
数据类型&大小端&字节对齐
数据类型
数据类型在嵌入式中也属于是一个小重点,为什么会这么说呢,因为现在单片机对内存都是非常注重的,所以说我们需要将所有的类型还有所占的字节都要非常清楚,必须精打细算。比如在很多情况下能够通过short来表示整数的时候就是不会利用int因为通过这样就是可以减少不必要的内存开销,但是在我们平常嵌入式代码的编写的时候常常就是需要使用到int8_t,int16_t,等等通过这些来表示出来字节大小的,因为通过这样使用可以增强芯片代码的移植性,因为可能一个int在一个芯片上是2字节,在另外一个芯片上是4字节,这就会导致字节不一致,但是int8_t就是固定是8位(也就是一字节)的内存,而嵌入式就是要在固定内存空间中实现功能,所以说了解数据类型对嵌入式还是非常重要。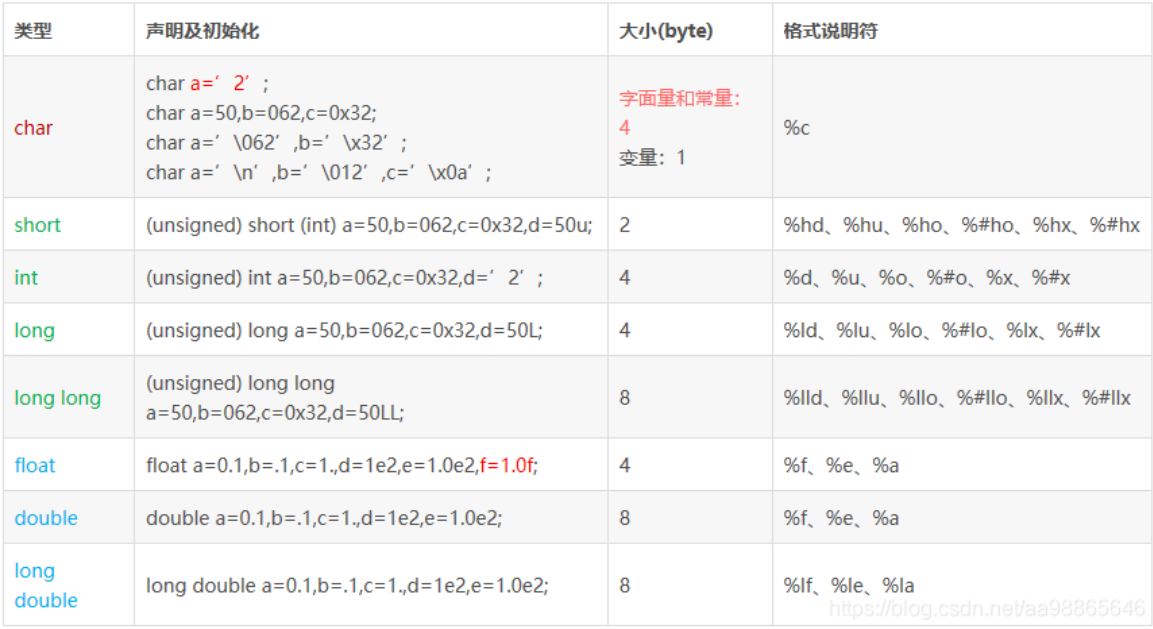
上图是c语言中的八大基本类型及其包含的字节数,可提供读者详细阅读。
不管是什么数据类型都是内部都是由01组成的机器码,比如我们拿short来表示5和int来表示5
short a=5; //内部就是 00000000 00000101
int b=5; //内部就是 00000000 00000000 00000000 00000101
相比较两者是不是就是int类型浪费的内存空间比较多,所以如果在够用的前提下尽量选择小的内存来节省单片机中的内存使用,这也让我们需要知道每一个类型中的数值范围,方便我们更好的编写代码,而尽量不出错。
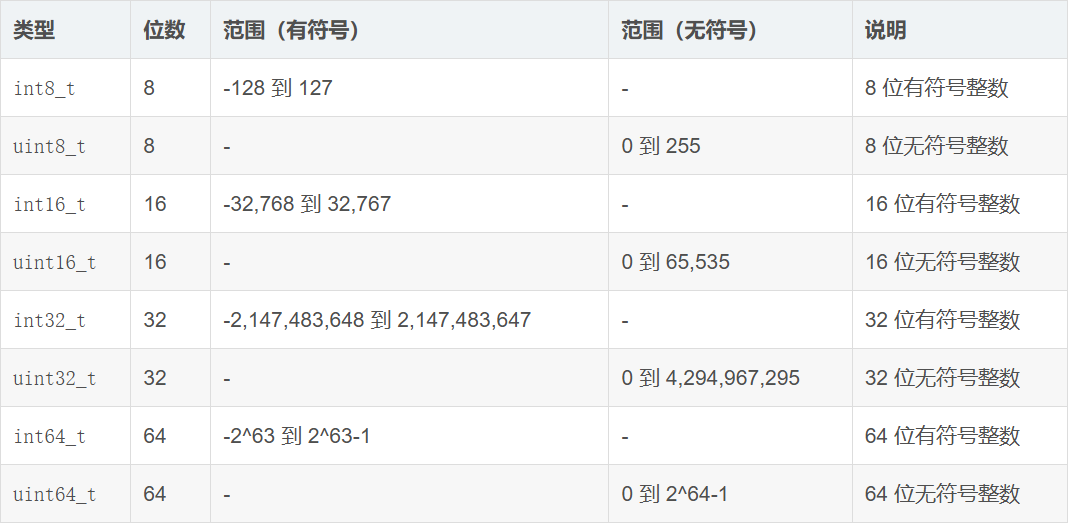
上图则为嵌入式中常用的类型,嵌入中其实一般都是使用无符号类型(uint8_t,uint16_t),类型宽度也就是决定了寄存器的宽度,其实上图中的类型和c语言中的类型都是差不多的,只是嵌入式中的类型移植性更强,更加适合操作寄存器。
大小端
大端:大端序将数据的最高有效字节存储在内存的最低地址处,而最低有效字节则存储在最高的地址处。
小端:小端序将数据的最高有效字节存储在内存的最高地址处,而最低有效字节则存储在最低的地址处。
通俗一点就是大端就是将低位数据存在高位地址上,高位数据存储在低位地址上的一种存储方式,小端就是将低位数据存储在低位地址上,高位数据存储在高位地址上。对于地址的高低位来说就是我们一般都是线性递增的,比如说0x00 0x01,其中0x00就是低位而0x01就是高位,但是对于数据位而言,比如0x12345678中可以拆分为0x12 0x34 0x56 0x78这四个数据,数据中是最右边为低位,依次向左就是数据位递增就是由低到高
下面通过int num=0x12345678来进行举例说明就是大端和小端的区别
| 地址 | 0x00 | 0x01 | 0x02 | 0x03 |
|---|---|---|---|---|
| 大端 | 0x12 | 0x34 | 0x56 | 0x78 |
| 小端 | 0x78 | 0x56 | 0x34 | 0x12 |
