
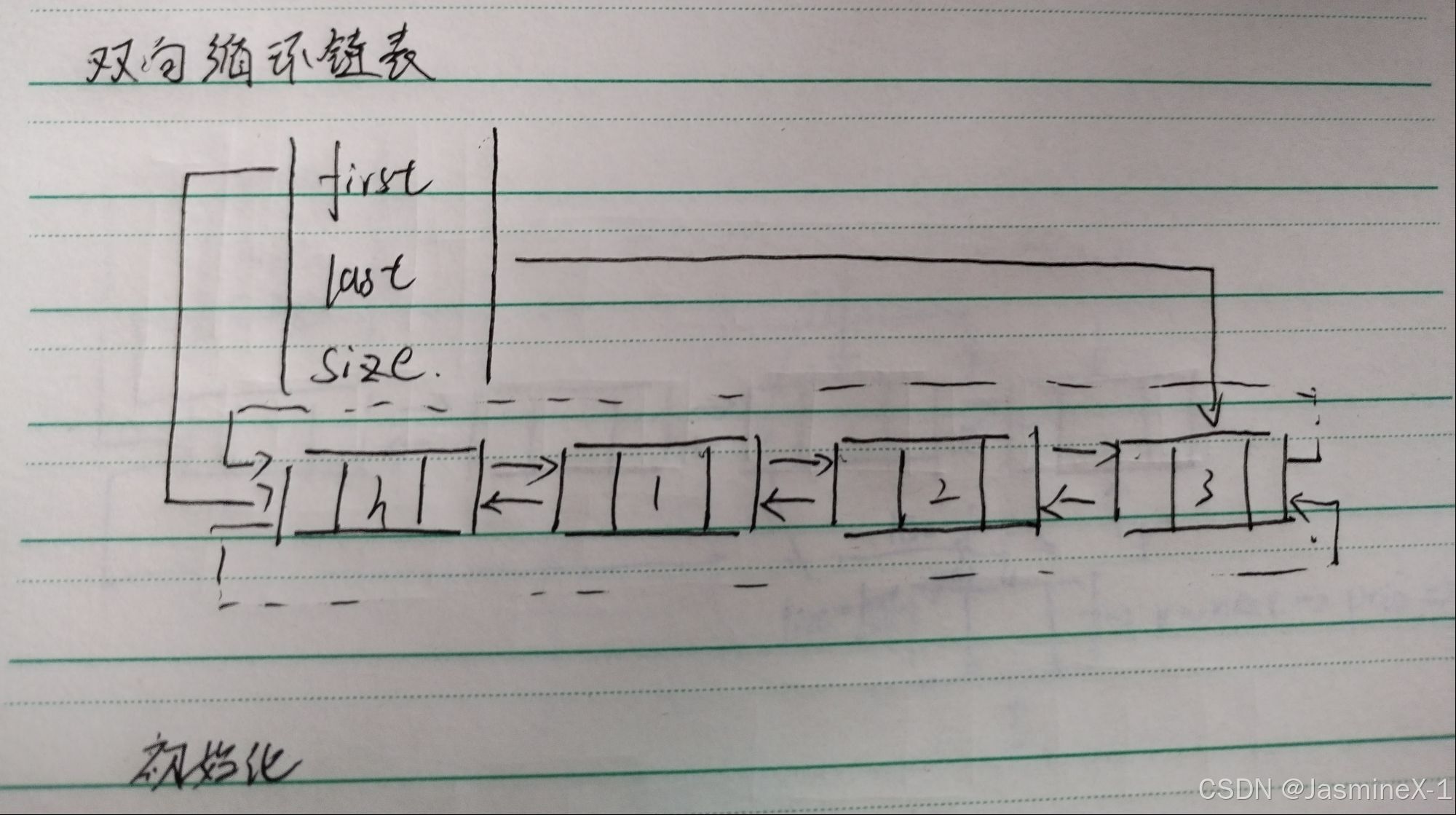
 1.特点
1.特点
| 项目 | 内容 |
|---|---|
| 定义 | 一种链式存储结构,每个结点包含 数据域、前驱指针(prio) 和 后继指针(next),且首尾结点相连形成一个环 |
| 指针数量 | 每个结点有两个指针:prio 指向前驱结点,next 指向后继结点 |
| 头结点特点 | 常设一个头结点,头结点的 prio 指向尾结点,next 指向首结点 |
| 尾结点特点 | 尾结点的 next 指向头结点,头结点的 prio 指向尾结点 |
| 访问方向 | 可以从任意结点开始,既能向前(prio)遍历,也能向后(next)遍历,且最终能回到起始点 |
| 存储方式 | 逻辑连续,物理地址不要求连续 |
2.双向循环链表的优缺点
| 优点 | 缺点 |
|---|---|
| 可以 双向遍历,比单向循环链表更灵活 | 每个结点需要两个指针,空间开销更大 |
| 从任意结点出发都能完整访问整个链表 | 插入和删除时需要维护两个方向的指针,操作复杂度高于单链表 |
| 删除和插入都可以在 O(1) 时间完成(已知结点指针时) | 实现逻辑比单链表更复杂 |
3.主要代码
申请结点
Node* _buynode(ElemType x)
{
Node* s = (Node*)malloc(sizeof(Node));
assert(s != NULL);
s->data = x;
s->next = s->prio = NULL;
return s;
}
目的:申请并返回一个新的节点,初始化 data,把 next/prio 置空,等待插入。
实现步骤
malloc 分配内存(若失败,assert 触发)。
把 x 存入 s->data。
s->next = s->prio = NULL:确保新节点的双向指针初态为 NULL(插入时会赋值)。
返回 s。
复杂度:O(1)。
初始化
void InitDCList(List* list)
{
Node* s = (Node*)malloc(sizeof(Node));
assert(s != NULL);
list->first = list->last = s;
list->first->prio = list->last;
