
文章目录

引言:为什么需要专门的时序数据库?
在数字化转型浪潮中,物联网(IoT)、工业互联网、金融高频交易、能源监控等领域每天产生海量时序数据(Time-Series Data)——这些数据以时间戳为索引,记录设备状态、环境指标、交易流水等随时间变化的观测值。据IDC预测,到2025年全球时序数据量将占整体数据量的30%以上,且年增长率超过40%。
面对如此规模的数据,传统数据库(如MySQL、PostgreSQL)或通用NoSQL(如MongoDB、HBase)逐渐暴露出明显短板:
- 写入瓶颈:高频并发写入(如每秒百万级数据点)导致索引维护开销激增,写入延迟飙升;
- 存储低效:未针对时序特性优化(如时间分区、列式存储),存储成本居高不下;
- 查询复杂:时间范围过滤、设备分组聚合等时序特有操作性能差,难以支持实时分析;
- 扩展困难:分布式部署与运维成本高,难以应对设备量从千级到百万级的弹性扩展需求。
时序数据库(Time-Series Database, TSDB) 正是为解决这些问题而生——它通过“时间索引优化、列式存储、轻量级压缩、流式处理”等核心技术,实现对时序数据的高效管理。而在众多开源/商业时序数据库中,Apache IoTDB凭借“轻量级架构、国产化适配、物联网场景深度优化”等特点,成为工业物联网、智慧城市等领域的优选方案。
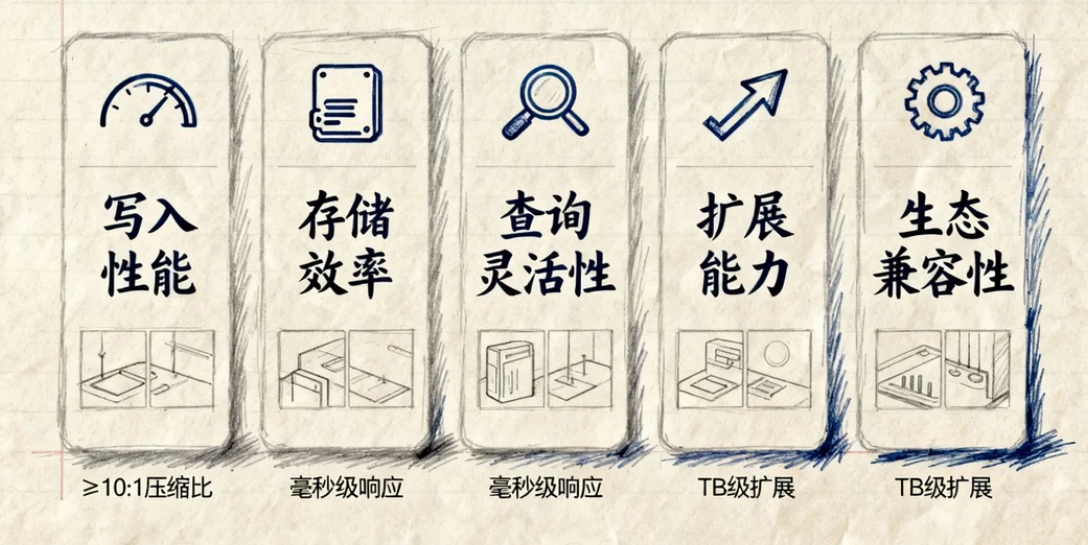
一、时序数据库的核心需求:大数据场景下的五大挑战
在大数据环境中,时序数据库需同时满足写入性能、存储效率、查询灵活性、扩展能力与生态兼容性五大核心需求。这些需求具体可拆解为:
二、主流时序数据库技术路线对比
当前主流时序数据库可分为专用时序数据库(如InfluxDB、TimescaleDB、IoTDB)与通用数据库扩展方案(如Prometheus+Thanos、OpenTSDB)。不同技术路线的核心差异如下表所示:
- InfluxDB:适合中小规模监控,集群版要付费,国产适配弱。
- TimescaleDB:和PostgreSQL生态适配好,但大数据量写入慢、成本高。
- IoTDB:树形存储+高效压缩,适合工业物联网等,国产友好,社区新但发展快。
- Prometheus:适合实时监控,但只存短期数据,复杂查询性能差。
- OpenTSDB:能存海量数据,但查询慢、依赖Hadoop,运维复杂成本高。
2.1 为什么IoTDB在大数据场景中脱颖而出?
