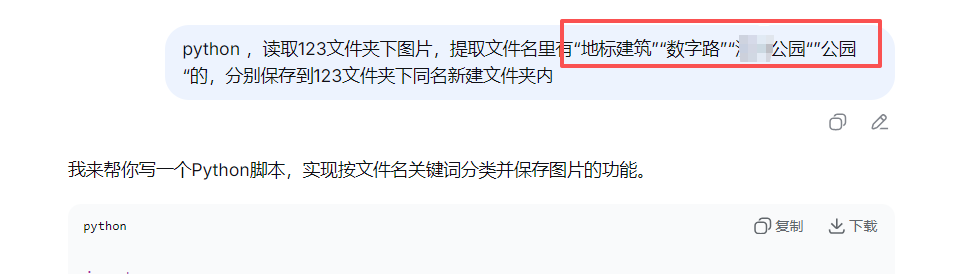
读取图片的文件名里的指定文字”XX公园”“XX路”,合并在同名文件夹里
deepseek 阿夏
20260319
'''
import os
import shutil
from pathlib import Path
def classify_images_by_keywords(source_folder, keywords_dict):
"""
根据文件名中的关键词将图片分类到不同的文件夹
Args:
source_folder: 源文件夹路径(即123文件夹)
keywords_dict: 关键词字典,格式为 {文件夹名: [关键词列表]}
"""
# 确保源文件夹存在
if not os.path.exists(source_folder):
print(f"错误:文件夹 {source_folder} 不存在")
return
# 支持的图片格式
image_extensions = {'.jpg', '.jpeg', '.png', '.gif', '.bmp', '.tiff', '.webp'}
# 获取所有文件
all_files = os.listdir(source_folder)
# 统计信息
classified_count = 0
unclassified_files = []
# 为每个分类创建文件夹并处理文件
for folder_name, keywords in keywords_dict.items():
# 创建目标文件夹
target_folder = os.path.join(source_folder, folder_name)
os.makedirs(target_folder, exist_ok=True)
print(f"创建/检查文件夹: {target_folder}")
# 遍历所有文件
for filename in all_files:
file_path = os.path.join(source_folder, filename)
# 跳过文件夹
if os.path.isdir(file_path):
continue
# 检查是否为图片文件
file_ext = Path(filename).suffix.lower()
if file_ext not in image_extensions:
continue
# 检查文件名是否包含任何关键词
for keyword in keywords:
if keyword in filename:
# 构建目标路径
target_path = os.path.join(target_folder, filename)
# 如果目标文件已存在,添加前缀
if os.path.exists(target_path):
name, ext = os.path.splitext(filename)
target_path = os.path.join(target_folder, f"{name}_copy{ext}")
# 复制文件(使用shutil.copy2保留元数据)
try:
shutil.copy2(file_path, target_path)
print(f"已复制: {filename} -> {folder_name}/")
classified_count += 1
except Exception as e:
print(f"复制文件 {filename} 时出错: {e}")
break # 找到关键词后就停止检查其他关键词
# 找出未分类的图片
print("\n" + "="*50)
print(f"分类完成!共处理了 {classified_count} 个文件")
# 可选:显示未分类的图片
remaining_files = []
for filename in all_files:
file_path = os.path.join(source_folder, filename)
if os.path.isfile(file_path):
file_ext = Path(filename).suffix.lower()
if file_ext in image_extensions:
# 检查是否已被分类
is_classified = False
for folder_name in keywords_dict.keys():
target_path = os.path.join(source_folder, folder_name, filename)
if os.path.exists(target_path):
is_classified = True
break
if not is_classified:
remaining_files.append(filename)
if remaining_files:
print(f"\n以下 {len(remaining_files)} 个图片文件未分类(文件名不包含任何关键词):")
for f in remaining_files[:10]: # 只显示前10个
print(f" - {f}")
