
一、为什么选择 ElasticSearch?
1.1 为什么选择 ElasticSearch?
在电商、资讯等平台的搜索场景中,用户输入的关键词千变万化,传统数据库的字段匹配查询早已无法满足需求,eg:MySQL搜索多个字段模糊匹配,要多次全表扫描。
而 ElasticSearch(简称 ES)作为基于 Lucene 的分布式全文检索服务器,凭借词元匹配 + 倒排索引的核心机制,对外提供Restful 接口来操作索引、搜索,能轻松实现灵活的全文检索。
1.2 ES 核心特性
- 基于 Lucene 封装,隐藏底层复杂性,对外提供 RESTful API 操作索引 / 搜索;
- 分布式架构,支持实时搜索、高可用、高并发;
- 对比 Solr:现有 Solr 满足需求则无需替换,新项目优先选 ES(Github 等大规模场景验证)。
二、ElasticSearch 核心原理
2.1 倒排索引(核心)

正排索引:文档→关键字(如同逐页查字典);
倒排索引: ES 实现高效检索的核心,本质是 “从关键字--->文档的映射”,由三部分构成:
- 文档(Documents) :将搜索的文档以Document方式存储起来(类似字典的正文内容)。
- 分词 (trem) :将要搜索的文档内容分词,所有不重复的词组成分词列表(类似字典的目录)。
- 分词列表(trem---->documents) :每个分词与所属文档的映射关系。特点:①分词不重复;②不搜索的field(字段)不参加分词 eg:img;③停用词 '的','地','得'不参与分词
注意:搜索时从trem分词列表匹配
2.2 核心概念类比
为了快速理解 ES 的结构,我们可以和关系型数据库做类比:
| ElasticSearch | 关系型数据库 | 说明 |
|---|---|---|
| Index(索引库) | Database(数据库) | 存储一组结构相似的文档 |
| Type(类型) | Table(表) | ES6.x 后弱化,7.0 已移除 |
| Document(文档) | Row(行) | 最小数据单元,JSON 格式 |
| Field(字段) | Column(列) | 文档的属性,支持多类型 |
| Shard(分片) | 分库分表 | 分布式存储的核心,提升处理能力 |
| Replica(副本) | 数据备份 | 提升可用性,避免单点故障 |
三、ElasticSearch 环境搭建
3.1 环境要求
- JDK 版本:1.8.0_131 及以上;
- 系统资源:至少 4096 线程池、262144 字节虚拟内存,建议虚拟机内存≥1.5G;
- 安全限制:ES5.0 + 不允许 root 用户启动,需创建普通用户;
- 系统内核:CentOS 内核≥3.5(低于此版本需禁用相关插件)。
3.2 安装 ES(CentOS 为例)
ElasticSearch官网下载:https://www.elastic.co/cn/
步骤 1:创建专用用户
bash
# 创建用户组
groupadd elk
# 创建用户并设置密码
useradd admin
passwd admin
# 将用户加入组
usermod -G elk admin
# 分配目录权限
chown -R admin:elk /usr/upload
chown -R admin:elk /usr/local
# 切换用户
su admin
步骤 2:解压安装
bash
# 下载ES安装包(以6.2.3为例)
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.2.3.tar.gz
# 解压
tar -zxvf elasticsearch-6.2.3.tar.gz -C /usr/local
步骤 3:配置文件修改
ES 的核心配置文件位于config目录下,重点修改 3 个文件:
(1)elasticsearch.yml(核心配置)
yaml
cluster.name: power_shop # 集群名称
node.name: power_shop_node_1 # 节点名称
network.host: 0.0.0.0 # 允许外网访问
http.port: 9200 # HTTP端口
transport.tcp.port: 9300 # 集群通信端口
discovery.zen.ping.unicast.hosts: ["192.168.61.135:9300"] # 集群节点
path.data: /usr/local/elasticsearch-6.2.3/data # 数据存储路径
path.logs: /usr/local/elasticsearch-6.2.3/logs # 日志路径
http.cors.enabled: true # 允许跨域(对接head插件)
http.cors.allow-origin: /.*/ # 允许所有域名跨域
bootstrap.system_call_filter: false # 禁用内核检查(适配CentOS6)
(2)jvm.options(JVM 内存配置)
properties
# 初始堆内存和最大堆内存,建议设为相等且不超过物理内存的1/2
-Xms512m
-Xmx512m
log4j2.properties:按需配置日志级别,默认即可。
(3)解决系统限制问题
①解决内核问题
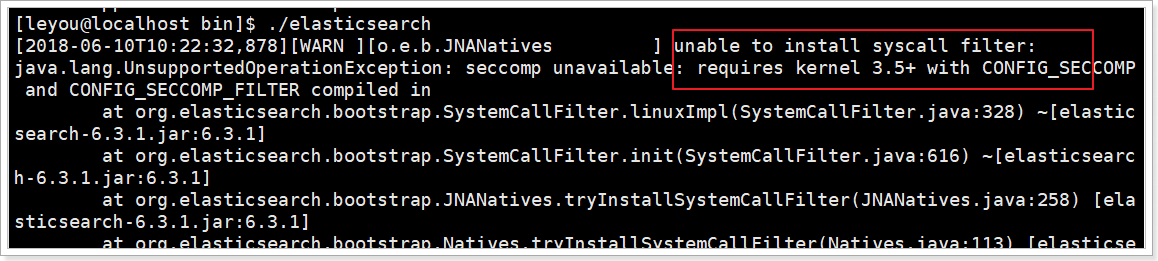
Elasticsearch的插件要求Linux内核版本至少3.5以上版本。禁用这个插件即可。
修改elasticsearch.yml文件,在最下面添加如下配置:
bootstrap.system_call_filter: false②解决文件创建权限问题
[1]: max file descriptors [4096] for elasticsearch process likely too low, increase to at least [65536]Linux 默认来说,一般限制应用最多创建的文件是 4096个。但是 ES 至少需要 65536 的文件创建权限。我们用的是admin用户,而不是root,所以文件权限不足。
使用root用户修改配置文件:
vim /etc/security/limits.conf追加下面的内容:
* soft nofile 65536
