
前面我们讲了Gdify的产品边界和技术栈
这次我们来回答一个更具体的问题:代码怎么组织,外部调用怎么处理?
很多工程师拿到需求,直接开始写代码,写到一半,发现模块之间耦合的死死的线程池被LLM调用占满了管理页面打不开,不同模块的代码风格不一样。这些问题不是写代码的问题,而是动手之前就没有清楚应用架构
这一节课我们来聚焦一下代码层面模块怎么分,Spring代码怎么组织,外部调用怎么处理
应用架构:模块化单体
首先我们要解决第一个问题,一个SpringBoot应用内部怎么组织?
前面我们已经确定了50人单机部署,但单机不等于所有代码都堆在一个包中。我让AI编辑器给方案
Gdify是一个spring boot单体应用功能包括模型提供商管理,agent配置,对话引擎,RAG知识库,简单版工作流,MCP工具接入,一个人开发一期50人使用,但后续可能扩展到几千人代码内该怎么组织给我方案对比,并给我生成简单总结

他推荐我业务模块单体化,按业务拆分,再做模块内部分层。
但是我认为2方案,放在一个包下有点太重了。我更偏向于3方案maven多模块单体。
所以最终的模块化分为:
code ├─ backend │ ├─ pom.xml │ ├─ gdify-app # 启动模块 │ ├─ gdify-common # 公共模块 │ ├─ gdify-module-provider # 模型提供商管理 │ ├─ gdify-module-agent # agent管理与配置 │ ├─ gdify-module-conversation # 对话引擎 │ ├─ gdify-module-rag # 知识库 │ ├─ gdify-module-workflow # 工作流编排与执行 │ ├─ gdify-module-mcp # McP工具管理与调用 │ └─ gdify-support-infra # 跨业务模块共享的基础设施实现 ├─ gdify-web-admin └─ gdify-web-chat
对于不太理解的模块,你可以询问他

