
论文名称:Submodularity In Machine Learning and Artificial Intelligence


一、综述论文
这篇文章是一篇 综述论文(survey)。
核心目标是:
介绍 Submodular functions(次模函数) 以及它们在 机器学习与人工智能中的应用。
作者想说明一个非常重要的观点:
很多机器学习问题其实是“离散优化问题”。
例如:
-
Feature Selection:属于数据预处理问题,旨在从原始特征中筛选出最相关、最有信息量的子集,以降低维度、提升模型性能与可解释性。
-
Dataset Subset Selection:属于数据采样或核心集选择问题,旨在从大规模数据中选取一个具有代表性的子集,以降低计算和存储成本,同时保持模型性能。
-
Active Learning:属于机器学习训练策略问题,通过让模型主动选择最有价值的数据进行标注,以最少的标注成本最大化模型性能。
-
Clustering:属于无监督学习问题,旨在根据数据的内在相似性,将未标记的数据自动分组为不同的类别或簇。
-
Data summarization:属于信息压缩与呈现问题,旨在通过生成简洁的摘要(如关键点、代表性样本或可视化)来捕捉大型数据集或复杂数据的核心信息。
这些问题的共同特点:决策变量是 集合 (set) 不是连续变量。
例如:从1000个数据里选100个,从100个特征里选20个,组合数量是指数级的。
因此:
需要一种结构,使得 指数空间的问题仍然能高效优化。
这就是 Submodular Function 的意义。
作者提出一个很重要的类比:
| 连续优化 | 离散优化 |
| convex function | submodular function |
可以简单理解为:Submodular ≈ 离散版本的 convex/concave 结构 但其实更复杂。
二、什么是 Submodular Function(核心)
论文给出的正式定义是:
对于集合函数:
即:
输入:集合的子集
输出:一个数值
满足:
对所有集合 A,B。
这叫:
Submodular inequality
更直觉的理解
论文强调:
Submodularity = Diminishing Returns
即:
边际收益递减
数学表达:
当:
意思是:
同一个元素 e 加入 小集合 的价值 ≥ 加入 大集合 的价值
这就是 submodular 的核心思想。
可视化解释
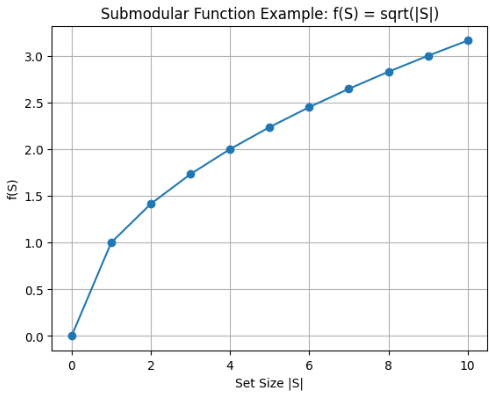
这张图表示:
f(S) = 集合 S 的“价值”
|S| = 集合大小(选了多少个元素)曲线特点:一开始增长很快,后面越来越平
|
集合大小 |
f(S) |
增长 |
|
0 → 1 |
0 → 1 |
+1 |
|
1 → 2 |
1 → 1.41 |
+0.41 |
|
2 → 3 |
1.41 → 1.73 |
+0.32 |
|
... |
... |
越来越小 |
这正是:边际收益递减(Diminishing Returns)
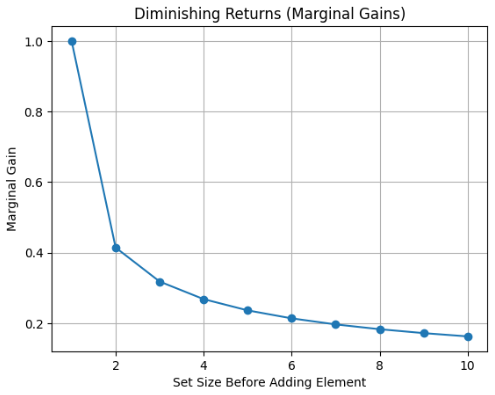
这张图更关键,它直接画的是:每增加一个元素,带来的“新增价值”
也就是:
f(S ∪ {x}) − f(S)可以看到:
- 第一个元素 → 增益最大(≈1)
- 后面越来越小(0.4 → 0.3 → 0.2 → ...)