* hard nofile 65536③解决线程开启限制问题
[2]: max number of threads [1024] for user [admin] is too low, increase to at least [4096]默认的 Linux 限制 root 用户开启的进程可以开启任意数量的线程,其他用户开启的进程可以开启1024 个线程。必须修改限制数为4096+。因为 ES 至少需要 4096 的线程池预备。
如果虚拟机的内存是 1G,最多只能开启 3000+个线程数。至少为虚拟机分配 1.5G 以上的内存。
使用root用户修改配置:
vim /etc/security/limits.d/90-nproc.conf修改下面的内容:
* soft nproc 1024改为:
* soft nproc 4096④解决虚拟内存问题
[3]: max virtual memory areas vm.max_map_count [65530] likely too low, increase to at least [262144]ES 需要开辟一个 262144字节以上空间的虚拟内存。
使用root用户修改配置文件:
vim /etc/sysctl.conf追加下面内容:
vm.max_map_count=655360 #限制一个进程可以拥有的VMA(虚拟内存区域)的数量然后执行命令,让sysctl.conf配置生效:
sysctl -p步骤 4:启动与测试
bash
./elasticsearch
#或
# 后台启动ES
/usr/local/elasticsearch-6.2.3/bin/elasticsearch -d
# 测试是否启动成功(浏览器访问或curl)
curl http://192.168.204.132:9200返回如下 JSON 表示启动成功:
json
{
"name" : "power_shop_node_1",
"cluster_name" : "power_shop",
"version" : {
"number" : "6.2.3",
"lucene_version" : "7.2.1"
},
"tagline" : "You Know, for Search"
}
3.3 安装 Kibana(ES 可视化工具)
Kibana 是 ES 的官方管理工具,支持语法调试、数据可视化,推荐在 Windows 安装(简单):
- 下载对应版本:https://www.elastic.co/cn/downloads/past-releases/kibana-6-2-3
- 修改
config/kibana.yml:
yaml
-
启动:server.port: 5601 server.host: "0.0.0.0" elasticsearch.url: http://192.168.18.135:9200 # 指向ES地址bin/kibana.bat(Windows),访问http://127.0.0.1:5601即可。
3.4 安装 Head 插件
Head 是 ES 的第三方可视化插件,用来监视ES的状态,并通过head客户端和ES服务进行交互,比如创建映射、创建索引等:
bash
# 下载源码
git clone https://github.com/mobz/elasticsearch-head.git
# 安装依赖并启动
cd elasticsearch-head
npm install
npm run start
访问http://127.0.0.1:9100,输入 ES 地址即可连接。
四、ES 快速入门(核心操作)
4.1 索引库(Index)管理
索引库包含若干相似结构的 Document 数据,相当于数据库的database。
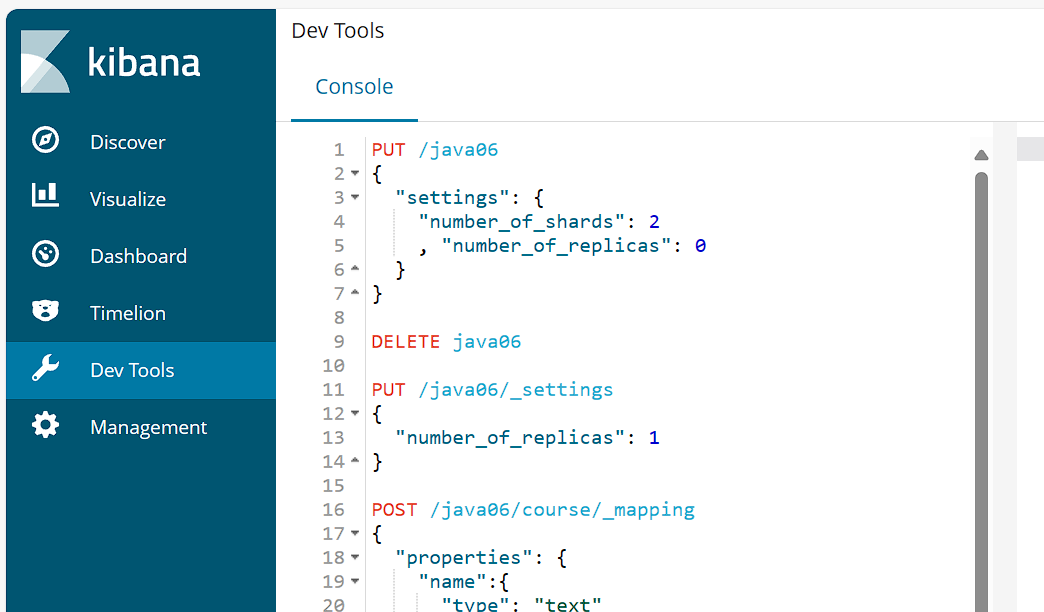
(1)创建索引
json
# PUT /索引名
PUT /java06
{
"settings": {
"number_of_shards": 2, # 主分片数(一旦创建不可修改)
"number_of_replicas": 1 # 副本数(可动态修改)
}
}
number_of_shards - 表示一个索引库将拆分成多片分别存储不同的结点,提高了ES的处理能力
number_of_replicas - 是为每个 primary shard分配的replica shard数量,提高了ES的可用性,
注意:number_of_replicas 如果只有一台机器,设置为0
运行后:
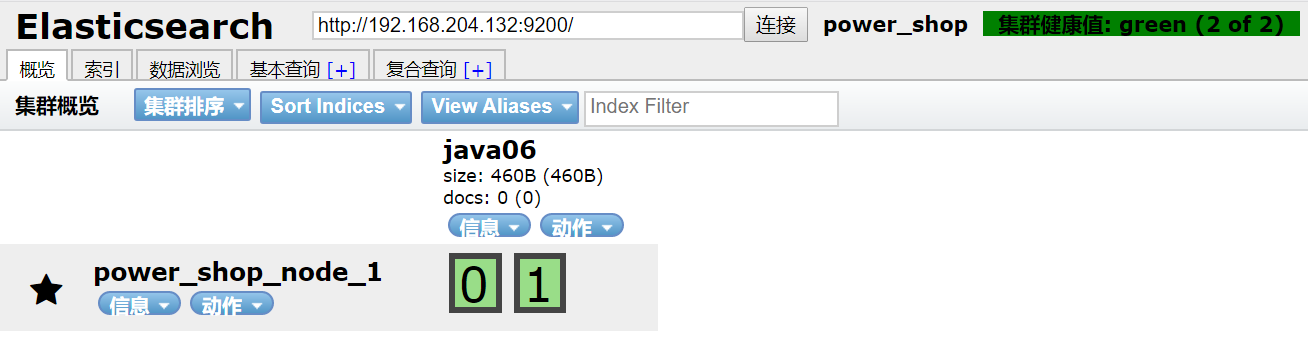
(2)修改索引(仅副本数)
json
PUT /java06/_settings
{
"number_of_replicas" : 0
}
注意:索引一旦创建,primary shard 数量不可变化,可以改变replica 数量。
(3)删除索引
json
DELETE /java06
4.2 type管理
映射用于定义文档的字段类型、分词器等规则,相当于数据库的表结构:
| elasticsearch | 关系数据库 |
|---|---|
| index(索引库) | database(数据库) |
| type(类型) | table(表) |
| document(文档) | row(记录) |
| field(域) | column(字段) |
注意:6.0之前的版本有type(类型)概念,type相当于关系数据库的表,ES6.x 版本之后,type概念被弱化ES官方将在ES7.0版本中彻底删除type。
json
(1) 创建type
POST /java06/course/_mapping
{
"properties": {
"name": {
"type": "text"
},
"description": {
"type": "text"
},
"studymodel": {
"type": "keyword"
}
}
}效果:
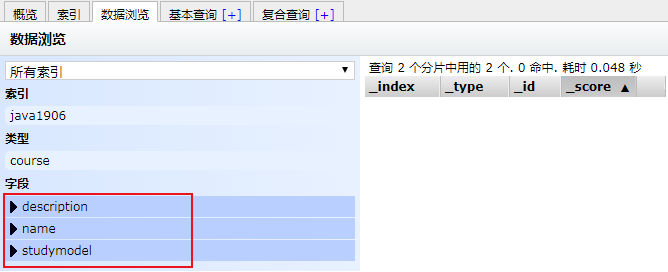
(2) 查询type
查询所有索引的映射:
GET /java06/course/_mapping查询id为1的映射:
GET /java06/course/1(3) 更新type
映射创建成功可以添加新字段,已有字段不允许更新。