if len(remaining_files) > 10:
print(f" ... 还有 {len(remaining_files)-10} 个文件未显示")
def main():
# 设置源文件夹路径
source_folder = r"D:\20260306XXXX小囡PPT素材\5.寒假生活\中班XXXX打卡\合并挑选\横" # 当前目录下的123文件夹
# 如果需要绝对路径,可以使用:
# source_folder = os.path.join(os.path.dirname(__file__), "123")
# 定义关键词和对应的文件夹名
keywords_dict = {
"地标建筑": ["地标建筑"],
"数字路": ["数字路"],
"XXXX公园": ["XXXX公园"],
"公园": ["公园"] # 注意:这个可能会匹配到"XXXX公园",因为包含"公园"
}
# 如果希望优先匹配更具体的分类,可以调整顺序
# 这里我们先处理"XXXX公园"文件夹
keywords_dict_ordered = {
"XXXX公园": ["XXXX公园"], # 先处理这个,避免被"公园"文件夹抢走
"地标建筑": ["地标建筑"],
"数字路": ["数字路"],
"公园": ["公园"] # 后处理普通的"公园"
}
print(f"开始处理文件夹: {source_folder}")
print("关键词分类规则:")
for folder, keywords in keywords_dict_ordered.items():
print(f" - {folder}: 包含 {keywords}")
print("="*50)
# 执行分类
classify_images_by_keywords(source_folder, keywords_dict_ordered)
print("\n提示:如果文件被错误分类,可以从目标文件夹中手动调整。")
if __name__ == "__main__":
main()
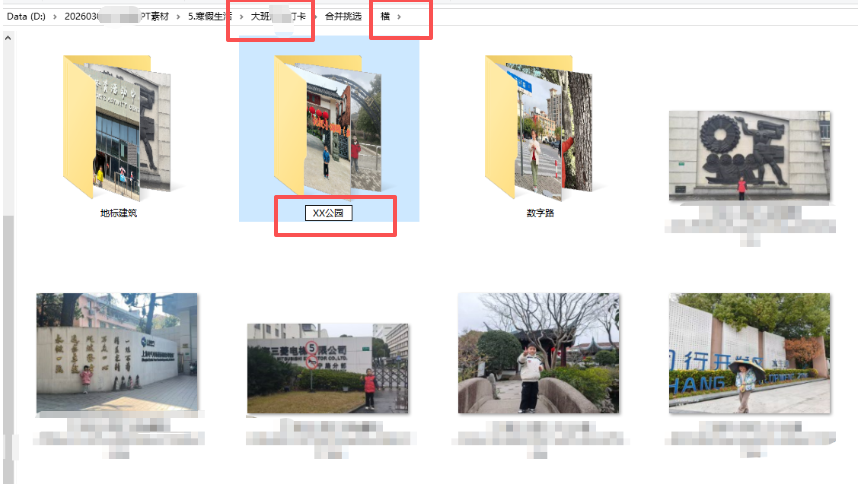


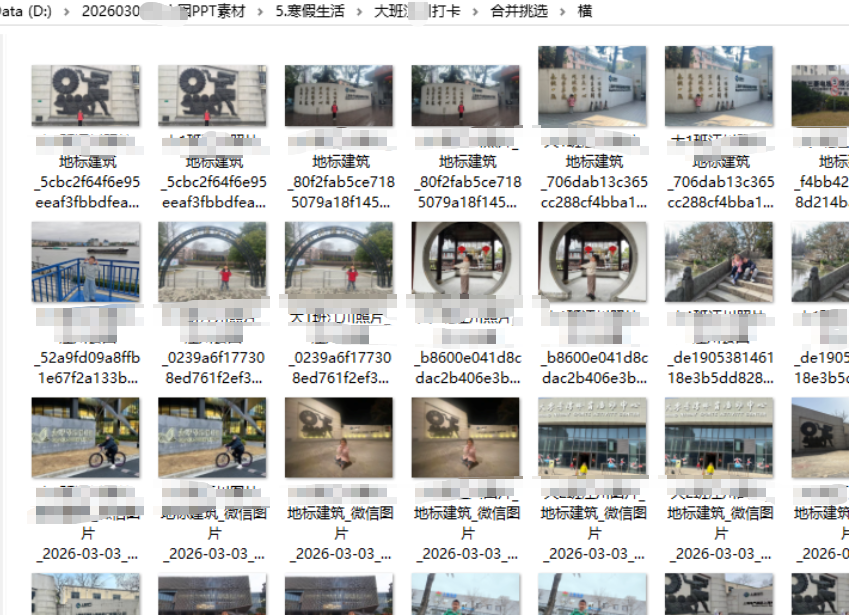
这样就可以分类同样的照片(多个班级的XX路的照片),便于挑选。(如:大班横板,换成,大班竖版)

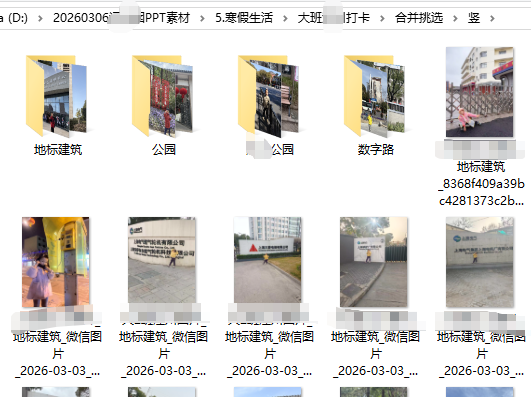
三、图片名称修改
“走姓氏”里面是 幼儿与家长在街道走路,记录下行走路线,形成姓氏的首字母。
刚才把所有的图片都合并了。
