
一、引言
在信息爆炸的互联网时代,新闻数据的时效性和完整性对商业情报分析至关重要。然而,面对频繁更新的新闻网站,如何设计一个既能保证数据完整性,又能避免重复抓取的爬虫系统,一直是技术难点。
本文将深入分析一个针对 chemanalyst.com 新闻站点的爬虫设计案例。该爬虫巧妙解决了 “周期性抓取中的去重判断” 和 “增量更新的边界控制” 两大核心难题,实现了高效、智能的数据采集。
核心挑战:
- 如何避免已抓取新闻的重复采集?
- 如何精确控制抓取的时间窗口?
- 如何在同一个流程中完成列表页遍历和详情页抓取?
二、系统架构与核心流程
2.1 整体架构设计
该爬虫采用了 “分阶段处理 + 数据库状态驱动” 的架构,整体分为三个阶段:
2.2 数据流向图
三、关键技术难点与解决方案
难点一:动态时间窗口的精确控制
问题描述:
爬虫需要抓取最近7天的新闻,但新闻列表页的分页参数是固定的(page=1,2,3…)。如果简单地从第1页抓到最后一页,会抓取大量过时数据,浪费资源。
解决方案:
采用 “动态时间范围预计算” 策略:
// 获取时间范围节点配置
{
"variable-name": ["start_date", "end_date"],
"variable-value": [
"${date.format(date.addDays(date.now(),-7),'yyyy-MM-dd')}",
"${date.format(date.addDays(date.now(),1),'yyyy-MM-dd')}"
]
}
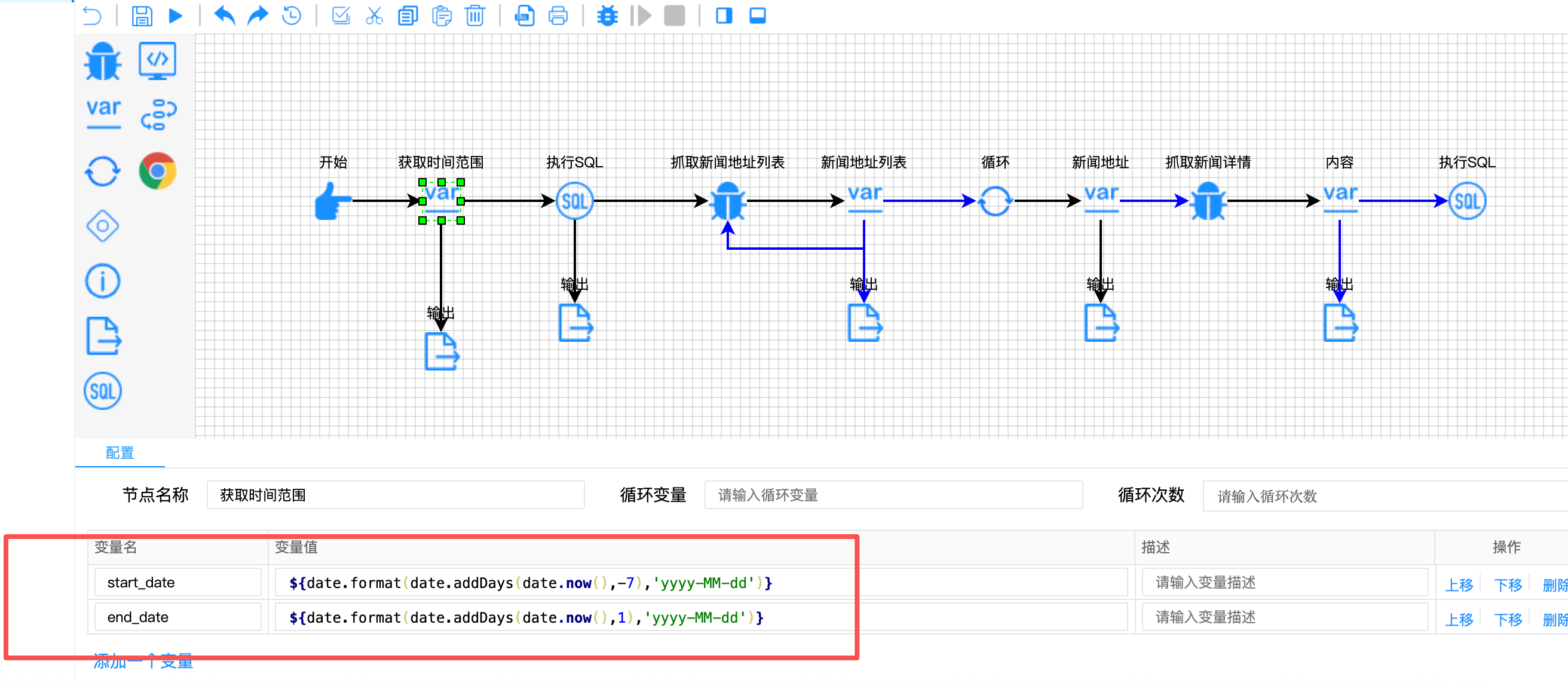
技术亮点:
- 动态日期计算:使用内置的