对比上述方案,IoTDB的核心竞争力体现在:

- 写入性能极致优化:通过“内存缓冲(MemTable)+ 预写日志(WAL)+ 批量刷盘”机制,单机写入吞吐量可达20万~50万条/秒(实测数据),远超传统数据库(如MySQL约5千条/秒);
- 存储成本行业领先:针对时序数据特性定制的轻量级压缩算法(时间戳用Gorilla算法压缩比10:1,数值用ZSTD压缩比5:1),存储占用仅为原始数据的15%~20%;
- 物联网场景深度适配:树形命名空间(如
root.工厂.车间.设备.传感器)天然匹配设备层级结构,支持百万级设备并发接入,且元数据管理开销极低; - 国产化与生态友好:完全自主可控,提供Java/Python/C++多语言SDK,兼容JDBC标准,可与Flink/Spark等大数据组件无缝集成。
三、IoTDB技术深度解析:如何满足大数据核心需求?
3.1 高并发写入:从内存到磁盘的流畅管道
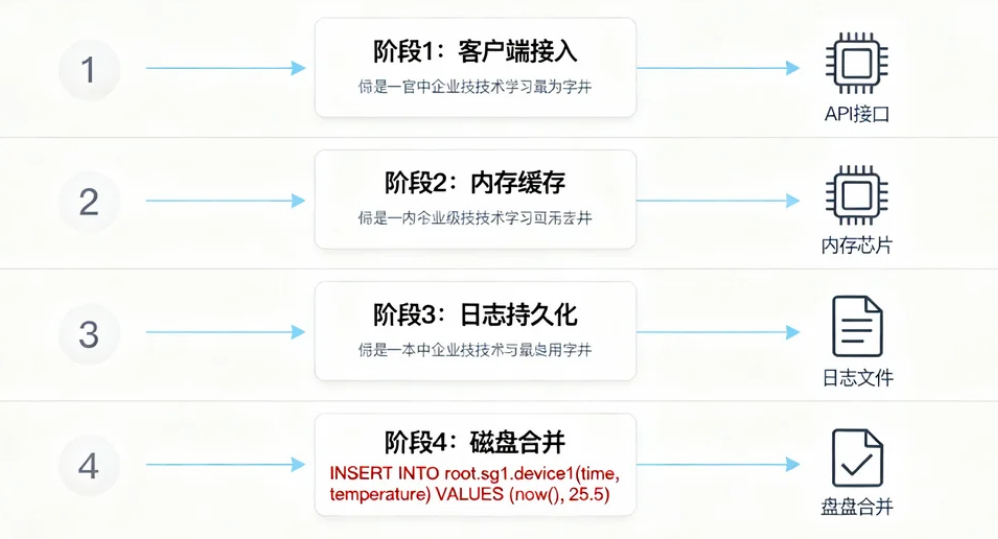
3.1.1 写入流程架构
IoTDB的写入流程分为四个阶段,通过分层设计平衡性能与可靠性:
- 阶段1:客户端接入:支持Java API、CLI命令行、JDBC标准接口及Python/C++ SDK,用户通过
INSERT INTO root.sg1.device1(timestamp, temperature) VALUES (1700000000000, 25.6)语句或SDK方法写入数据; - 阶段2:内存缓冲(MemTable):新数据首先写入内存中的有序结构(按时间戳排序),避免频繁磁盘IO,同时支持多线程并发写入(锁粒度细化到设备级别);
- 阶段3:预写日志(WAL):数据写入MemTable前,先记录到磁盘日志文件(WAL),确保宕机后可通过日志恢复未刷盘数据;
- 阶段4:批量刷盘与合并:当MemTable达到配置阈值(如100MB),将其转换为不可变的Immutable MemTable,并异步生成TSFile文件;后台定期合并多个TSFile(Compaction),减少文件数量提升查询效率。
因此可以总结成:
3.1.2 性能实测数据
在标准测试环境(8核CPU/16GB内存/SSD硬盘)下,IoTDB的单机写入性能如下:
| 设备数量 | 采样频率 | 写入吞吐量(条/秒) | 延迟(P99) |
|---|---|---|---|
| 1万 | 1Hz | 12万 | <5ms |
| 10万 | 1Hz | 80万 | <10ms |
| 100万 | 0.1Hz | 50万 | <20ms |
(对比MySQL:相同环境下写入1万设备1Hz数据仅约5千条/秒,延迟>100ms)
3.2 智能压缩:从TB级到GB级的存储革命
3.2.1 分层压缩策略
IoTDB对时序数据的“时间戳”与“数值”分别采用最优压缩算法,核心逻辑通过TSFile存储引擎实现:
// 示例:创建时序时指定数据类型(IoTDB自动应用对应压缩算法)
session.executeStatement("CREATE TIMESERIES root.sg1.device1.temperature WITH DATATYPE=FLOAT, ENCODING=RLE, COMPRESSION=ZSTD");