(4) 删除type
通过删除索引来删除映射。
4.3 文档(Document)管理
(1)新增文档
json
# 手动指定ID
PUT /java06/course/1
{
"name":"Python从入门到精通",
"description":"人生苦短,我用Python",
"studymodel":"201002",
"price":29.9,
"timestamp":"2024-01-01",
"pic":"python.jpg"
}
# 自动生成ID
POST /java06/course
{
"name":".NET从入门到精通",
"description":".NET程序员的进阶之路",
"studymodel":"201003",
"price":39.9
}
(2)查询文档
json
# 根据ID查询
GET /java06/course/1
# 全文检索(搜索name包含“入门”的文档)
GET /java06/course/_search?q=name:入门
# 查询所有文档
GET /java06/course/_search
通过head查询数据:
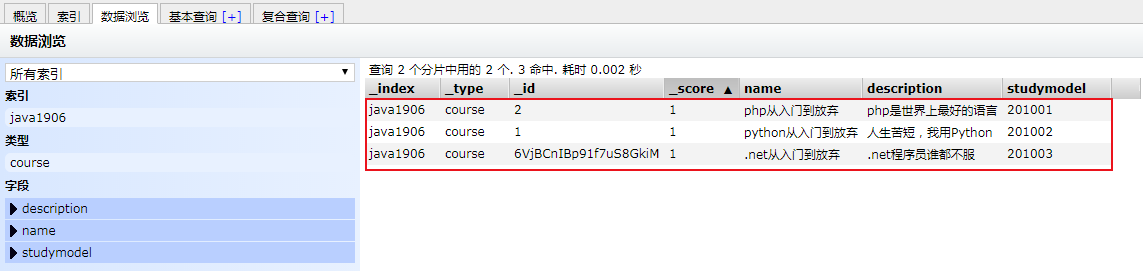
(3)删除文档
json
DELETE /java06/course/1
4.4 IK 分词器(中文分词必备)
ES 默认的分词器对中文支持极差(单字分词),需安装 IK 分词器解决:
- 下载对应版本:https://github.com/medcl/elasticsearch-analysis-ik
- 解压到 ES 的
plugins/ik目录,重启 ES;
- 两种分词模式:
ik_max_word:细粒度分词,往es写入时使用(如 “中华人民共和国” 拆分为多个关键词);ik_smart:粗粒度分词,搜索时使用(如 “中华人民共和国” 仅拆分为自身)。
测试分词效果
json
POST /_analyze
{
"text":"中华人民共和国人民大会堂",
"analyzer":"ik_smart"
}
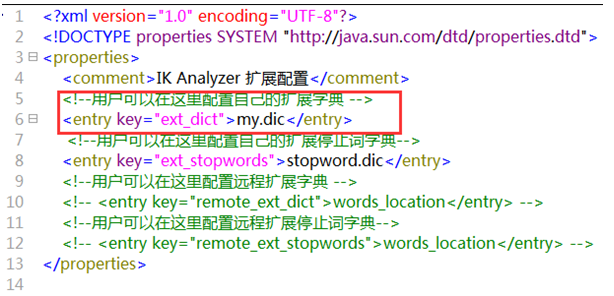
自定义词库
IKAnalyzer.cfg.xml:配置扩展词典和停用词典
iK分词器自带的main.dic的文件为扩展词典,stopword.dic为停用词典。注意文件格式为utf-8
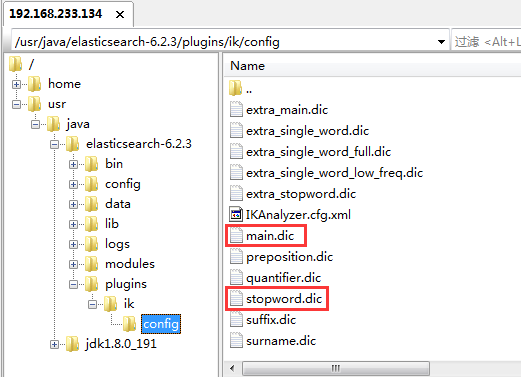
若需支持专有词汇(如公司名、行业术语),可在 IK 的config目录新建my.dic,添加自定义词汇后,修改IKAnalyzer.cfg.xml引入该词库即可。
4.5 ES 读写核心逻辑
(1)数据路由 documnet routing
当客户端创建document时,es需要确定这个document放在该index哪个shard上,这个过程就是document routing。
路由过程:
路由算法:shard = hash(id) %number_of_primary_shards
id:document的_id,可能是手动指定,也可能是自动生成,决定一个document在哪个shard上
number_of_primary_shards:主分片數量。
(2) primary shard数量不可变原因
这也是主分片数不可改的原因(改后路由算法失效,无法查询数据)。
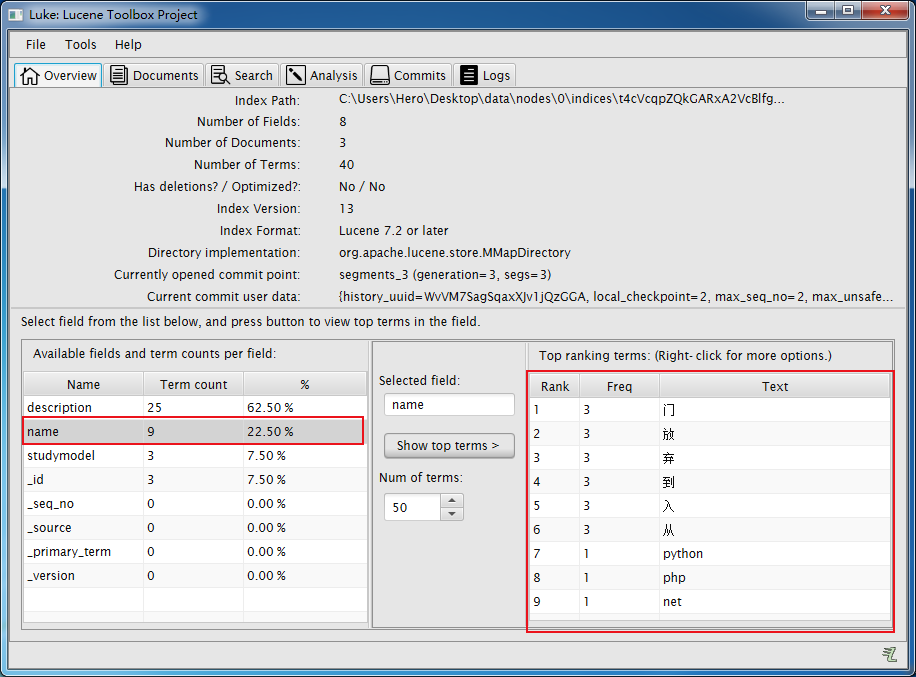
4.6 luke查看ES的逻辑结构
-
拷贝elasticsearch-6.2.3/data到windows
-
双击luke.bat,启动luke(注意:jdk版本需要1.8.0...)
-
使用luke打开data\nodes\0\indices路径
效果:
五、Field 详细配置
Field 的数据类型
| 类型 | 举例 |
|---|---|
| 文本 | test、keyword(特殊的varchar) |
| 数字 | integer、long、float、double |
5.1 核心属性
| 属性 | 说明 |
|---|---|
| type | 字段的数据类型(text/keyword/date/numeric 等) |
| analyzer | 索引写入时分词器(如 analyzer=ik_max_word) |
| search_analyzer | 搜索时分词器(如 search_analyzer=ik_smart) |
| index | 是否索引、是否向分词列表写(false 则不可搜索,true是默认值) |
| _source | 控制原始字段是否存储 / 过滤字段,往文档写,默认是,如:excludes |
5.2 Field 属性的设置标准
| 属性 | 设置标准 |
|---|---|
| type | 分词是否有意义 |
| index | 是否搜索 |
| _source | 是否展示 |
例如:
POST /java06/course/_mapping
{
"excludes":["description"],
"properties": {
"name": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
},
"description": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart",
},
"studymodel": {
"type": "keyword"
},
"pic":{
"type": "text",
"index": false
},
"price":{
"type": "float"
}
}
}Field设置详解:
name 商品名称 搜索时有意义,需拆成分词字段类型 type:text;分词器设置;需要搜索和展示,
index:true 和 _source:true 默认值都是true,可以省略;
description 商品描述在搜索时不展示,设置 _scource:excludes;商品描述也要分词;
studymodel 商品的时间,搜索时拆除分词就没有意义type:keyword;不进行分词,整个写到索引目录,比如:邮政编码、手机号码、身份证等,不需要analyzer 和 search_analyzer;