date对象函数,自动计算7天前和明天的时间边界 - SQL时间过滤:后续的查询语句使用这两个参数,精确控制数据范围
- 无需人工干预:每次运行自动调整时间窗口,保证抓取的时效性
原理示意图:
难点二:高效的去重机制设计
问题描述:
新闻列表页每页可能包含10-20条新闻,其中大部分可能已经在之前的抓取中收录。如果全部重新抓取,不仅浪费资源,还可能被封IP。
解决方案:
构建 “双层去重” 机制:
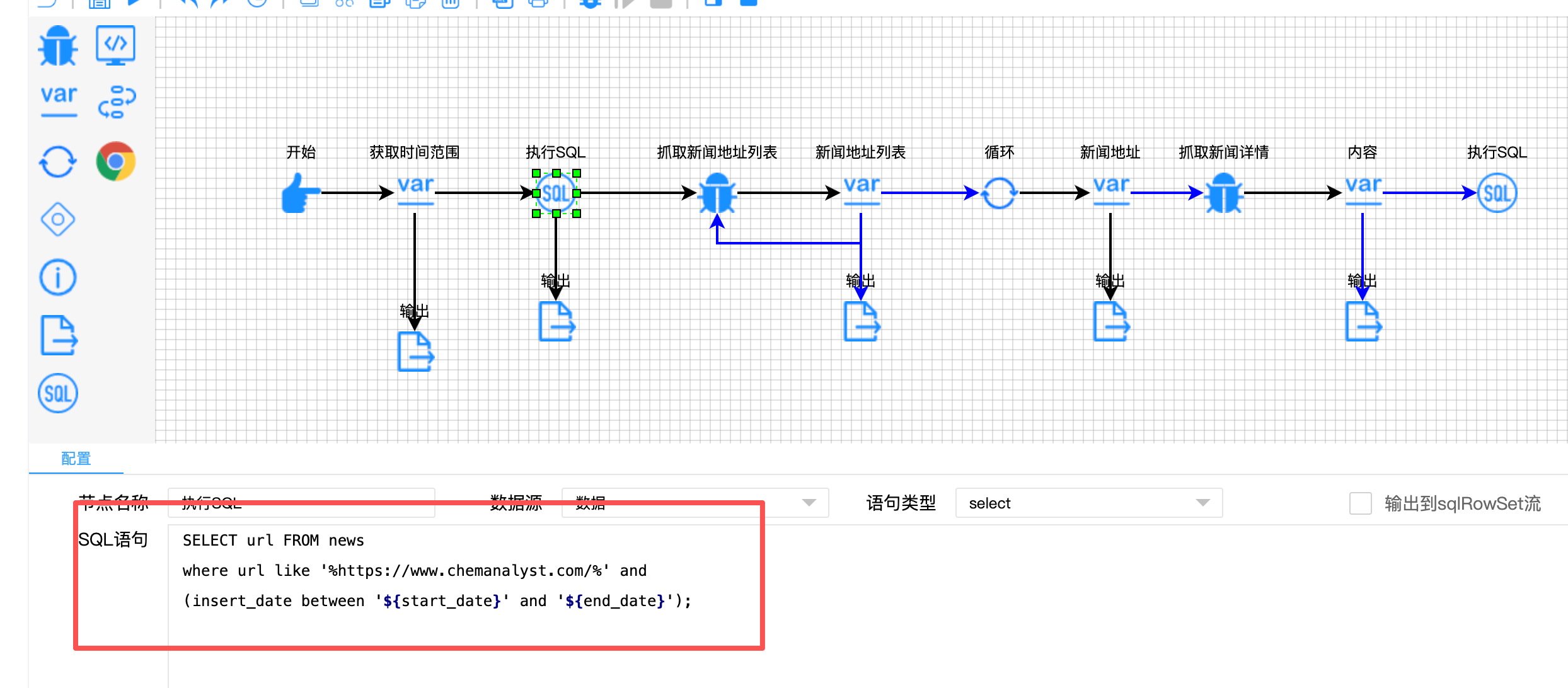
第一层:数据库预查询去重
SELECT url FROM news
where url like '%https://www.chemanalyst.com/%'
and (insert_date between '${start_date}' and '${end_date}');
第二层:运行时实时判断
// 新闻地址节点配置
{
"variable-name": ["news_url", "news_title", "news_id", "news_urlmap", "query_result"],
"variable-value": [
"https://www.chemanalyst.com${news_urllist[index]}",
"${news_titlelist[index]}",
"${news_url.regx('(\\d+)(?=$)').toInt()}",
"${{'url': news_url}}",
"${!rs.contains(news_urlmap)}" // 核心去重判断
]
}
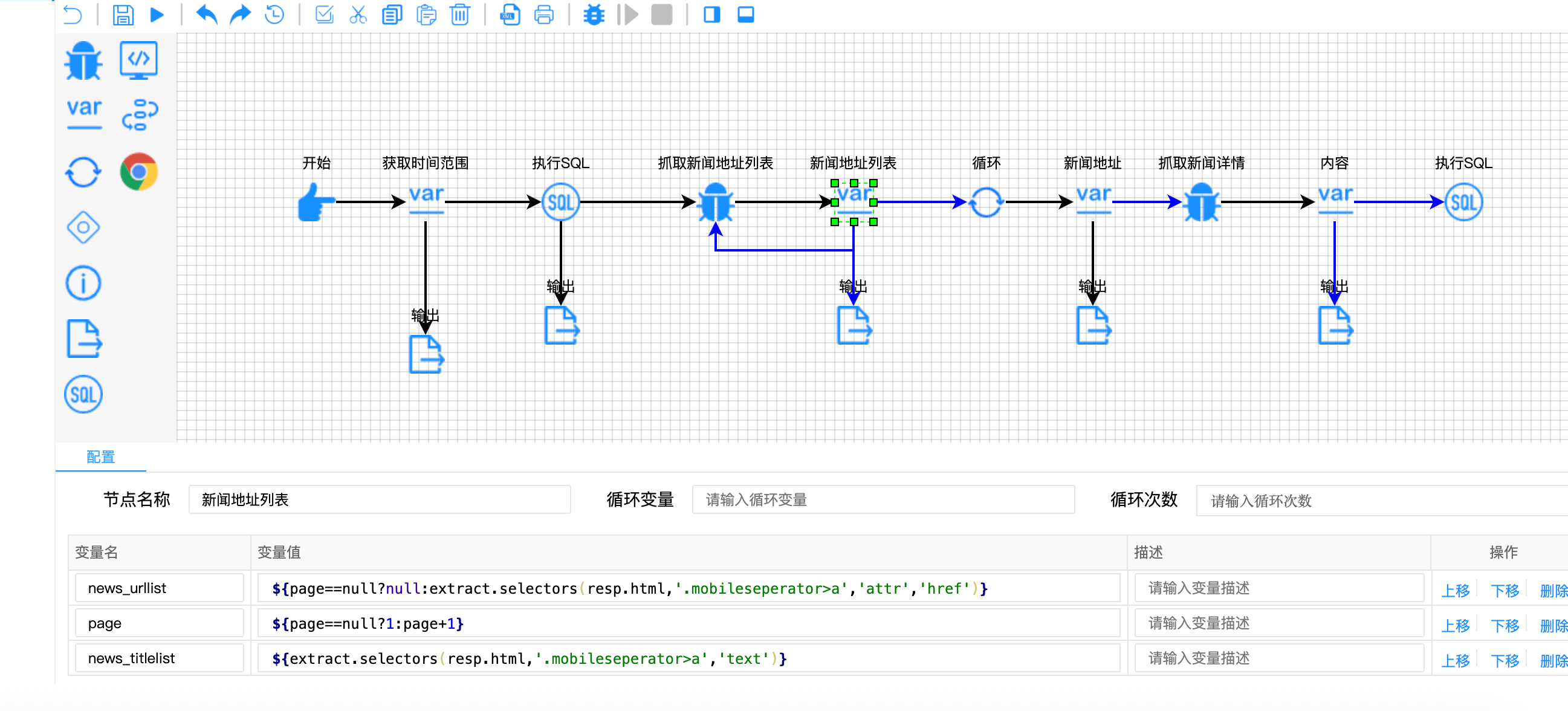