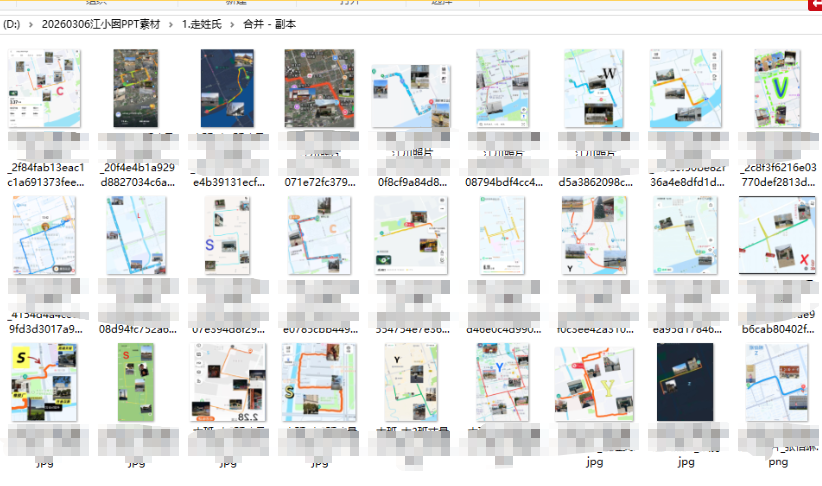
我希望按照字母分类一下,手动修改文件名为字母,辨认+写入新文件名,花了很长时间
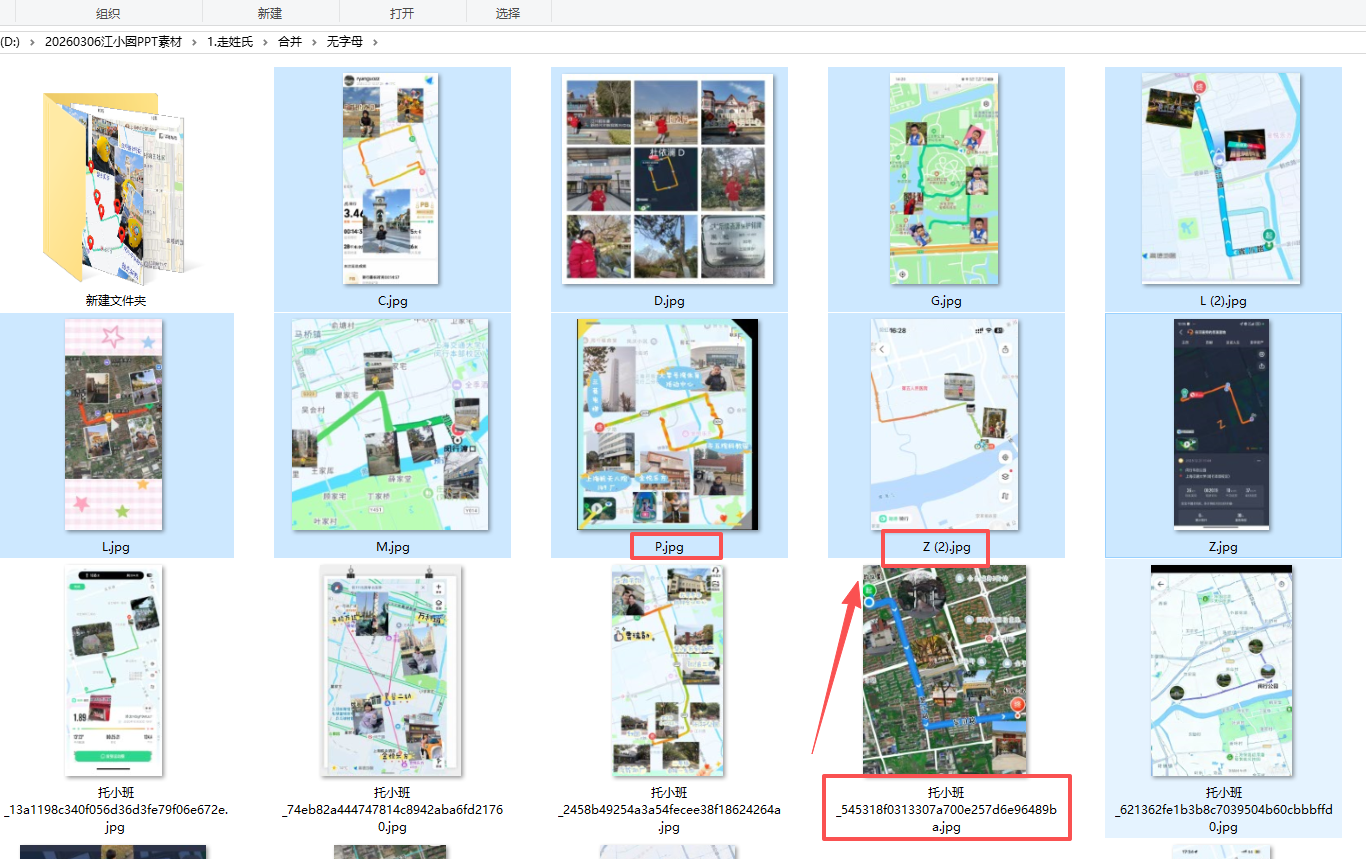
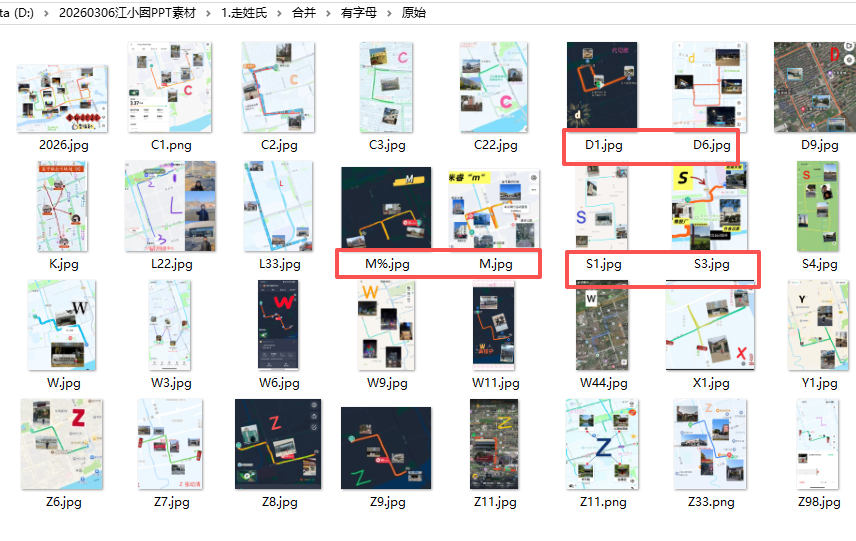
这里面为了不重号,所以输入字母后面的数字比较随意(后面的数字不是连续的,可能还有其他符号,空格)
'''
把带有字母(在第一个位置)后面的编号改成_01_02……
deepseek 阿夏
20260319
'''
import os
import re
def batch_rename_images(folder_path):
"""
批量重命名图片文件,根据文件名中的字母进行分类编号
"""
image_extensions = ('.png', '.jpg', '.jpeg', '.gif', '.bmp', '.tiff')
try:
# 获取所有文件
all_files = os.listdir(folder_path)
# 用字典存储不同字母的文件
files_by_letter = {}
# 遍历所有文件
for file in all_files:
if file.lower().endswith(image_extensions):
# 使用正则表达式找出文件名中的字母
# 这里假设文件名中的字母是大写字母
letters = re.findall(r'[A-Z]', file)
if letters:
# 取第一个找到的字母作为分类
letter = letters[0]
if letter not in files_by_letter:
files_by_letter[letter] = []
files_by_letter[letter].append(file)
# 处理每个字母的文件
for letter, files in files_by_letter.items():
files.sort()
print(f"\n处理字母 '{letter}' 的文件:")
count = 1
for old_filename in files:
file_ext = os.path.splitext(old_filename)[1]
new_filename = f"{letter}_{count:02d}{file_ext}"
old_path = os.path.join(folder_path, old_filename)