从上图也可以看出来很多东西,大端存储更符合我们人类从左向右的阅读习惯,所以也可以通过这个来帮助记忆就是判断大小端就是看是否就是数值中的值与实际中的地址值是顺着的就是大端,若不是就是小端。从上面也不难看出来就是大小端是一种大于等于2字节数据读取时需要注意的东西,相同数据利用大端和小段判断出来的完全不一样,所以要是碰到大小端不同的设备进行代码的迁移,会产生数据错乱等各种问题,所以在判断大小端中变得尤为重要,所以下面会讲诉一些有关大小端的判断还有大小端互换的一些方法。
大小端判断
联合体法
//联合体法判断,利用联合体中成员公用一块内存的方式
union duan{
int temp;
char arr[sizeof(int)];
};
int main(){
union duan u;
//要是将联合体中temp设置为temp=0x12345678
u.temp=0x12345678;
//那么就会由于大小端的区别,每一个设备可能产生不一样的结果
//大端的设备:00010010 00110100 01010110 01111000
//小端的设备:01111000 01010110 00110100 00010010
//所以在后续判断中就可以
if(u.arr[0]==0x12){
printf("该设备为大端设备");
}else{
printf("该设备为小端设备");
}
return 0;
}
指针法
//利用指针指向类型都是指向类型的首地址还有地址类型的地址都是指该类型中的首地址来进行判断
int main()
{
uint32_t temp=0x12345678;
//赋值之后,temp内部可能是
//地址 0x00 0x01 0x02 0x03
//值 0x12 0x34 0x56 0x78
char* q=(char*)&temp; //利用char*指针来指向temp中的首地址,char类型代表只读取一次
//对q进行解引用的话就是得到q地址上的值,利用这个值来判断是大端还是小端
if(*q==0x12){
printf("该设备为大端设备");
}else{
printf("该设备为小端设备");
}
}
以上是我介绍的最常用也是最实用的两种判断大小端的方式,这两种方式可以进行跨平台处理,是最主流判断大小端的方式。当然还有利用宏定义的还有通过标准库的方式,后面这两种方式平台通用性比较弱,一般不推荐。
大小端互换
由上面知识就可以知道,大端设备和小端设备在2字节以上的数据读取时一般是不会相同的,所以说在大端设备与小端设备进行交互的时候,大小端转化就变的尤为重要了,首先就是我们知道大小端的区别就是读取数据的方式不一样,我们可以通过这一特性来实现大小端互换。
位运算转化法
//因为数据都是存的是机器码,所以说我们可以通过位操作来实现大小端互换的操作
//因为现在数据只有8位,16位,32位,64位四种大小的数据类型
//8位数据大小端读取都是相同的,所以说我们只考虑16位 32位 64位的数据大小
uint16_t swap_16(uint16_t val){
return (val<<8)|(val>>8);
}