关键技术点解析:
- Map结构构造:
${{'url': news_url}}将URL转换为Map对象,便于后续判断 - 集合包含判断:
rs.contains(news_urlmap)检查URL是否已存在于数据库查询结果中 - 取反操作:
!符号将判断结果反转,实现“不存在则继续”的逻辑
去重流程示意图:
难点三:复杂数据结构提取与转换
问题描述:
新闻详情页需要提取标题、发布时间、作者、正文等多个字段,且不同字段的CSS选择器各异。此外,新闻ID需要从URL中正则提取。
解决方案:
采用 “声明式数据提取” 模式,将提取逻辑与流程控制分离:
// 新闻详情提取配置
{
"variable-name": ["title", "release_date", "author", "content"],
"variable-value": [
"${extract.selector(resp.html, '.blog-detail-summary>h1')}",
"${extract.selector(resp.html, '.relaventnewspublisheddate span', 'text')}",
"${extract.selector(resp.html, '.relaventnewspublisheddate li:nth-child(2)>span')}",
"${extract.selector(resp.html, '.blog-list-data')}"
]
}
// ID提取:使用正则表达式
"${news_url.regx('(\\d+)(?=$)').toInt()}"
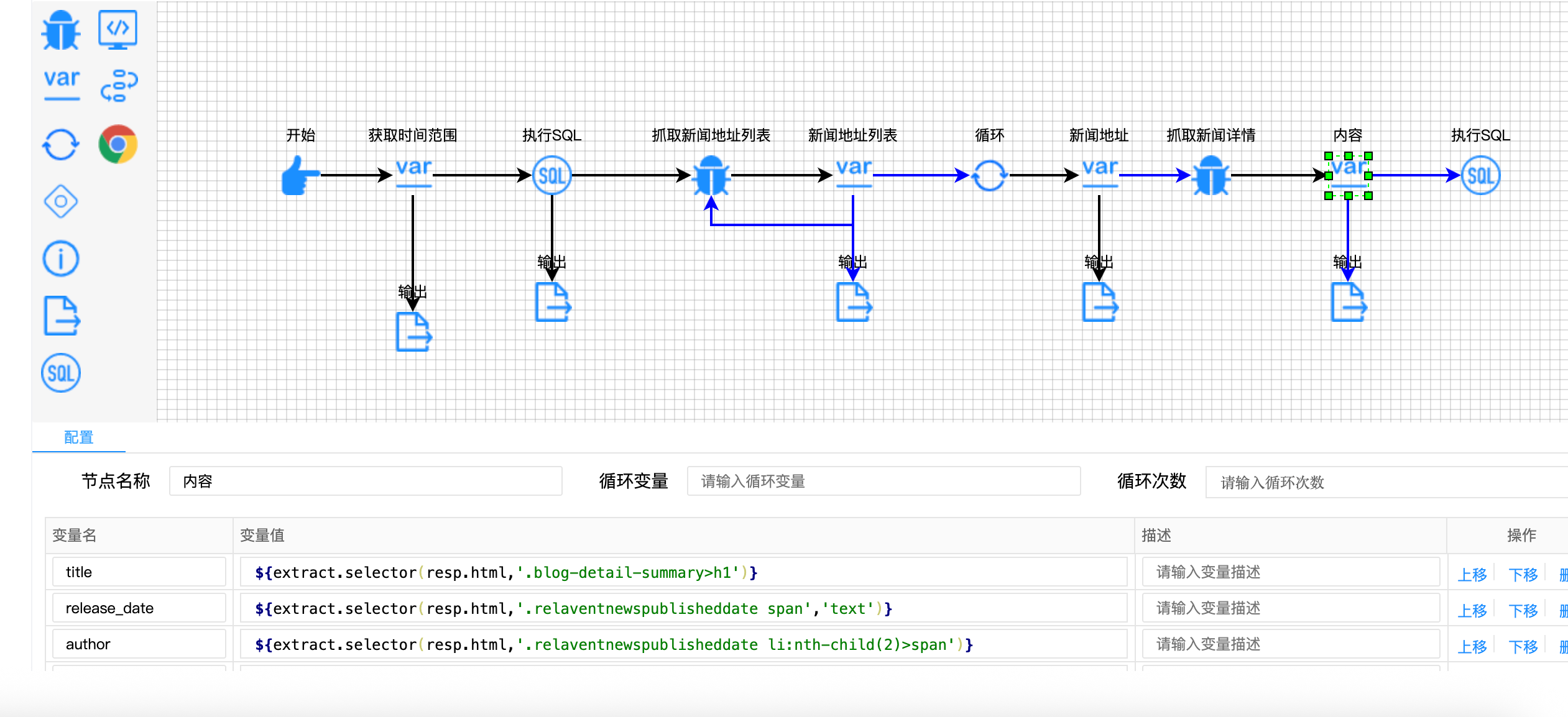