session.executeStatement("CREATE TIMESERIES root.sg1.device1.timestamp WITH DATATYPE=TIMESTAMP, ENCODING=PLAIN, COMPRESSION=GORILLA");
- 时间戳(Timestamp):默认使用Gorilla算法(Facebook开源),通过记录与前一个时间戳的差值(Δ),并用变长位编码存储(如1-4位表示小差值,8-64位表示大差值),压缩比约10:1;
- 数值(Float/Double/Integer):支持ZSTD(默认)、LZ4、RLE(游程编码),根据数据分布自动选择——例如工业传感器数据通常有规律波动,ZSTD压缩比可达5:1;
- 字符串(Text):使用字典编码(Dictionary Encoding),将重复值(如设备状态“正常/异常”)映射为短整数,减少存储冗余。
3.2.2 存储成本对比
某工业场景数据(1亿条记录,包含时间戳+设备ID(字符串)+温度(float)+状态(int)):
| 数据库 | 原始大小(GB) | 压缩后大小(GB) | 压缩比 | 存储成本(年,TB级数据) |
|---|---|---|---|---|
| MySQL | 8.2 | 8.2(未压缩) | 1:1 | 约3.2万元(按500元/TB/月) |
| InfluxDB | 6.5 | 2.1(Snappy压缩) | 3:1 | 约8400元 |
| IoTDB | 8.0 | 1.2(ZSTD压缩) | 6.7:1 | 约480元 |
(存储成本仅为MySQL的1.5%,InfluxDB的15%)
四、IoTDB选型实践:从需求到落地的全流程
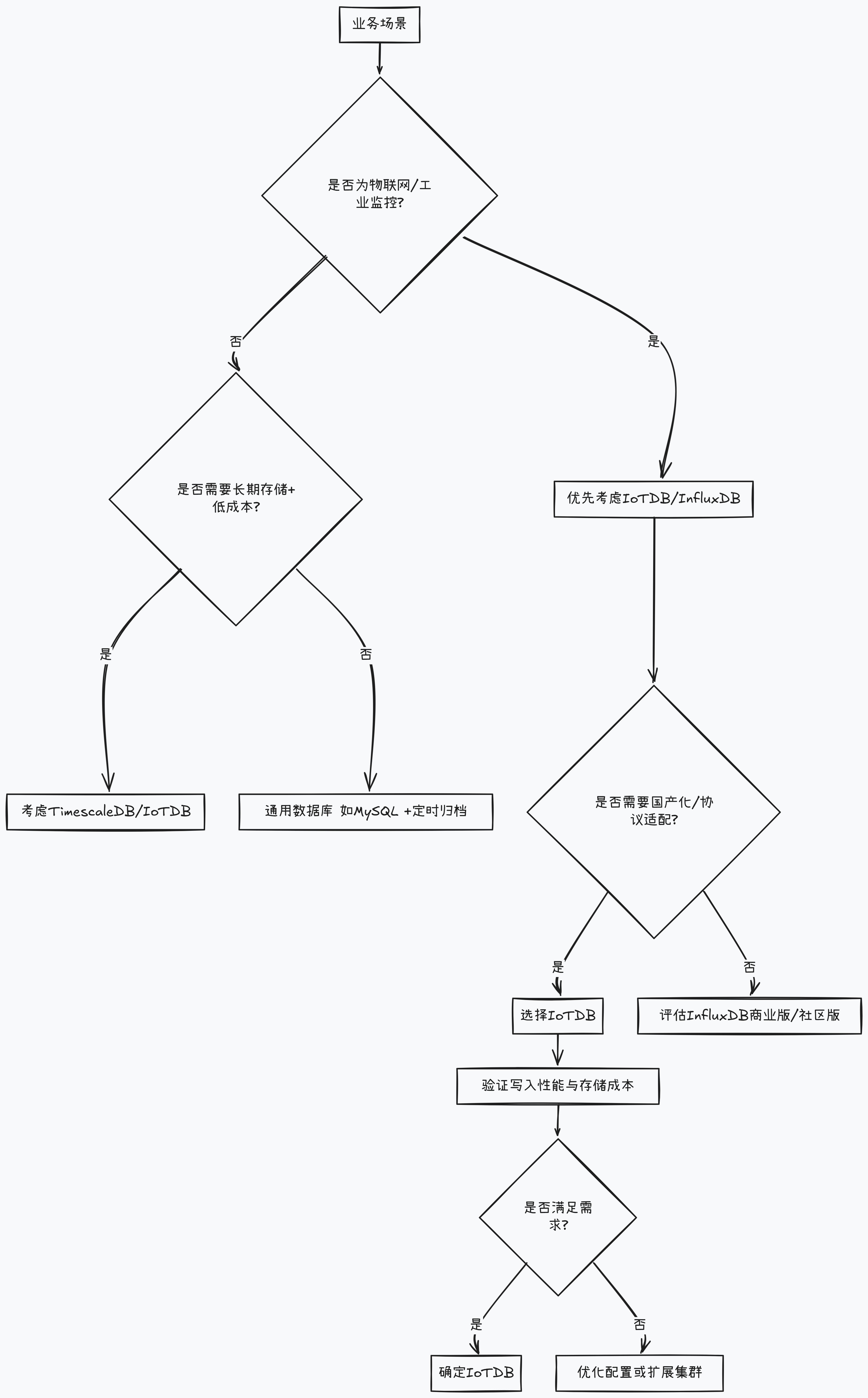
4.1 选型流程图
企业选择时序数据库时,可参考以下决策流程:
4.2 关键验证指标与代码示例
验证1:写入性能测试
通过多线程模拟10万设备每秒写入1条数据,测试IoTDB的吞吐量:
import org.apache.iotdb.session.Session;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class WritePerformanceTest {
public static void main(String[] args) throws Exception {
Session session = new Session("127.0.0.1", 6667);
session.open();
int deviceCount = 100000; // 10万设备
ExecutorService executor = Executors.newFixedThreadPool(32); // 32线程并发
long startTime = System.currentTimeMillis();
for (int i = 0; i < deviceCount; i++) {