new_path = os.path.join(folder_path, new_filename)
# 如果新文件名已存在,添加额外编号
while os.path.exists(new_path):
count += 1
new_filename = f"{letter}_{count:02d}{file_ext}"
new_path = os.path.join(folder_path, new_filename)
os.rename(old_path, new_path)
print(f"{old_filename} -> {new_filename}")
count += 1
print(f"字母 '{letter}' 处理完成,共 {count-1} 个文件。")
print("\n所有文件处理完成!")
except FileNotFoundError:
print(f"错误:找不到文件夹 '{folder_path}'")
except Exception as e:
print(f"发生错误:{e}")
# 使用示例
if __name__ == "__main__":
# folder_path = r"D:\20260306江小囡PPT素材\1.走姓氏\合并\无字母\修改" # 文件夹路径
# folder_path = r"D:\20260306江小囡PPT素材\1.走姓氏\合并\有字母\修改" # 文件夹路径
folder_path = r"D:\20260306江小囡PPT素材\1.走姓氏\合并\再合并修改"
batch_rename_images(folder_path)
全部按照顺序01,02排列
然后再人工挑选照片
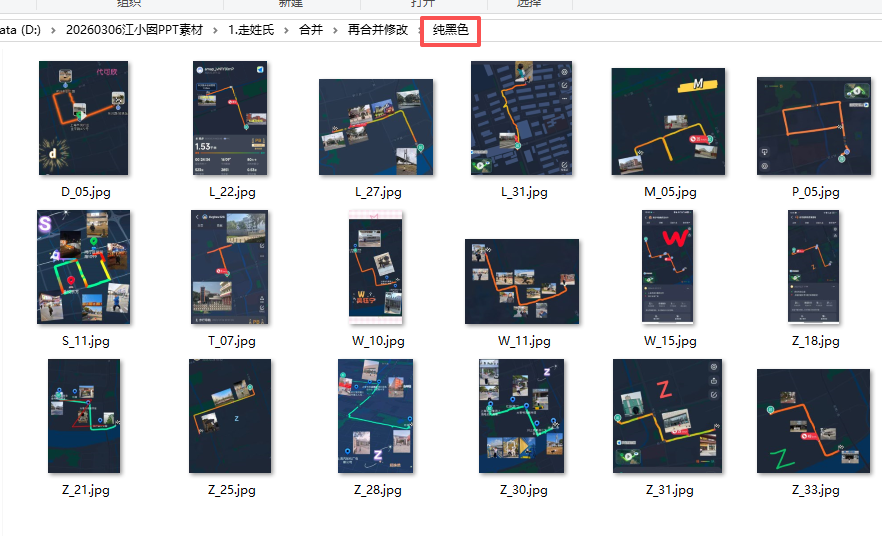
每个字母2-3张

放弃的
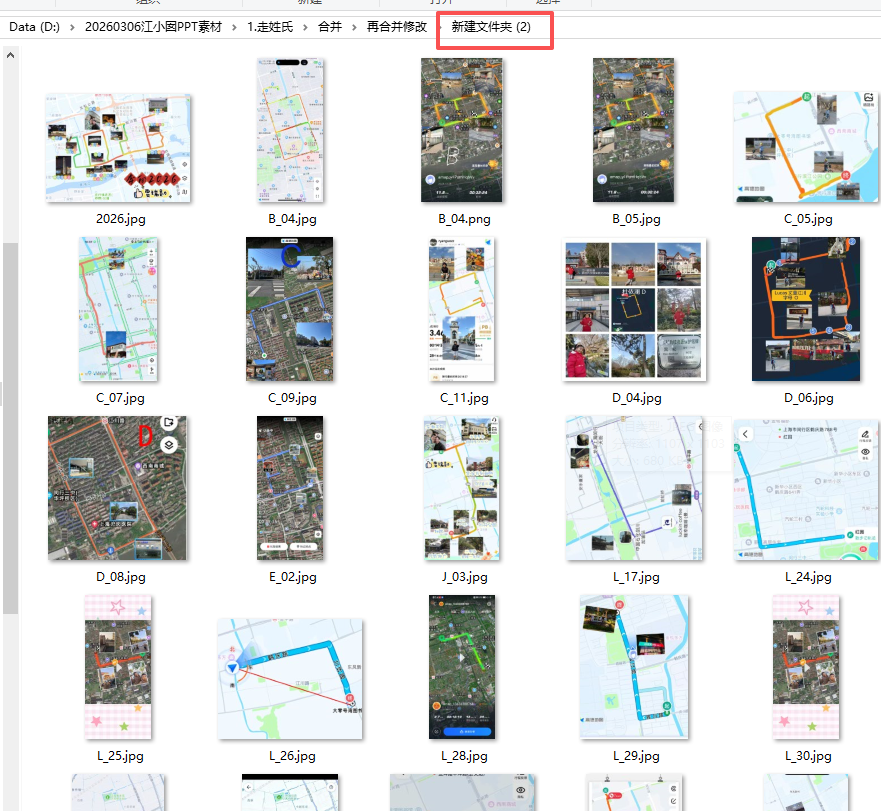
四、GIF图片 X秒
刚才将所有需要的PPT的图片,都合并,分类,挑选,放在一个文件夹里
'''
汇报PPT,把JPG图片合并为动态GIF,间隔时间可设置
优化版本:增加错误处理、路径验证、进度显示
deepseek,阿夏
20250512
'''
from PIL import Image
import os
import sys
def get_float_input(prompt, default=0.5):
"""
获取浮点数输入,带错误处理
"""
while True:
try:
user_input = input(prompt)