技术亮点:
- 链式调用:
resp.html直接调用选择器方法,简洁高效 - 多参数支持:选择器支持指定返回类型(text/html/attr)
- 正则表达式:
regx()方法配合正则可提取URL中的数字ID - 类型转换:
.toInt()确保ID存储为正确的数据类型
难点四:分页循环的条件控制
问题描述:
新闻列表页需要从第1页抓取到第23页,但爬虫需要知道何时停止。同时,列表抓取和详情抓取是两个不同的循环,需要协同工作。
解决方案:
构建 “双循环协同” 控制结构:
// 分页控制条件(蓝色连线)
"condition": "${page<=23}"
// 列表循环条件
"condition": "${news_urllist!=null}"
// 详情循环次数
"loopCount": "${list.length(news_urllist)}"
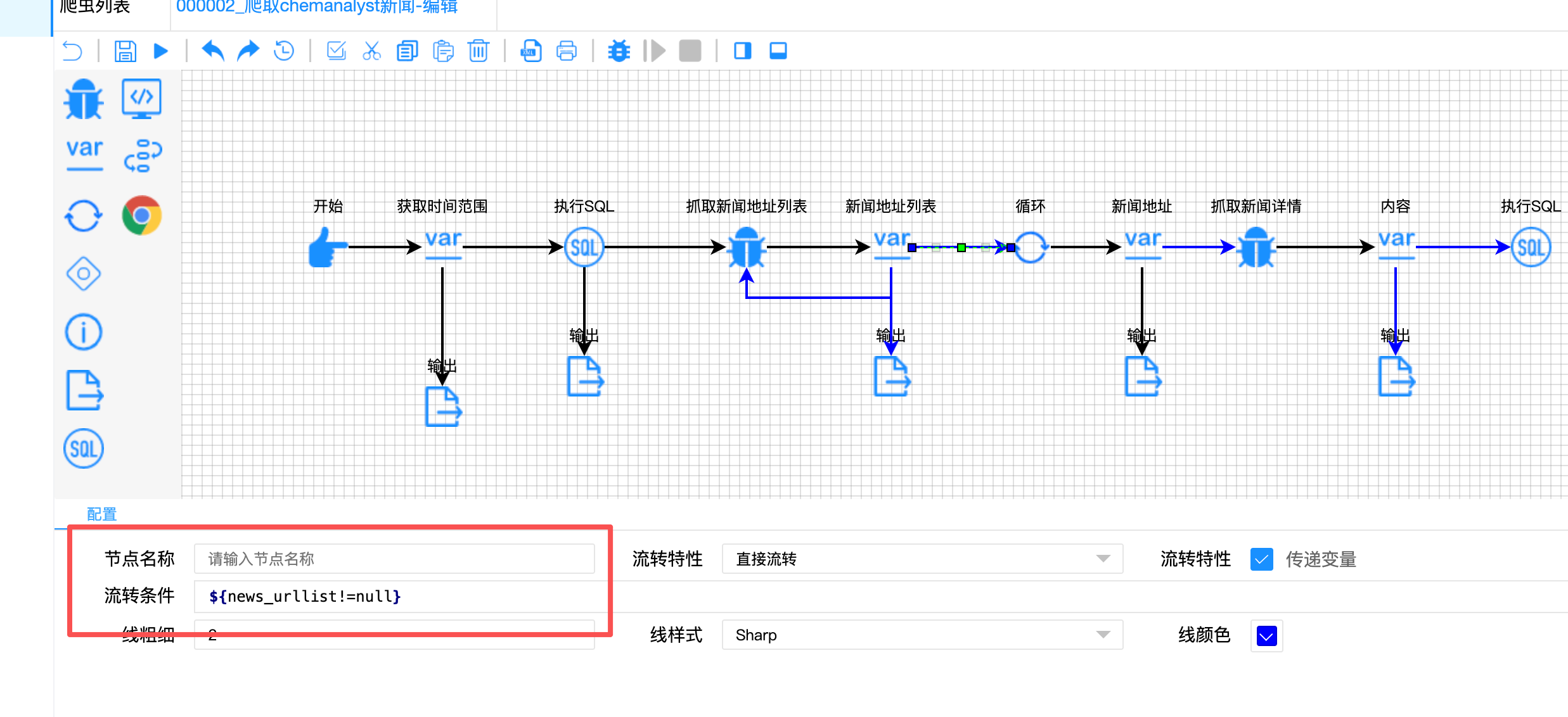
循环控制示意图:
难点五:异常处理与流程韧性
问题描述:
网络请求可能失败,页面结构可能变化,数据库可能暂时不可用。爬虫需要具备容错能力。
解决方案:
在关键节点设置容错机制:
// 请求节点配置
{
"retryCount": "3", // 失败重试3次
"retryInterval": "5000", // 重试间隔5秒
"timeout": "30000", // 超时时间30秒
"sleep": "5000" // 请求间隔5秒
}
// 条件分支保护
"condition": "${content!=null}" // 只有内容不为空才继续
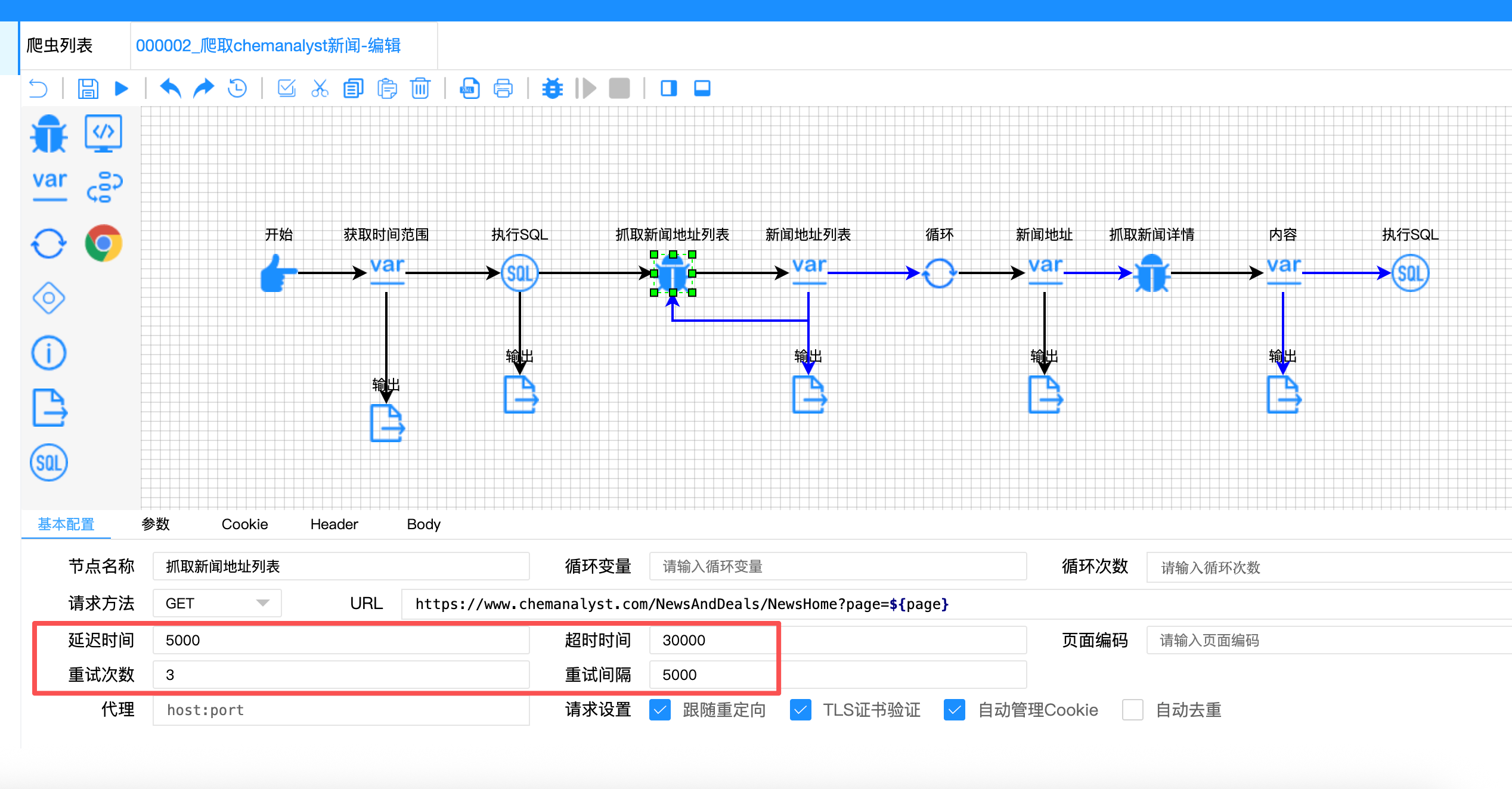