list->last->next = list->first;
list->size = 0;
}
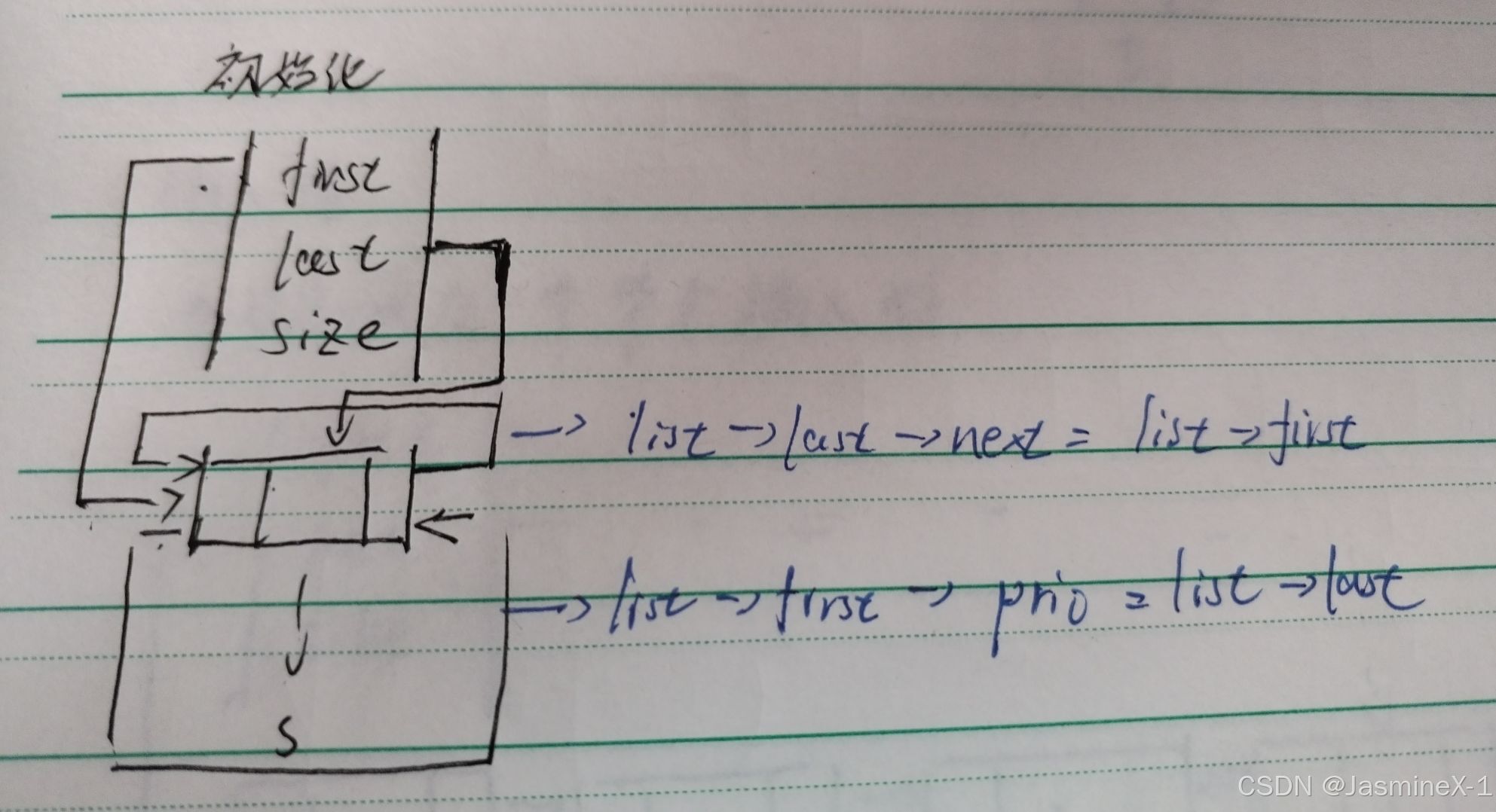
目的:初始化双向循环链表 —— 创建头哨兵并把链表置为空环状态。
实现步骤
分配一个头结点 s(哨兵)。
list->first = list->last = s;:头和尾都指向同一个哨兵(表示空表)。
list->first->prio = list->last; 和 list->last->next = list->first;:当 first==last 时等价于 s->prio = s 与 s->next = s,构成长度为 0 的循环(方便以后插入统一处理)。
list->size = 0。
复杂度:O(1)。
尾插
void push_back(List* list, ElemType x)
{
Node* s = _buynode(x);
s->next = list->last->next;
s->next->prio = s;
s->prio = list->last;
list->last->next = s;
list->last = s;
list->size++;
}
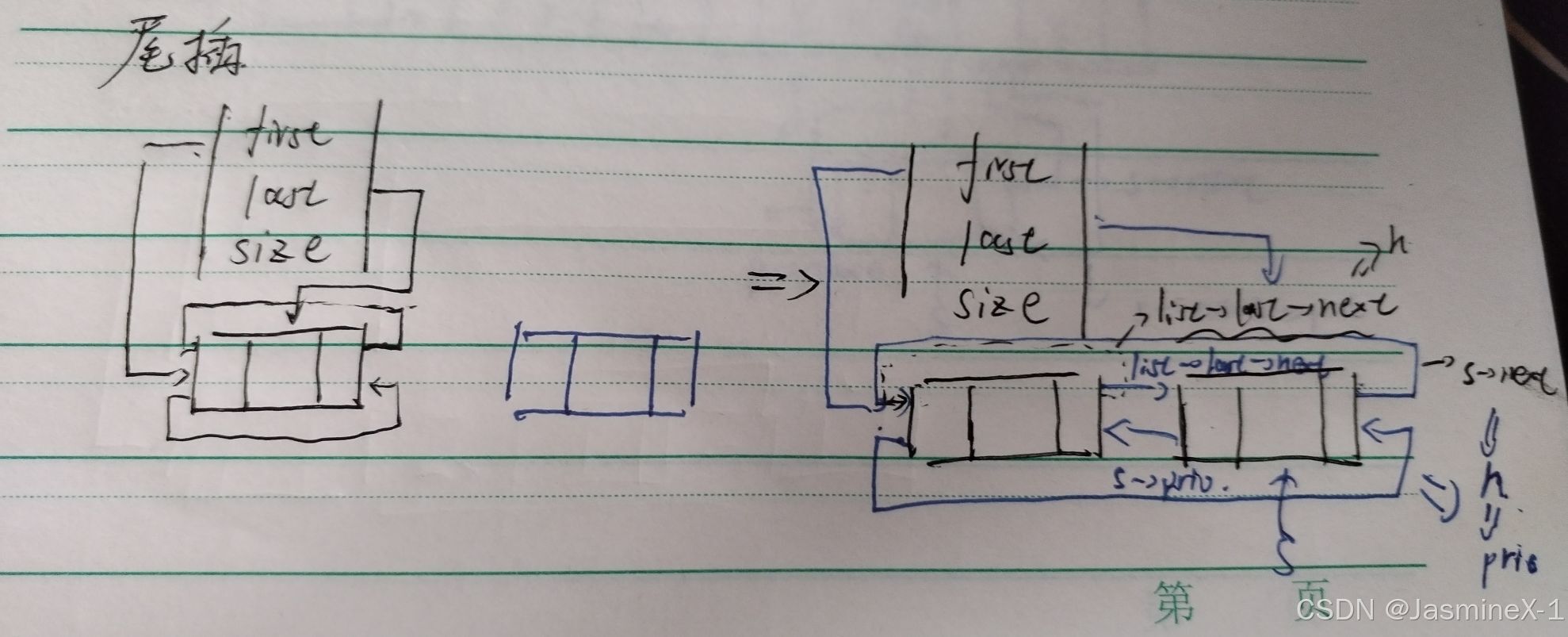
目的:在链表尾部**(last 后面)** 插入新节点(保持循环结构)。
逐步说明(指针变化)
s = _buynode(x):创建新节点 s,s->next/prio == NULL。
s->next = list->last->next;
list->last->next 原本是头结点(first),因为是循环结构。把 s->next 指向头结点。
s->next->prio = s;
把头结点的 prio 更新为 s(头的前驱变为新尾)。
s->prio = list->last;
设置新节点的前驱为旧尾节点。
list->last->next = s;
旧尾的 next 指向新节点,完成旧尾 -> s 的连接。
list->last = s;:更新 last 指向新尾。
list->size++。
复杂度:O(1)。
头插
void push_front(List* list, ElemType x)