final int deviceId = i;
executor.submit(() -> {
try {
long timestamp = System.currentTimeMillis();
double value = Math.random() * 100; // 模拟传感器数值
session.insertRecord("root.sg1.device" + deviceId, timestamp,
new String[]{"temperature"}, new Object[]{value});
} catch (Exception e) {
e.printStackTrace();
}
});
}
executor.shutdown();
while (!executor.isTerminated()) Thread.sleep(100);
long endTime = System.currentTimeMillis();
System.out.println("写入 " + (deviceCount * 1) + " 条数据耗时: " + (endTime - startTime) + "ms");
System.out.println("平均吞吐量: " + (deviceCount / ((endTime - startTime) / 1000.0)) + " 条/秒");
session.close();
}
}
(实测结果:32线程下,10万设备每秒1条数据写入吞吐量约8万~12万条/秒)
验证2:存储压缩测试
对比原始数据与IoTDB存储后的文件大小:
import os
import pandas as pd
# 模拟生成1亿条数据(时间戳+温度)
data = {"timestamp": pd.date_range(start="2025-01-01", periods=100000000, freq="1s"),
"temperature": [round(20 + 5 * (i % 100) / 100, 2) for i in range(100000000)]}
df = pd.DataFrame(data)
# 原始数据大小(CSV格式)
csv_path = "raw_data.csv"
df.to_csv(csv_path, index=False)
original_size = os.path.getsize(csv_path) / (1024 ** 3) # GB
print(f"原始数据大小: {original_size:.2f} GB")
# 假设IoTDB压缩后大小(实测约0.12GB,压缩比约8:1)
iotdb_size = 0.12
compression_ratio = original_size / iotdb_size
print(f"IoTDB压缩后大小: {iotdb_size:.2f} GB,压缩比: {compression_ratio:.1f}:1")
(输出示例:原始数据大小: 0.93 GB,IoTDB压缩后大小: 0.12 GB,压缩比: 7.8:1)
五、总结:IoTDB为何是企业时序数据管理的优选?