四、核心代码实现解析
4.1 主流程控制代码
// 伪代码:主流程控制逻辑
async function main() {
// 阶段1:初始化时间窗口
const start_date = date.addDays(now, -7);
const end_date = date.addDays(now, 1);
// 阶段2:查询数据库已抓取记录
const rs = await executeSQL(`
SELECT url FROM news
WHERE insert_date BETWEEN '${start_date}' AND '${end_date}'
`);
// 阶段3:分页抓取
for (let page = 1; page <= 23; page++) {
const listResp = await request(
`https://www.chemanalyst.com/NewsAndDeals/NewsHome?page=${page}`
);
const urls = extract.selectors(listResp.html, '.mobileseperator>a', 'attr', 'href');
const titles = extract.selectors(listResp.html, '.mobileseperator>a', 'text');
// 阶段4:详情页处理
for (let i = 0; i < urls.length; i++) {
const news_url = `https://www.chemanalyst.com${urls[i]}`;
const urlMap = {'url': news_url};
// 去重判断
if (!rs.contains(urlMap)) {
await processNewsDetail(news_url, titles[i]);
await sleep(5000); // 礼貌抓取
}
}
}
}
4.2 去重机制的核心实现
// 去重判断的核心逻辑
class DuplicateChecker {
constructor(existingRecords) {
this.existingSet = new Set(
existingRecords.map(record => record.url)
);
}
isDuplicate(url) {
// 标准化URL后判断
const normalizedUrl = this.normalizeUrl(url);
return this.existingSet.has(normalizedUrl);
}
normalizeUrl(url) {
// 移除URL末尾的斜杠等标准化操作
return url.replace(/\/$/, '');
}
}
// 使用示例
const checker = new DuplicateChecker(rs);
if (!checker.isDuplicate(news_url)) {
// 抓取新新闻
}
4.3 数据提取的链式处理
// 数据提取与转换的链式操作
class DataExtractor {
extractNewsId(url) {
// 正则提取数字ID
const matches = url.match(/(\d+)(?=$)/);