{
Node* s = _buynode(x);
s->next = list->first->next;
s->next->prio = s;
s->prio = list->first;
list->first->next = s;
if (list->first == list->last)
list->last = s;
list->size++;
}
目的:在头结点之后插入新节点(成为新的第一个有效节点)。
逐步说明
s = _buynode(x):创建新节点。
s->next = list->first->next;:让 s 指向原来的第一个节点(若空表 first->next == first,此时指向头)。
s->next->prio = s;:把原第一个节点(或头) 的 prio 更新为 s。
s->prio = list->first;:新节点的 prio 指向头结点。
list->first->next = s;:头结点的 next 指向 s,完成插入。
如果原来是空表(first==last),则 list->last = s; 把尾也指向新节点。
list->size++。
复杂度:O(1)。
显示
void show_list(List* list)
{
Node* p = list->first->next;
while (p != list->first)
{
printf("%d-->", p->data);
p = p->next;
}
printf("Nul.\n");
}
目的:从头到尾按顺序打印所有有效节点(不打印头)。
逐步说明
从 p = first->next(第一个有效节点或 first 本身)开始。
当 p != first 时循环:输出数据并 p = p->next。
循环结束(回到头)打印结束标识。
复杂度:O(n)。
注意:输出顺序为从首到尾;因是循环结构,必须判断 p == first 才停止。
尾删
void pop_back(List* list)
{
if (list->size == 0)
return;
Node* p = list->last;
list->last = list->last->prio;
p->next->prio = p->prio;