# 如果直接回车,使用默认值
if user_input.strip() == '':
print(f'使用默认值: {default}秒')
return default
value = float(user_input)
if value <= 0:
print('间隔时间必须大于0,请重新输入')
continue
return value
except ValueError:
print('输入无效,请输入数字(例如:0.5、1、2)')
def get_folder_name(prompt, base_path):
"""
获取文件夹名称,并验证路径是否存在
"""
while True:
folder_name = input(prompt).strip()
# 如果直接回车,退出程序
if folder_name == '':
print('未输入文件夹名称,程序退出')
sys.exit(0)
# 检查路径是否存在
full_path = os.path.join(base_path, folder_name)
if os.path.exists(full_path):
return folder_name
else:
print(f'文件夹不存在: {full_path}')
print('请重新输入有效的文件夹名称')
def create_gif_from_images(folder_path, output_gif, target_size=(1024, 720), interval=0.5):
"""
将文件夹中的所有图片合并为GIF
参数:
folder_path: 包含图片的文件夹路径
output_gif: 输出的GIF文件名
target_size: 目标图片大小 (宽, 高)
interval: 每帧间隔时间(秒)
"""
# 支持的图片格式
valid_extensions = ('.png', '.jpg', '.jpeg', '.bmp', '.jfif', '.tiff', '.webp')
# 获取文件夹中所有图片文件(按文件名排序,保证顺序)
image_files = []
for file in sorted(os.listdir(folder_path)):
if file.lower().endswith(valid_extensions):
image_files.append(os.path.join(folder_path, file))
if not image_files:
print(f"错误: 文件夹 '{folder_path}' 中没有找到支持的图片文件!")