return matches ? parseInt(matches[0]) : null;
}
async extractNewsDetail(html) {
return {
title: this.extractText(html, '.blog-detail-summary>h1'),
releaseDate: this.extractText(html, '.relaventnewspublisheddate span'),
author: this.extractText(html, '.relaventnewspublisheddate li:nth-child(2)>span'),
content: this.extractHtml(html, '.blog-list-data')
};
}
}
五、性能优化与最佳实践
5.1 请求控制策略
- 动态请求间隔:5秒固定间隔,避免请求频率过高
- 重试机制:3次重试,5秒间隔,应对临时网络问题
- 超时控制:30秒超时,避免长时间阻塞
5.2 内存优化
- 流式处理:大数据量时采用流式处理,避免内存溢出
- 分批处理:新闻列表分页处理,每页独立内存空间
5.3 数据一致性保障
- 事务处理:数据库操作支持事务,确保数据一致性
- 幂等设计:相同URL多次执行不会产生重复数据
六、总结与经验分享
6.1 核心收获
- 数据库状态驱动:利用数据库已有数据作为状态判断依据,实现精准增量抓取
- 声明式配置:将提取逻辑与流程控制分离,提高可维护性
- 双层循环协同:分页循环和详情循环的协同控制,提高抓取效率
6.2 可复用经验
- 时间窗口设计:对于时间敏感的数据,使用动态时间窗口比固定页数更高效
- Map去重法:将URL转为Map对象进行集合判断,比字符串匹配更可靠