pic 商品封面图片,搜索时分词没意义,应该是type:keyword,但是因为图片不会按pic.jpg搜索, index:false 即不往索引目录里写 与type:keyword 整个写到索引目录 冲突 ,所以 type:keyword ;
思考:
添加一条数据
PUT /java06/course/3
{
"name": "spring开发基础",
"description": "spring 在java领域非常流行,java程序员都在用。",
"studymodel": "20年10月01日",
"pic":"250.jpg",
"price":38.6
}- 是否能用““开发””搜索name字段
- 搜索到的结果是否能看见description
- 是否能用"20年"搜索studymodel字段
- 是否能用“250.jpg”搜索pic字段
- 是否能用“38.6”搜索price字段
答案:
|
|
|
|
|
|
|
|
|
|
|
√ × × × √扩充:能否用 “领域”搜索description字段------------------------------------------------------------------yes
5.3 常用字段类型
(1)Text(文本字段)
支持分词,用于全文检索(如商品名称、描述):
json
"name": {
"type": "text",
"analyzer":"ik_max_word",
"search_analyzer":"ik_smart"
}(2)Keyword(关键字字段)
不分词,用于精确查询 / 排序 / 聚合(如手机号、邮政编码):
json
"studymodel":{
"type":"keyword"
}
(3)Date(日期字段)
支持自定义格式,用于时间排序:
json
"timestamp": {
"type": "date",
"format": "yyyy-MM-dd"
}
(4)Numeric(数值字段)
支持排序、区间搜索(如价格、数量):
json
"price": {
"type": "float"
}
六、Spring Boot 整合 ElasticSearch
6.1 客户端选择
推荐使用 RestHighLevelClient(官方主推,6.0 + 支持),替代即将废弃的 TransportClient(8.0后会删除)。
注意:没有用注解版本
6.2 工程搭建
(1)POM 依赖
xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.3.2.RELEASE</version>
</parent>
<groupId>com.powershop</groupId>
<artifactId>springboot_elasticsearch</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<elasticsearch.version>6.2.3</elasticsearch.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>${elasticsearch.version}</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>
</dependencies>
</project>
(2)配置文件(application.yml)
yaml
spring:
elasticsearch:
rest:
uris:
- http://192.168.19.135:9200(3)启动类
java
package com.powershop;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class ElasticsearchApp {
public static void main(String[] args) {
SpringApplication.run(ElasticsearchApp.class, args);
}
}
6.3 索引管理(代码示例)
创建和删除索引库
API:
PUT /java06
{
"settings":{
"number_of_shards" : 2,
"number_of_replicas" : 0
}
}创建映射:
POST /java06/course/_mapping
{
"_source": {
"excludes":["description"]
},
"properties": {
"name": {
"type": "text",
"analyzer":"ik_max_word",
"search_analyzer":"ik_smart"
},
"description": {
"type": "text",
"analyzer":"ik_max_word",
"search_analyzer":"ik_smart"
},
"studymodel": {
"type": "keyword"
},
"price": {
"type": "float"
},
"pic":{
"type":"text",
"index":false
}
}
}删除索引库 API:
DELETE /java06java
@RunWith(SpringJUnit4ClassRunner.class)
@SpringBootTest(classes = SpringBootESApp.class)
public class testDeleteIndex {
@Autowired
private RestHighLevelClient restHighLevelClient;
//删除索引库
@Test
public void deleteIndex() throws IOException {
//indicesClient:封装了操作索引库的API
IndicesClient indicesClient = restHighLevelClient.indices();
//删除index的request
DeleteIndexRequest indexRequest = new DeleteIndexRequest("java06");
//发送delete请求