print(f"支持的格式: {', '.join(valid_extensions)}")
return False
print(f"找到 {len(image_files)} 张图片")
print(f"正在处理图片,目标尺寸: {target_size[0]}x{target_size[1]}")
print(f"每帧间隔: {interval}秒")
# 打开所有图片并调整大小
images = []
for i, image_file in enumerate(image_files):
try:
# 显示进度
print(f"处理第 {i+1}/{len(image_files)} 张: {os.path.basename(image_file)}")
img = Image.open(image_file)
# 转换为RGB模式(防止GIF保存时出错)
if img.mode != 'RGB':
img = img.convert('RGB')
# 直接拉伸到目标尺寸(不保持比例)
img = img.resize(target_size, Image.Resampling.LANCZOS)
images.append(img)
except Exception as e:
print(f"警告: 无法处理文件 {os.path.basename(image_file)}: {e}")
continue
if not images:
print("错误: 没有有效的图片可以处理!")
return False
# 设置每帧的持续时间(毫秒)
durations = [int(interval * 1000)] * len(images) # 所有帧相同时间
print(f"正在生成GIF,共 {len(images)} 帧...")
try:
# 保存为GIF
images[0].save(
output_gif,
save_all=True,
append_images=images[1:],
duration=durations,
loop=0, # 无限循环
optimize=True, # 优化GIF
quality=95 # 设置质量
)
# 获取文件大小
file_size = os.path.getsize(output_gif) / (1024 * 1024) # 转换为MB
print(f"✅ GIF已成功保存为 {output_gif}")
print(f" 文件大小: {file_size:.2f} MB")
print(f" 总时长: {interval * len(images):.1f}秒")
return True
except Exception as e:
print(f"❌ 保存GIF时出错: {e}")
return False
def main():
"""
主函数
"""
print("=" * 50)
print(" 图片转GIF工具 v2.0")
print("=" * 50)
# 基础路径
base_path = r'D:\20260306江小囡PPT素材\2.家长进课堂'
# 检查基础路径是否存在
if not os.path.exists(base_path):
print(f"错误: 基础路径不存在!")
print(f"路径: {base_path}")
print("请修改代码中的 base_path 变量为正确的路径")
input("按回车键退出...")
return
print(f"基础路径: {base_path}")
print("-" * 50)
# 获取间隔时间
interval = get_float_input('请输入每张图片间隔秒数 (直接回车默认0.5秒): ', default=0.5)
# 获取文件夹名称
folder_name = get_folder_name('请输入文件夹名称: ', base_path)
# 构建完整路径
input_folder = os.path.join(base_path, folder_name)
output_file = os.path.join(input_folder, f"{folder_name}.gif")
print("-" * 50)
print(f"输入文件夹: {input_folder}")
print(f"输出文件: {output_file}")
print("-" * 50)
# 确认操作
confirm = 'y'
# input('确认生成GIF? (y/n, 直接回车默认y): ').strip().lower()
if confirm not in ['', 'y', 'yes']:
print('操作已取消')
return
# 执行转换
success = create_gif_from_images(
input_folder,
output_file,
target_size=(1024, 720),
interval=interval
)
if success:
print("\n✨ 转换完成!")
else:
print("\n❌ 转换失败,请检查错误信息")
print("-" * 50)
input("按回车键退出...")