- 条件分支保护:在关键节点添加条件判断,避免异常数据进入下游
6.3 适用场景
该爬虫设计模式适用于:
- 新闻资讯类网站的定期抓取
- 电商商品信息的增量更新
- 社交媒体内容的持续监控
- 任何需要去重和增量抓取的场景
七、附录:核心配置对照表
| 节点类型 | 核心作用 | 关键技术点 |
|---|---|---|
| 获取时间范围 | 动态计算时间窗口 | date.addDays(), date.format() |
| 执行SQL(查询) | 获取已抓取记录 | between语句,like模糊匹配 |
| 抓取新闻地址列表 | 分页获取列表 | ${page}变量,循环条件控制 |
| 新闻地址列表 | 提取URL和标题 | extract.selectors()多字段提取 |
| 循环 | 遍历每条新闻 | list.length()动态计算循环次数 |
| 新闻地址 | 数据处理与去重 | regx()提取ID,Map构造,集合判断 |
| 抓取新闻详情 | 获取详情页 | 重试机制,请求间隔控制 |
| 内容 | 提取结构化数据 | 多选择器组合,条件保护 |
| 执行SQL(插入) | 存储数据 | 参数化SQL,多字段映射 |
通过以上设计,该爬虫成功实现了对chemanalyst.com新闻网站的高效增量抓取,既保证了数据的时效性,又避免了重复抓取的资源浪费。其中的去重设计、时间窗口控制和双层循环协同等思路,对于类似场景的爬虫开发具有很高的参考价值。
转载自CSDN-专业IT技术社区
原文链接:https://blog.csdn.net/LYX_WIN/article/details/159168649