DeleteIndexResponse indexResponse = indicesClient.delete(indexRequest);
System.out.println(indexResponse.isAcknowledged());
}
//添加索引库
@Test
public void createIndex() throws IOException {
//创建索引操作客户端
IndicesClient indicesClient = restHighLevelClient.indices();
//创建“创建索引请求”对象,并设置索引名称
CreateIndexRequest createIndexRequest = new CreateIndexRequest("java06");
//设置索引参数
createIndexRequest.source("{\n" +
" \"settings\": {\n" +
" \"number_of_shards\": 2\n" +
" , \"number_of_replicas\": 0\n" +
" }\n" +
"}", XContentType.JSON);
createIndexRequest.mapping("course","{\n" +
" \"_source\": {\n" +
" \"excludes\": [\"description\"]\n" +
" },\n" +
" \"properties\": {\n" +
" \"name\": {\n" +
" \"type\": \"text\",\n" +
" \"analyzer\": \"ik_max_word\",\n" +
" \"search_analyzer\": \"ik_smart\"\n" +
" },\n" +
" \"description\": {\n" +
" \"type\": \"text\",\n" +
" \"analyzer\": \"ik_max_word\",\n" +
" \"search_analyzer\": \"ik_smart\"\n" +
" },\n" +
" \"studymodel\": {\n" +
" \"type\": \"keyword\"\n" +
" },\n" +
" \"pic\": {\n" +
" \"type\": \"text\",\n" +
" \"index\": false\n" +
" },\n" +
" \"price\": {\n" +
" \"type\": \"float\"\n" +
" }\n" +
" }\n" +
"}",XContentType.JSON);
//创建响应对象
CreateIndexResponse createIndexResponse = indicesClient.create(createIndexRequest);
//得到响应结果
boolean acknowledged = createIndexResponse.isAcknowledged();
System.out.println(acknowledged);
}
}
控制台为True则操作成功
6.4 文档管理
API:
POST /java06/course/1
{
"name":"spring cloud实战",
"description":"本课程主要从四个章节进行讲解: 1.微服务架构入门 2.spring cloud 基础入门 3.实战Spring Boot 4.注册中心eureka。",
"studymodel":"201001",
"price":5.6
}PUT /java06/course/1
{
"price":66.6
}DELETE /java06/course/1 //添加文档
@Test
public void addDoc() throws IOException {
IndexRequest indexRequest = new IndexRequest("java06","course","1");
indexRequest.source("{\n" +
" \"name\":\"spring cloud实战\",\n" +
" \"description\":\"本课程主要从四个章节进行讲解: 1.微服务架构入门 2.spring cloud 基础入门 3.实战Spring Boot 4.注册中心eureka。\",\n" +
" \"studymodel\":\"201001\",\n" +
" \"price\":5.6\n" +
"}",XContentType.JSON);
restHighLevelClient.index(indexRequest);
}
//修改文档
@Test
public void updateDoc() throws IOException {
UpdateRequest updateRequest = new UpdateRequest("java06","course","1");
updateRequest.doc("{\n" +
" \"price\":66.6\n" +
"}",XContentType.JSON);
restHighLevelClient.update(updateRequest);
}
//删除文档
@Test
public void deleteDoc() throws IOException {
DeleteRequest deleteRequest = new DeleteRequest("java06", "course", "1");
restHighLevelClient.delete(deleteRequest);
}6.5 文档搜索
向索引库中插入以下数据:
PUT /java06/course/1
{
"name": "Bootstrap开发",
"description": "Bootstrap是由Twitter推出的一个前台页面开发css框架,是一个非常流行的开发框架,此框架集成了多种页面效果。此开发框架包含了大量的CSS、JS程序代码,可以帮助开发者(尤其是不擅长css页面开发的程序人员)轻松的实现一个css,不受浏览器限制的精美界面css效果。",
"studymodel": "201002",
"price":38.6,