这张图就是 Submodular 的本质图像
三、论文给出的例子
“朋友的价值”
设:f(S) = 朋友集合 S 的价值
如果你已经有很多朋友:再增加一个朋友的价值会==》 变小。如果你朋友很少那么==》新朋友价值 更大。
例如:
第 1个朋友:价值 10
第10个朋友:价值 1
所以:
f({}) → f({A}) 增量很大
f({A,B,C,D}) → f({A,B,C,D,E}) 增量较小
这就是传说中的:边际收益递减
四、论文里的复杂例子(咖啡、牛奶、茶)
论文用一个比较复杂的例子说明:
物品之间可能存在三种关系:
1 Submodular(替代关系)
例如: coffee + tea 两者功能类似。
所以:
f(coffee, tea) < f(coffee) + f(tea)
因为它们是 substitutes替代品
2 Supermodular(互补关系)
例如:coffee + milk 组合更好。
所以:
f(coffee, milk) > f(coffee) + f(milk)
叫:complementarity互补者
3 Modular(独立)
例如:lemon + milk 互不影响
f(A,B) = f(A) + f(B)
所以:
| 类型 | 数学 |
| Submodular | diminishing returns |
| Supermodular | increasing returns |
| Modular | linear |
五、信息论里的经典例子:Entropy
论文给了一个非常重要的结论:
Entropy 是 submodular 函数
设:f(S) = H(X_S)
即:某个变量集合的 entropy。
满足:
原因:互信息非负。
这在信息论里叫:Shannon inequality香农不等式。
六、常见 Submodular Function 类型
论文列了一些机器学习里常见的:
1 concave over cardinality
例如:
因为:
是 concave。
所以:边际增长递减。
2 Feature-based function
形式:
其中:是 concave
常见于:
NLP
document summarization
3 Facility Location(重要)
定义:
含义:每个点 i,找 S 中最像的点
用于:
-
data summarization
-
clustering
-
representative subset
4 Set Cover
含义:S 覆盖的元素数量。
常见:
document summarization
sensor placement
七、Submodular 为什么重要
因为它有 优化保证。
对于:
Submodular Maximization子模最大化
例如:
max f(S)
s.t. |S| ≤ k
使用:
Greedy algorithm贪心
可以保证:
$$(1 - 1/e) \approx 0.63$$
近似最优。
这是一个 非常强的理论保证。
八、机器学习中的应用
论文后半部分主要讲应用:
1 文本摘要
从 100 句新闻选 5 句。目标是覆盖尽量多信息,避免重复
这种目标函数很适合:submodular
2 数据集压缩
例如:100万训练样本,选1万代表样本
目标:覆盖整个数据分布
3 特征选择
例如:1000 个特征,选50 个
目标:信息最多,冗余最少
4 Active Learning
有 100 万未标注数据。
选择:最有信息的 1000 个去标注
九、总结
Submodular function 的本质:
一种具有“边际收益递减”性质的集合函数,使得许多指数级的离散优化问题可以高效近似求解。
它在机器学习中的作用类似于:convex function 在连续优化中的作用
拙见:
很多 AI 问题都是“从一堆东西里选一个子集”
例如:选数据、选句子、选特征、选代表点
如果目标函数是submodular、那么 用 greedy 算法就能得到接近最优的解
所以:submodular = 让组合优化变得可解
(WenJGo^_^全文完)
转载自CSDN-专业IT技术社区
原文链接:https://blog.csdn.net/DDDDWJDDDD/article/details/159354865