p->prio->next = p->next;
free(p);
list->size--;
}
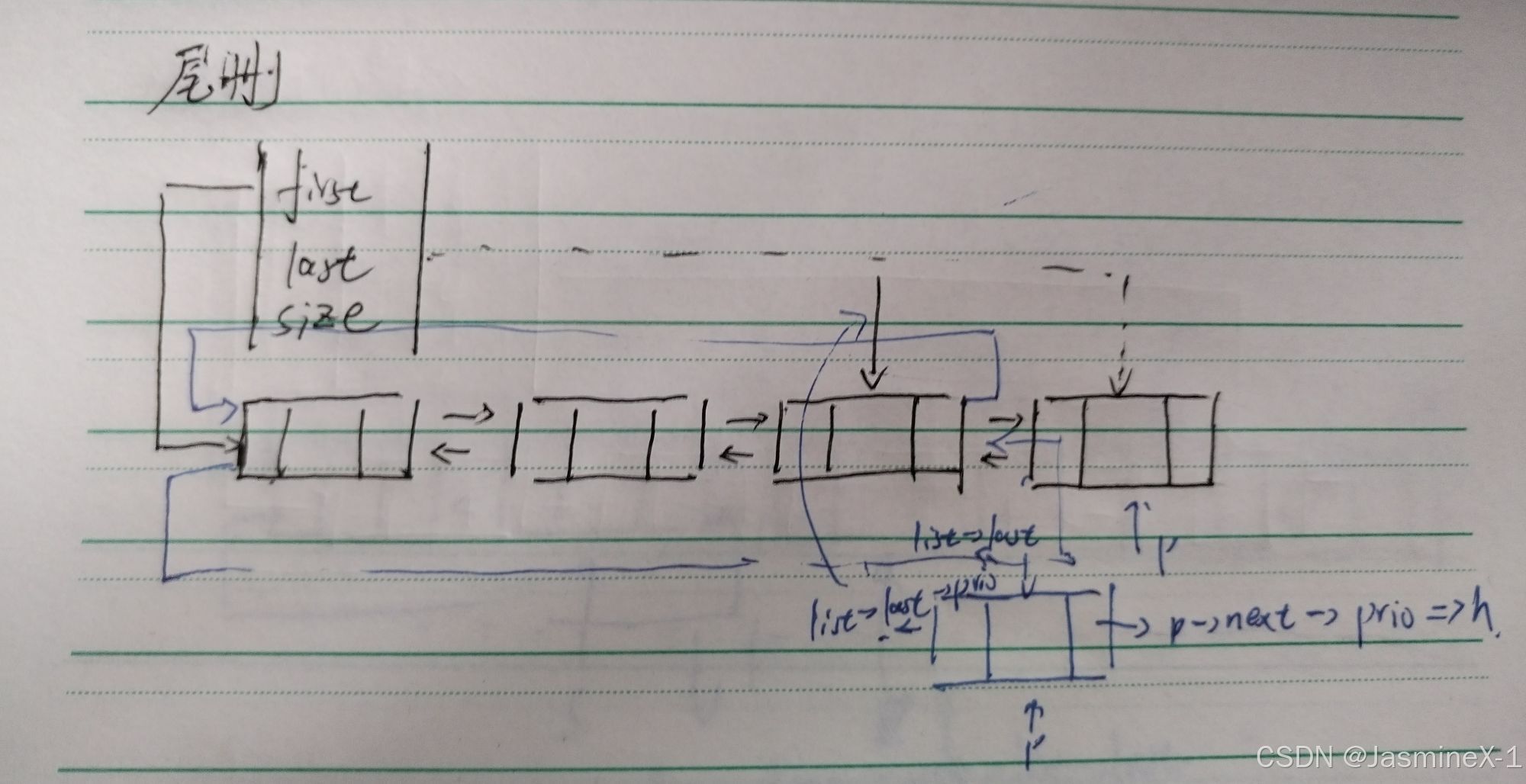
目的:删除尾节点(最后一个有效节点),并释放其内存。
逐步说明
如果 size == 0 则直接返回(空表)。
p = list->last;:保存要删除的尾结点。
list->last = list->last->prio;:把 last 更新为 p 的前驱(可能是 first 当删除最后一个元素)。
p->next->prio = p->prio;:把 p->next(即头结点)的 prio 更新为新的 last。
p->prio->next = p->next;:把 p 的前驱的 next 指向 p->next(即头),断开 p。
free(p); list->size--;:释放内存并更新长度。
复杂度:O(1)。
头删
void pop_front(List* list)
{
if (list->size == 0)
return;
Node* p = list->first->next;
p->next->prio = p->prio;
p->prio->next = p->next;
if (list->size == 1)
list->last = list->first;
list->size--;
}
目的:删除首个有效节点(头结点后面的节点)。
逐步说明
空表返回。
p = first->next:指向要删除的节点。
p->next->prio = p->prio;:把 p 的后继节点的 prio 指向 p 的前驱(头)。
p->prio->next = p->next;:把 p 的前驱(头)的 next 指向 p->next,断开 p。
若删除后链表变空(size==1),把 last = first 恢复空表语义。
list->size--。
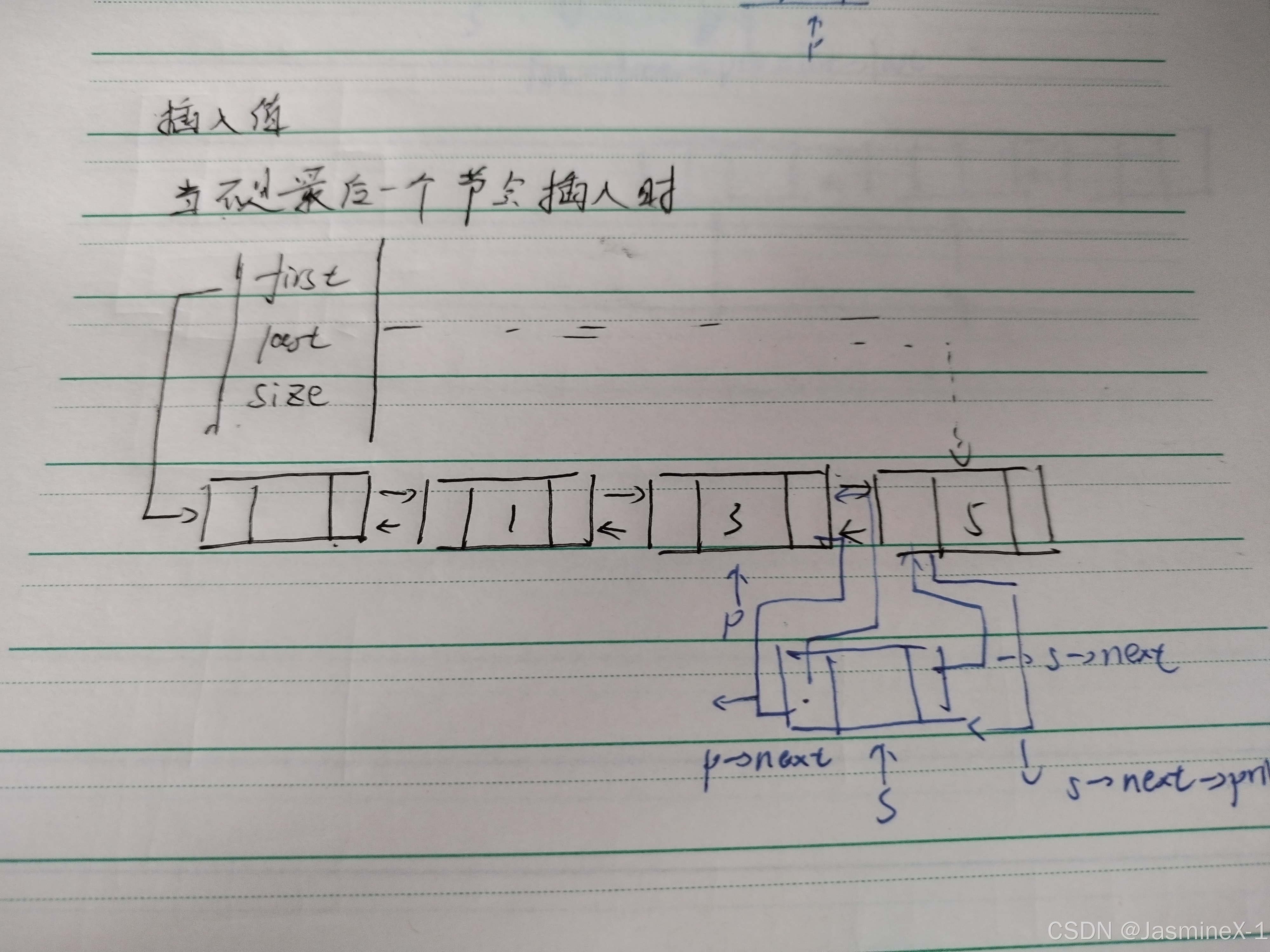
插入值
void insert_val(List* list, ElemType x)
{
Node* p = list->first;
while (p->next != list->last && p->next->data < x)