"pic":"group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg"
}
PUT /java06/course/2
{
"name": "java编程基础",
"description": "java语言是世界第一编程语言,在软件开发领域使用人数最多。",
"studymodel": "201001",
"price":68.6,
"pic":"group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg"
}
PUT /java06/course/3
{
"name": "spring开发基础",
"description": "spring 在java领域非常流行,java程序员都在用。",
"studymodel": "201001",
"price":88.6,
"pic":"group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg"
}6.5.1 简单搜索
API:
GET /java06/course/1import com.hg.SpringBootESApp;
import org.elasticsearch.action.get.GetRequest;
import org.elasticsearch.action.get.GetResponse;
import org.elasticsearch.client.RestHighLevelClient;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
import java.io.IOException;
@RunWith(SpringJUnit4ClassRunner.class)
@SpringBootTest(classes = SpringBootESApp.class)
public class testReadIndex {
@Autowired
private RestHighLevelClient restHighLevelClient;
//查询文档
@Test
public void getDoc() throws IOException {
GetRequest getRequest = new GetRequest("java06","course","1");
String source = restHighLevelClient.get(getRequest).getSourceAsString();
System.out.println(source);
}
}
查询结果:

6.5.2 DSL搜索
DSL(Domain Specific Language)是ES提出的基于json的搜索方式,在搜索时传入特定的json格式的数据来完成不同的搜索需求,DSL比URI搜索方式功能强大,在项目中建议使用DSL方式来完成搜索。
(1) match_all查询
API:
GET /java06/course/_search
{
"query" : {
"match_all" : {}
}
}API结果

//match_all查询
@Test
public void match_all() throws IOException {
SearchRequest searchRequest = new SearchRequest();
//url
searchRequest.indices("java06");
searchRequest.types("course");
//参数
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.matchAllQuery());
//设置请求参数
searchRequest.source(searchSourceBuilder);
//调用search方法
SearchResponse response = restHighLevelClient.search(searchRequest);
SearchHits responseHits = response.getHits();
long totalHits = responseHits.getTotalHits();
System.out.println("共查询" + totalHits +"条");
SearchHit[] hits = responseHits.getHits();
for (SearchHit hit : hits) {
System.out.println(hit.getSourceAsString());
}运行结果:

(2) 分页查询
API
GET /java06/course/_search
{
"query" : { "match_all" : {} },
"from" : 0, # 从第几条数据开始查询,从0开始计数
"size" : 2, # 查询多少数据
"sort" : [
{ "price" : "asc" }
]
}注意:运行时删掉注释!
//分页查询
@Test
public void PageSelect() throws IOException {
SearchRequest searchRequest = new SearchRequest();
//url
searchRequest.indices("java06");
searchRequest.types("course");
//参数
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.matchAllQuery());
searchSourceBuilder.from(0);
searchSourceBuilder.size(2);
searchSourceBuilder.sort("price", SortOrder.ASC);
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = restHighLevelClient.search(searchRequest);
//遍历
SearchHits hits = searchResponse.getHits();