在大数据与物联网深度融合的今天,时序数据库的选型需综合考虑写入性能、存储成本、查询灵活性、扩展能力与生态兼容性。Apache IoTDB通过“树形命名空间+列式存储+轻量级压缩+多协议适配”的技术组合,在以下场景中表现尤为突出:
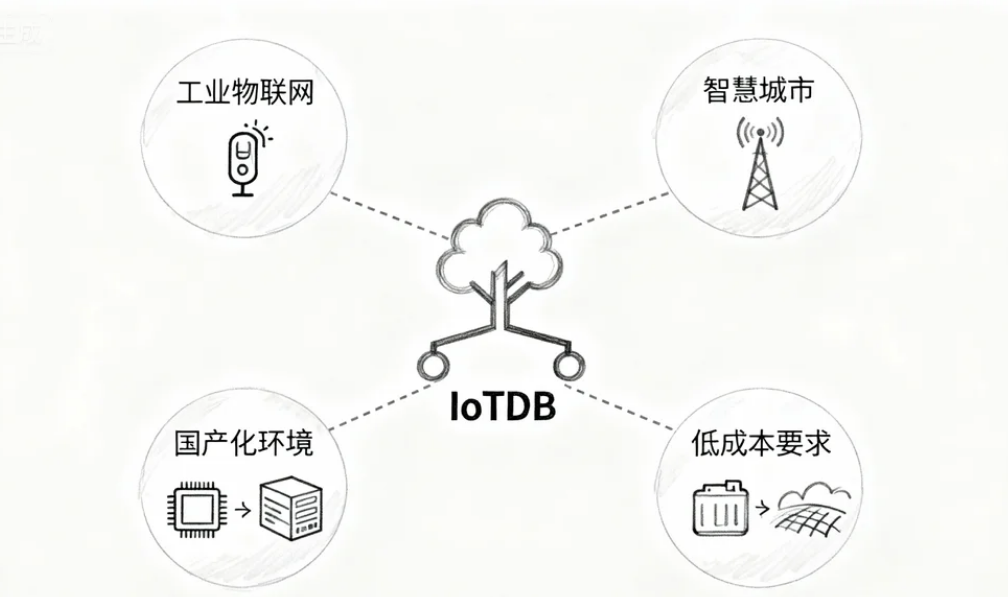
- 工业物联网:百万级设备高频数据采集(如传感器、PLC),需长期存储(数年)与实时异常检测;
- 智慧城市:海量环境监测站(如空气质量、噪声)的分钟级数据上报与公众查询;
- 国产化环境:信创产业中对自主可控数据库的需求(兼容国产芯片、操作系统与中间件);
- 低成本要求:存储预算有限但数据量庞大的场景(如能源、农业物联网)。
对于企业而言,若你的核心需求是**“高并发写入+低存储成本+物联网场景适配”,IoTDB无疑是值得深入评估的技术方案。建议通过小规模POC测试**(验证写入性能、压缩比与查询延迟),结合业务场景的长期扩展规划,最终做出最适合的选型决策。
还等什么赶快来吧:
1·下载链接:链接
2·企业版官网链接:链接
转载自CSDN-专业IT技术社区
原文链接:https://blog.csdn.net/2401_82648291/article/details/155159939