p = p->next;
if (p->next == list->last && p->next->data < x)
{
push_back(list, x);
}
else
{
Node* s = _buynode(x);
s->next = p->next;
s->next->prio = s;
s->prio = p;
p->next = s;
list->size++;
}
}
查找
Node* find(List* list, ElemType key)
{
Node* p = list->first->next;
while (p != list->first && p->data != key)
p = p->next;
if (p == list->first)
return NULL;
return p;
}
目的:查找第一个值为 key 的节点,找不到则返回 NULL。
逐步说明
从 first->next 开始(第一个有效节点)。
当 p != first 且 p->data != key 时前进。
若回到头结点说明没找到,返回 NULL,否则返回 p。
复杂度:O(n)。
长度
int length(List* list)
{
return list->size;
}
删除值
void delete_val(List* list, ElemType key)
{
if (list->size == 0)
return;
Node* p = find(list, key);
if (p == NULL)
{
printf("找不到此元素.\n");
return;
}
if (p == list->last)
{
pop_back(list);
}
else
{
p->next->prio = p->prio;
p->prio->next = p->next;
free(p);
list->size--;
}
}
目的:删除第一个值等于 key 的节点。
逐步说明
空表直接返回。
p = find(list, key):找不到返回 NULL 并提示。
若删除的是尾节点(p == last),调用 pop_back(pop_back 会 free 并更新 size)。
否则把 p 从链中断开:
p->next->prio = p->prio;