现在我们想要知道模块之间的依赖关系需要想清楚
基于Gdify的功能,帮我梳理这些模块之间的依赖关系,谁依赖谁有没有循环依赖的风险
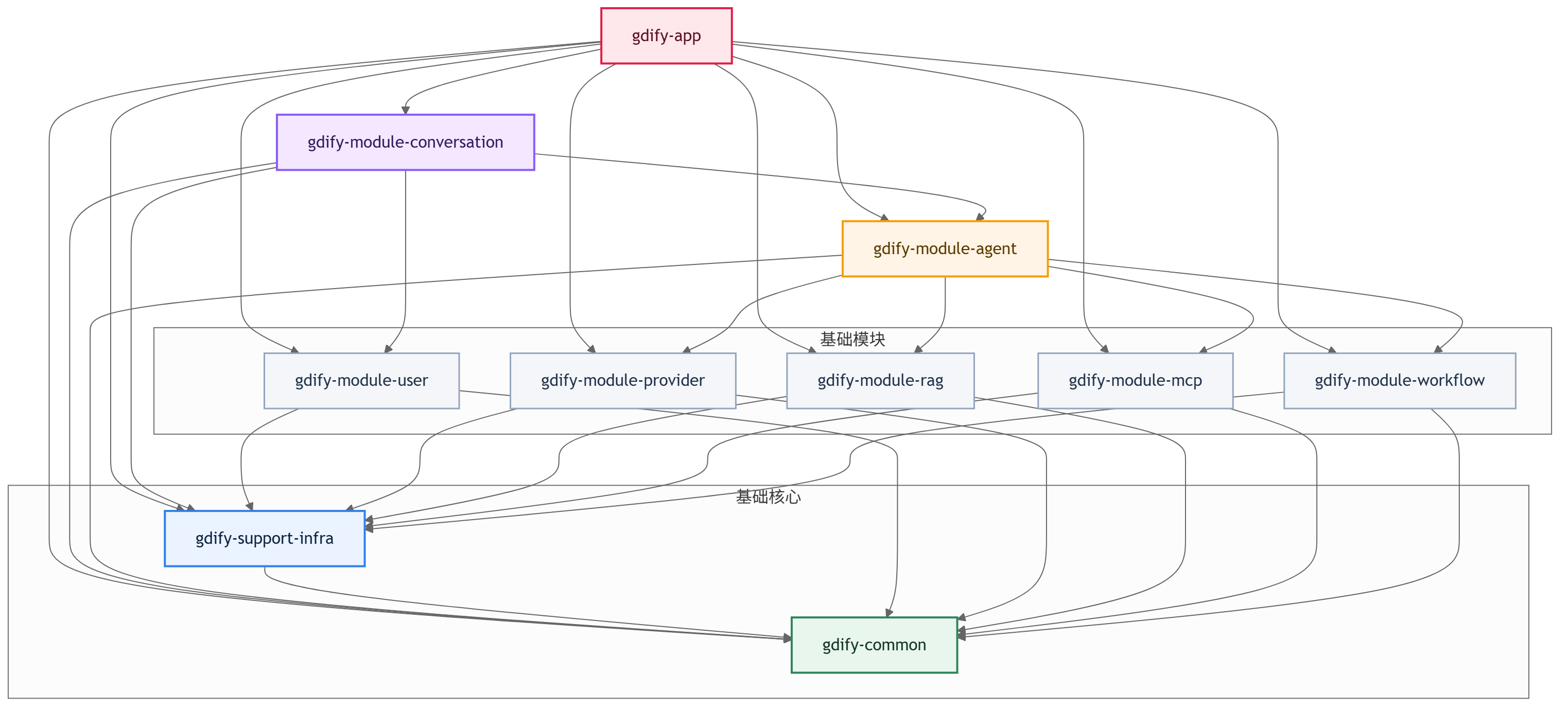
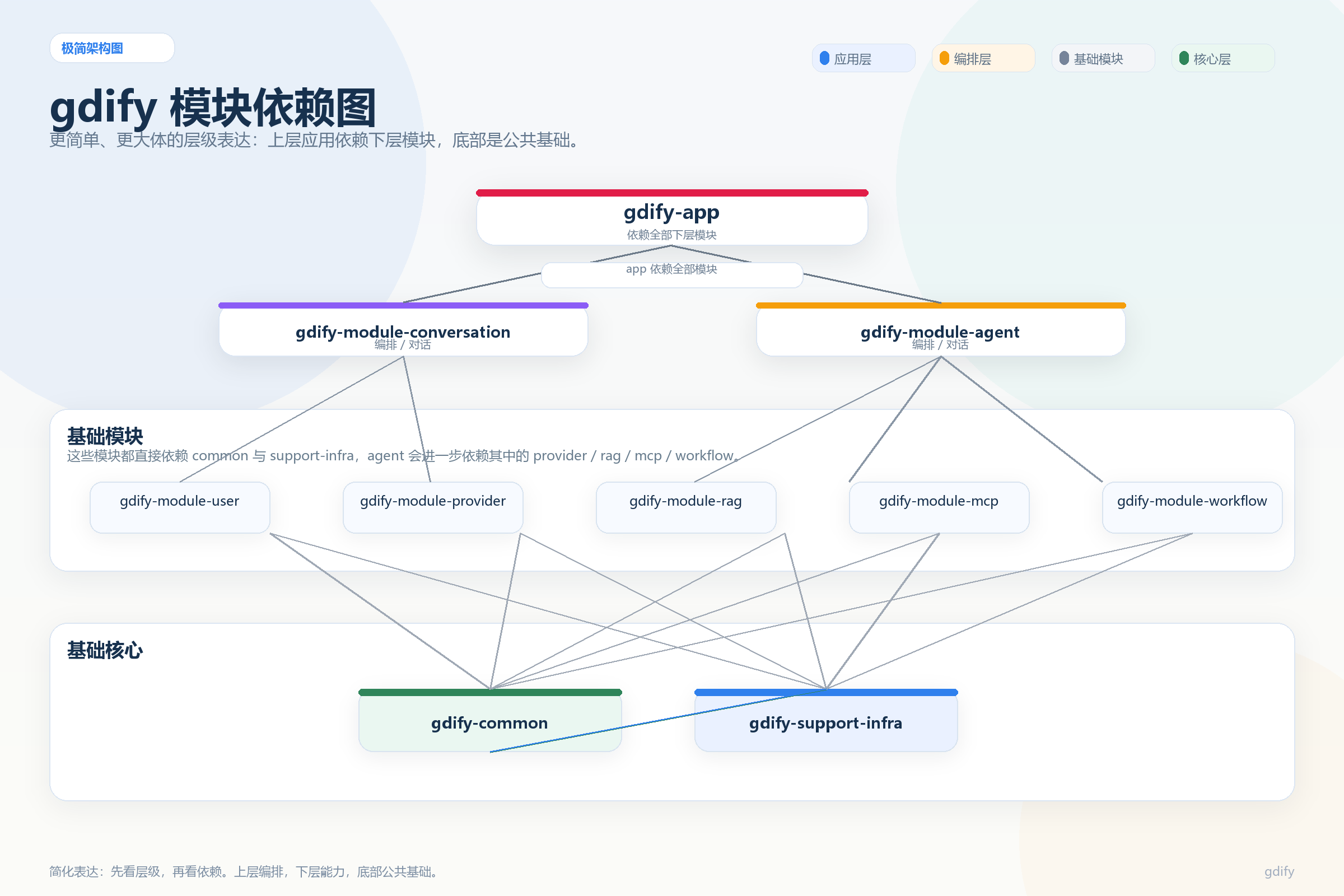
关键原则:依赖是单向的,不能循环。如果出现了循环依赖,说明模块边界画错了,需要把公共的部分下沉到common模块中。
Spring代码组织规范
这一点肯定很多人都觉得没什么意义,MVC三层架构谁不知道?
能写代码确实不要讲,但是那是因为你凭借经验和习惯,自然知道业务层要放serverice,control层只做参数校验。但是AI不知道,你不告诉他规矩,他可能把事物管理写在control层,把数据库查询写在DTO里,直接引用另一个模块的mpper,把这两个模块焊死。
这些规范不是给人看的,而是给AI编辑器看的。后面的每一行代码都是它生成。这些规矩定不好,生出来的代码越多越乱
我让AI编辑器帮我梳理
Gdify是模块化单体,用spring boot加mybatis plus。帮我定义代码组织规范,覆盖:每个模块内部的分层,每一层的职责边界,划模块调用的规则。要求具体到AI能直接执行,不要模糊描述。