long totalHits = hits.getTotalHits();
System.out.println("共" +totalHits+ "条数据");
SearchHit[] hitsHits = hits.getHits();
for (SearchHit hitsHit : hitsHits) {
System.out.println(hitsHit.getSourceAsString());
}运行结果:

这两个查询代码中有很多冗余
简化后:
match_all查询 保留原始方法,以便学习参考
package com.hg.test;
import com.hg.SpringBootESApp;
import org.elasticsearch.action.get.GetRequest;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.sort.SortOrder;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
import java.io.IOException;
@RunWith(SpringJUnit4ClassRunner.class)
@SpringBootTest(classes = SpringBootESApp.class)
public class testReadIndex {
@Autowired
private RestHighLevelClient restHighLevelClient;
private SearchRequest searchRequest;
private SearchSourceBuilder searchSourceBuilder;
@Before
public void init(){
searchRequest = new SearchRequest();
//url
searchRequest.indices("java06");
searchRequest.types("course");
//参数
searchSourceBuilder = new SearchSourceBuilder();
}
//查询文档
@Test
public void getDoc() throws IOException {
GetRequest getRequest = new GetRequest("java06","course","1");
String source = restHighLevelClient.get(getRequest).getSourceAsString();
System.out.println(source);
}
//match_all查询
@Test
public void match_all() throws IOException {
SearchRequest searchRequest = new SearchRequest();
//url
searchRequest.indices("java06");
searchRequest.types("course");
//参数
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.matchAllQuery());
//设置请求参数
searchRequest.source(searchSourceBuilder);
//调用search方法
SearchResponse response = restHighLevelClient.search(searchRequest);
SearchHits responseHits = response.getHits();
long totalHits = responseHits.getTotalHits();
System.out.println("共查询" + totalHits +"条");
SearchHit[] hits = responseHits.getHits();
for (SearchHit hit : hits) {
System.out.println(hit.getSourceAsString());
}
}
//分页查询
@Test
public void PageSelect() {
searchSourceBuilder.query(QueryBuilders.matchAllQuery());
searchSourceBuilder.from(0);
searchSourceBuilder.size(2);
searchSourceBuilder.sort("price", SortOrder.ASC);
}
@After
public void show() throws IOException {
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = restHighLevelClient.search(searchRequest);
//遍历
SearchHits hits = searchResponse.getHits();
long totalHits = hits.getTotalHits();
System.out.println("共" +totalHits+ "条数据");
SearchHit[] hitsHits = hits.getHits();
for (SearchHit hitsHit : hitsHits) {
System.out.println(hitsHit.getSourceAsString());
}
}
}
(3)multi_match查询
matchQuery是在一个field中去匹配,multiQuery是拿关键字去多个Field中匹配。
API
GET /java06/course/_search
{
"query": {
"multi_match": {
"query": "开发",
"fields": ["name","description"]
}
}
} //multi_match查询
@Test
public void multi_match(){
searchSourceBuilder.query(QueryBuilders.multiMatchQuery("开发","name","description"));