p->prio->next = p->next;
free(p); list->size--;
复杂度:O(n)(包含查找)。
排序
void sort(List* list)
{
if (list->size == 0 || list->size == 1)
return;
Node* s = list->first->next;
Node* q = s->next;
list->last->next = NULL;
list->last = s;
list->last->next = list->first;
list->first->prio = list->last;
while (q != NULL)
{
s = q;
q = q->next;
Node* p = list->first;
while (p->next != list->last && p->next->data < s->data)
p = p->next;
if (p->next == list->last && p->next->data < s->data)
{
s->next = list->last->next;
s->next->prio = s;
s->prio = list->last;
list->last->next = s;
list->last = s;
}
else
{
s->next = p->next;
s->next->prio = s;
s->prio = p;
p->next = s;
}
}
}
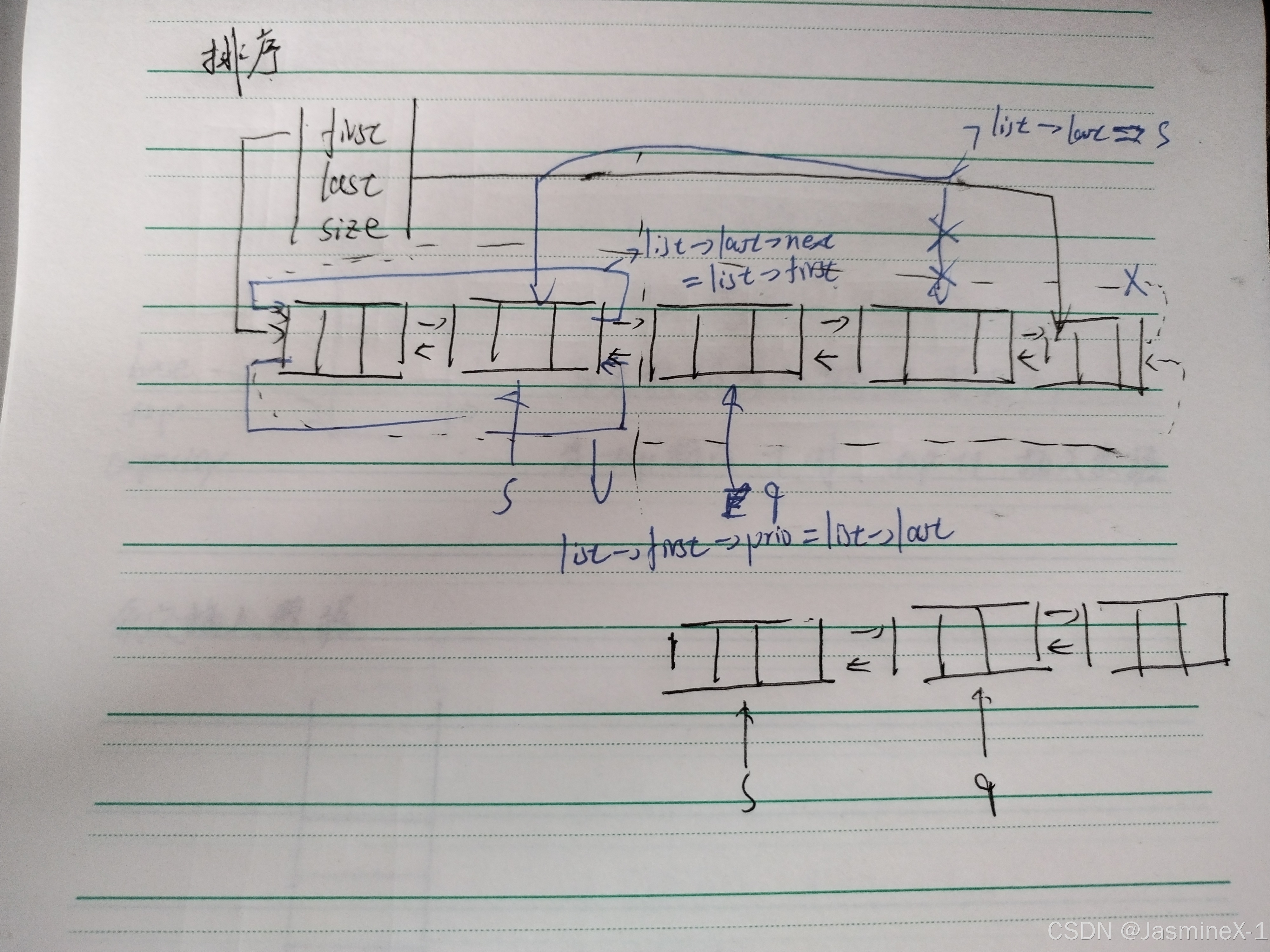
目的:按升序排序 —— 实现思路相当于链表的插入排序(把未排序节点逐个取出并插入到已排序的合适位置)。
逐步说明与意图
特殊情况:size <= 1 不需要排序。
s = first->next(原第一个有效节点),q = s->next(接下来要处理的节点)。
代码尝试处理循环结构和把链表当作线性链来做插入排序 —— 它一开始用 list->last->next = NULL; 把循环断开(暂时把尾的 next 设为 NULL),然后把 list->last = s; list->last->next = list->first; list->first->prio = list->last; 做一些指针调整以保证插入逻辑(这部分代码逻辑比较混乱,容易混淆循环/线性状态)。