# 使用示例
if __name__ == "__main__":
try:
main()
except KeyboardInterrupt:
print("\n\n程序被用户中断")
sys.exit(0)
except Exception as e:
print(f"\n程序出现意外错误: {e}")
input("按回车键退出...")使用方法
复制要合并的图片的路径,全选
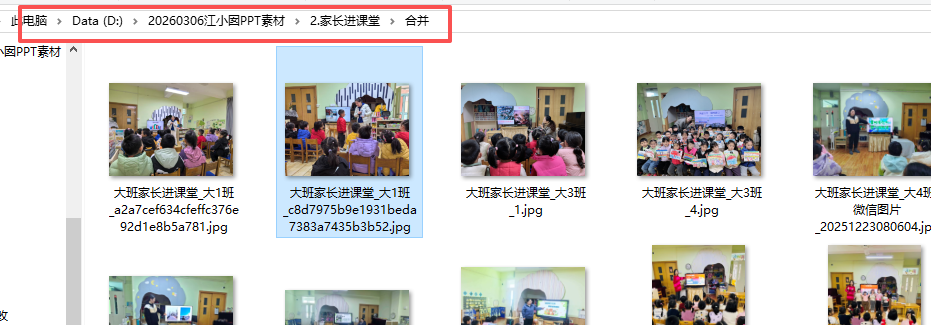
复制到path里面

把最后一个\后面的内容剪切
删除最后一个\
运行程序
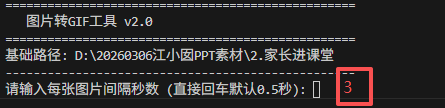
输入3秒
2.输入文件夹名称(刚才剪切的"合并“),也是最后GIF图片的名称
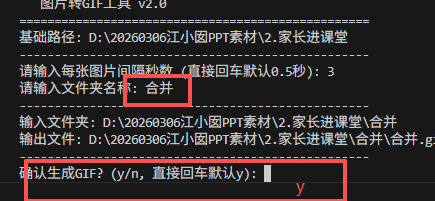
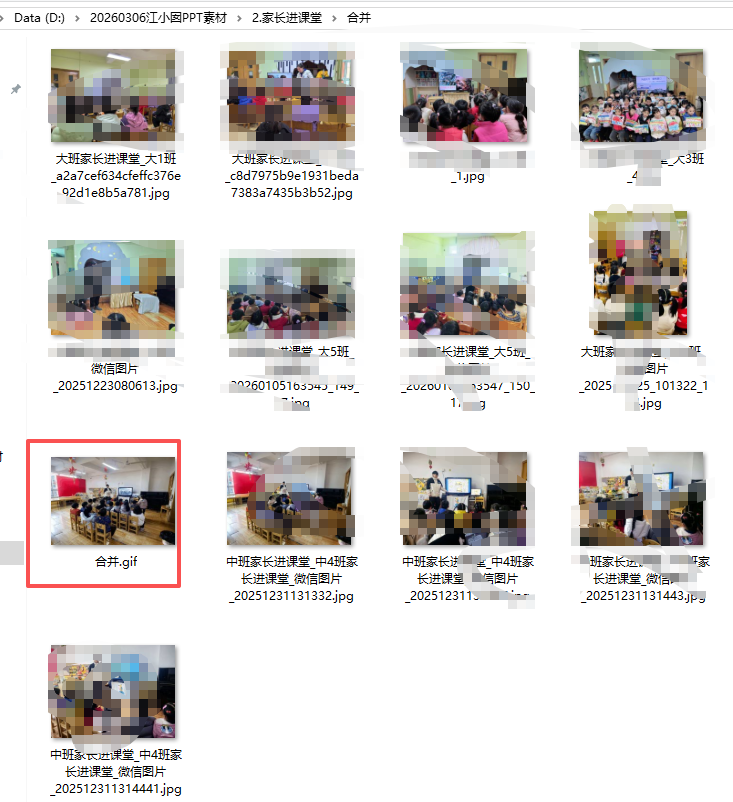
复制这个GIF到PPT指定位置
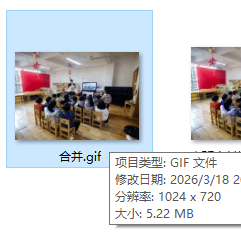

图片位置替换

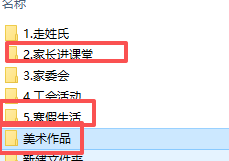
同样方式做不同秒数,不同文件夹名字的GIF,插入PPT预定位置(红色框)
感悟:
用python,解决了很多图像处理(合并、编号,GIF)的问题,极大提高了PPT制作效率。
后续图片顺序需要修改,用python也能飞快修改GIF图片。
转载自CSDN-专业IT技术社区
原文链接:https://blog.csdn.net/reasonsummer/article/details/159243422