}查询结果:

(4) bool查询
布尔查询,实现将多个查询组合起来。
参数:
- must:表示必须,多个查询条件必须都满足。(通常使用must)
- should:表示或者,多个查询条件只要有一个满足即可。
- must_not:表示非。
例如:查询name包括“开发”并且价格区间是1-100的文档
API
GET /java06/course/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "开发"
}
},
{
"range": {
"price": {
"gte": 50,
"lte": 100
}
}
}
]
}
}
} //bool查询
@Test
public void boolSel(){
searchSourceBuilder.query(QueryBuilders.boolQuery()
.must(QueryBuilders.matchQuery("name","开发"))
.must(QueryBuilders.rangeQuery("price").gte(50).lte(100))
);
}查询结果:

(5) filter 查询
API
GET /java06/course/_search
{
"query": {
"bool" : {
"must":[
{
"match": {
"name": "开发"
}
},
{
"range": {# 范围, 字段的数据必须满足某范围才有结果。
"price": {
"gte": 10, # 比较符号 lt gt lte gte
"lte": 100
}
}
}
]
}
}
}注意:去掉注释
//filter查询
@Test
public void filterSel(){
searchSourceBuilder.query(QueryBuilders.boolQuery()
.must(QueryBuilders.matchQuery("name","开发"))
.filter(QueryBuilders.rangeQuery("price").gte(10).lte(100))
);
}查询结果:

(6) highlight查询
API
GET /java06/course/_search
{
"query": {
"multi_match": {
"query": "spring开发",
"fields":["name","description"]
}
},
"highlight": {
"pre_tags": ["<font color='red'>"],
"post_tags": ["</font>"],
"fields": {"name": {}}
}
} //highlight查询
@Test
public void highlightSel(){
SearchSourceBuilder sourceBuilder = searchSourceBuilder.query(QueryBuilders.matchQuery("name", "spring开发"));
//设置高亮
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.preTags("<font color='red'>");
highlightBuilder.postTags("</font>");
highlightBuilder.fields().add(new HighlightBuilder.Field("name"));
sourceBuilder.highlighter(highlightBuilder);
}查询结果:

七、集群管理
ES通常以集群方式工作,这样做不仅能够提高 ES的搜索能力还可以处理大数据搜索的能力,同时也增加了系统的容错能力及高可用。
下图是ES集群结构的示意图:
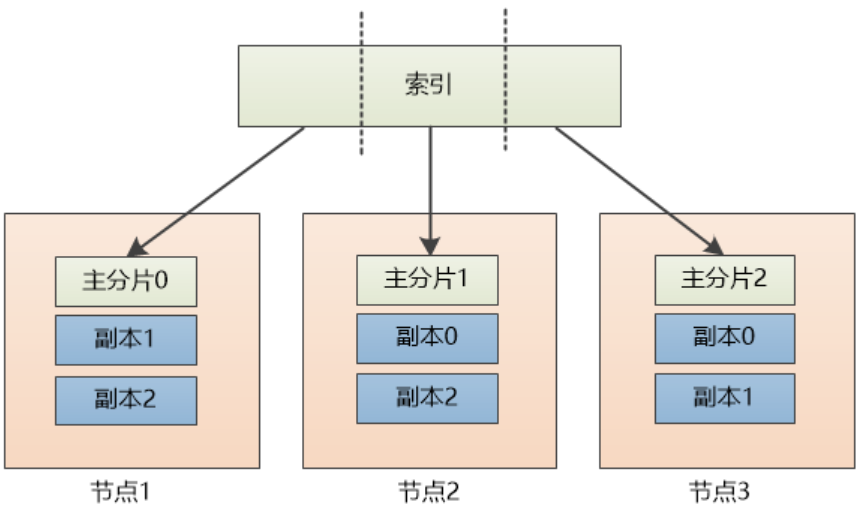
每个主分片有两个副本, 如果某个节点挂了也不怕,比如节点1挂了,我们可以查询位于节点3和节点3上的副本0
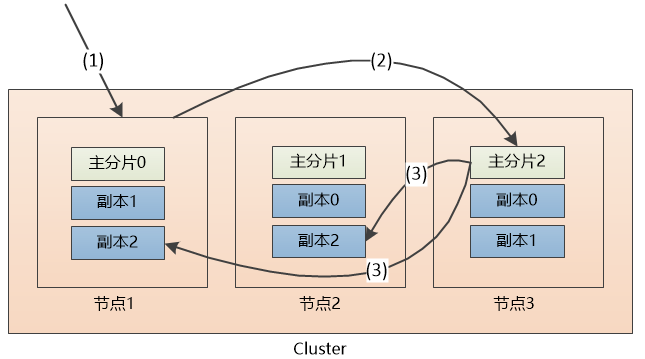
添加文档过程:
(1)假设用户把请求发给了节点1
(2)系统通过余数算法得知这个’文档’应该属于主分片2,于是请求被转发到保存该主分片的节点3
(3)系统把文档保存在节点3的主分片2中,然后将请求转发至其他两个保存副本的节点。
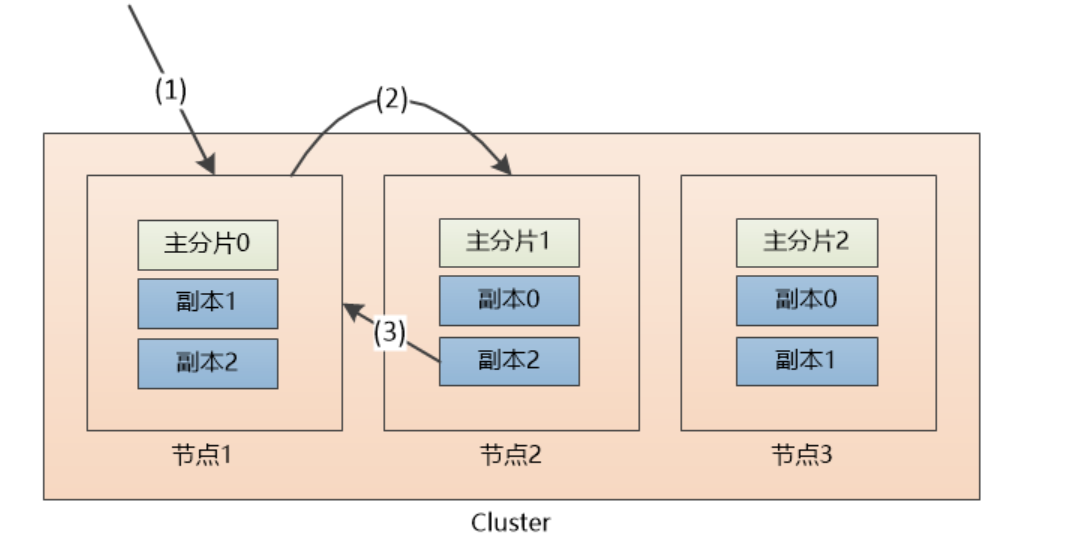
查询文档过程:
(1) 请求被发给了节点1
(2)节点1计算出该数据属于主分片2,这时候,有三个选择,分别是位于节点1的副本2, 节点2的副本2,节点3
的主分片2, 假设节点1负载均衡,采用轮询的方式,选中了节点2,把请求转发。
(3) 节点2把数据返回给节点1, 节点1 最后返回给客户端。
7.1 集群搭建
1、拷贝节点elasticsearch-1
2、修改elasticsearch-2的IP
vim /etc/sysconfig/network-scripts/ifcfg-ens33IPADDR=192.168.19.136
systemctl restart network3、删除节点2的data目录
4、修改elasticsearch.yml内容如下:
node.name: power_shop_node_2
discovery.zen.ping.unicast.hosts: ["192.168.19.135:9300", "192.168.19.136:9300"]5、测试
启动两个节点 ,测试集群健康状况和分片
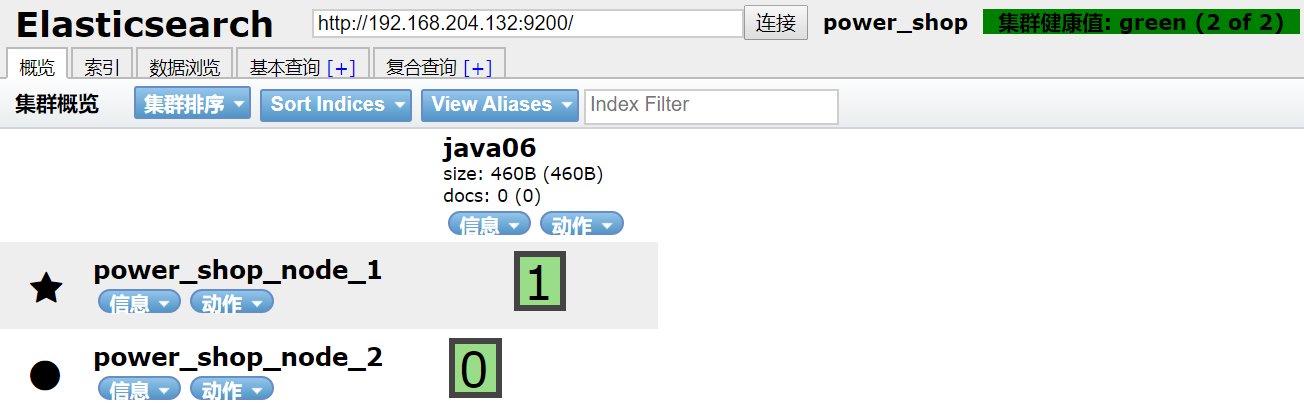
健康值:绿色 正常
关闭节点2,测试集群状态
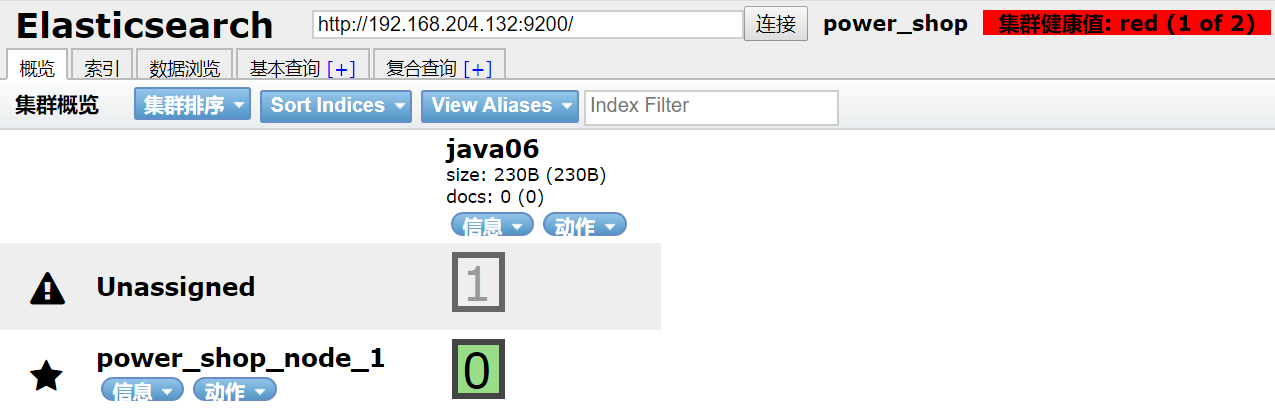
健康值:红色 挂了
创建备份分配,关闭节点2,再测试集群状态
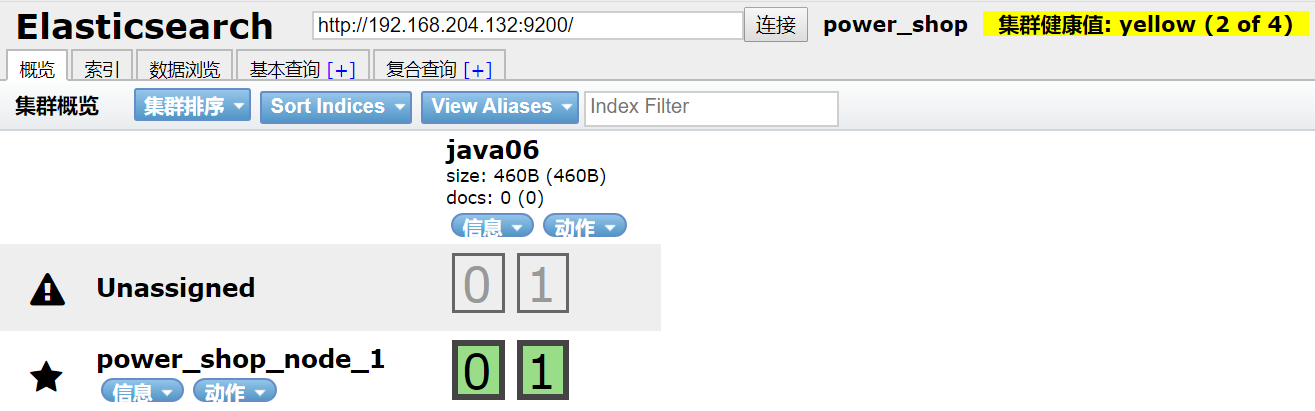
健康值:黄色 备份分片不可用
转载自CSDN-专业IT技术社区
原文链接:https://blog.csdn.net/2403_89058622/article/details/160993480