主循环:对每个 s(取自 q),在已排序表中找合适的 p 并把 s 插入到 p 与 p->next 之间;或若应在尾部则尾插。
重要问题与建议
目前实现中对循环结构的处理不够清晰:既有 last->next = NULL(把循环断开)又立刻把 last->next = first,这些操作会交替改变结构,很容易出错或产生临时不一致状态。
安全的做法:先明确把循环拆成线性链(例如:first->prio = NULL; last->next = NULL; —— 现在链变成用 first 作为头、用 NULL 作为尾终止),在线性链上做插入排序,最后把链重新修成循环(把 last->next = first; first->prio = last;)。当前代码似乎试图就地做这些变换但可读性和鲁棒性差。
时间复杂度:O(n²)(插入排序)。
逆序
void resver(List* list)
{
if (list->size == 0 || list->size == 1)
return;
Node* p = list->first->next;
Node* q = p->next;
list->last->next = NULL;
list->last = p;
list->last->next = list->first;
list->first->prio = list->last;
while (q != NULL)
{
p = q;
q = q->next;
p->next = list->first->next;
p->next->prio = p;
p->prio = list->first;
list->first->next = p;
}
}
目的:将链表中有效节点的顺序反转(首尾互换)。
逐步说明与意图
空或单元素返回。
p、q 指向待处理的一、二节点。
代码又一次通过 list->last->next = NULL 将循环“断开”为线性链,然后通过头插法把后续节点依次搬到头结点之后,从而实现反转(这是常见的链表反转思路:把每个下一个节点头插法到结果链前端)。