-
Controller只做两件事 :参数校验和调用service。不写业务逻辑,不做数据查询,不做事务处理。为什么要这么严格?因为AI编辑器特别喜欢在contrl层里面顺手加逻辑,它觉得方便。但是你后面测试重构和拆分全都要受影响
-
service处理所有业务逻辑,包括事务管理、数据校验、业务规则。service之间可以互相调用,但只能调用接口,不能new时现类
-
mapper只做数据库操作,不要在mapper的xml里面写业务逻辑,那是service的事
-
entry和数据库表一一对应。DTO是接口用的请求或响应对象entry和DTO之间要做转换,不要把entry直接返回给前端entry里面可能有敏感字段APIKey,DTO可以控制暴露哪些字段
模块调用规则:这条是模块单体化最关键的规范,模块之间只能通过service接口调用,不能直接引用另一个模块的mpper entry或内部类
为什么?因为我们选模块化单体,最重要的一个理由就是后续能拆分。只通过service调用拆分时,只需要把本地调用改为http或RPC调用,接口签名都不用变。而如果两个模块调用的是mpper拆分时,你就需要把所有这种应用找出来改为远程调用。
我继续追问:
如果有一天要把Gdify拆分为独立服务,按这套规范,改动量大概多大?

分析了一下:service接口不变,实现类的内部本地调用,改为Fegin远程调用,加上网络异常处理。每个跨模块调用点改两三行代码,改动量可控。
外部调用设计
Gdify最大的技术挑战不在CRUD,而在外部LLM调用。瓶颈不再并发,而在LLM长连接占用线程。
LLMAPI调用有三个特点:慢(一次对话3秒到30秒),不稳定的(随时可能超时限流报错),多供应商(每家行为不一样)。不提前设计好,上线就得爆炸。
我让Codex系统性的分析
Gdify要调用多个外部LLMAPI,这些调用慢且不稳定。从线程管理,容错、超时、重试四个维度给我完整的技术方案

我又追问了一个他没有主动提到的问题
流式响应是向引用SSE,spring MVC怎么处理?需不需要引入webflux

总结
这一节课我们做了三件事,确定了模块化单体的应用架构,定义了spring代码组织规范,设计了外部调用处理方案。
每一次追问背后都是你在用项目的真实约束来修正AI的通用建议。AI给的是技术上最优方案。你要基于约束选对你最优的方案,这两者经常不一样。
还有一点值得强调,代码组织规范看起来是常识,但对AI写代码是刚需,人凭习惯知道controller不写业务逻辑。AI不知道,你不告诉他,他就按自己的理解来,而且每次理解都不一样,这些规范,现在花半小时定好,后面几百次代码都终身受益。
转载自CSDN-专业IT技术社区
原文链接:https://blog.csdn.net/guslegend/article/details/161440079