最后应当恢复循环指针(代码里有 list->last = p、list->last->next = list->first、list->first->prio = list->last 的步骤),但实现细节和顺序需非常小心以防越界。
清除
void clear(List* list)
{
if (list->size == 0)
return;
Node* p = list->first->next;
while (p != list->first)
{
p->next->prio = list->first;
list->first->next = p->next;
free(p);
p = list->first->next;
}
list->last = list->first;
list->size = 0;
}
目的:删除并释放所有有效节点(保留头结点),把链表恢复到空表状态。
逐步说明
若 size==0 直接返回。
p = first->next:当前要删除的第一个节点。
循环直到 p == first(表示无更多有效节点):
p->next->prio = list->first;:把下一个节点的前驱设置为头(在删除中起桥接作用)。
list->first->next = p->next;:头结点跳过 p 指向下一个节点。
free(p):释放 p。
p = list->first->next;:更新到新的第一个节点。
list->last = list->first; list->size = 0; 恢复空表不变式。
复杂度:O(n)。
销毁
void destroy(List* list)
{
clear(list);
free(list->first);
list->first = list->last = NULL;
}
目的:销毁整个链表(释放所有节点与头结点),把指针置 NULL。
逐步说明
clear(list) 释放所有有效节点并把 size 置 0。
free(list->first) 释放头结点内存。
list->first = list->last = NULL;:置空以避免悬空指针。
复杂度:O(n)。
转载自CSDN-专业IT技术社区
原文链接:https://blog.csdn.net/2504_92863595/article/details/152212553