//32位和64位进行位操作的时候需要通过掩码来进行
//比如大端设备中数据是0x12345678 需要将0x12345678整体向右移动8位
//此时就变成了 0x00123456 此时要是不通过掩码来实现不了只取其中的两位
uint32_t swap_32(uint32_t val){
return ((val>>24) & 0x000000ffU)|
((val>>8) & 0x0000ff00U)|
((val<<8) & 0x00ff0000U)|
((val<<24) & 0xff000000U);
}
uint64_t swap_64(uint64_t val){
return ((val>>56) & 0x00000000000000ffULL)|
((val >> 40) & 0x000000000000ff00ULL) |
((val >> 24) & 0x0000000000ff0000ULL) |
((val >> 8) & 0x00000000ff000000ULL) |
((val << 8) & 0x000000ff00000000ULL) |
((val << 24) & 0x0000ff0000000000ULL) |
((val << 40) & 0x00ff000000000000ULL) |
((val << 56) & 0xff00000000000000ULL);
}
//上方后缀名是为了让编译器更好的识别,减少出错的
联合体转化法
//通过上面我讲述的一个通过联合体来判断大小端的方法
//你们心里大概有一个思路就是如何通过联合体来进行大小端的转换了吧
//核心思想:还是通过数据共用一片内存空间来进行实现的
uint16_t swap_16(uint16_t val){
union duan{
uint16_t val;
uint8_t arr[2];
};
//将val赋值到联合体中,比如u.val=5 机器码就是 00000000 00000101
//此时如果是大端设备 arr[0]中就是 00000000 arr[1]中就是 00000101
//此时如果是小端设备 arr[0]中就是 00000101 arr[1]中就是 00000000
//本质还是位操作
//通过联合体之后
union duan u;
u.val=val;
uint8_t temp=u.arr[0];
u.arr[0]=u.arr[1];
u.arr[1]=temp;
return u.val;
}
uint32_t swap_32(uint32_t val){
union duan{
uint32_t val;
uint8_t arr[4];
};
union duan u;
u.val=val;
for(int i=0;i<2;++i)
{
uint8_t temp=u.arr[i];
u.arr[i]=u.arr[3-i];
u.arr[3-i]=temp;
}
return u.val;
}
//上面是直观理解的数据的交换,下面我使用就是工业级大小端的互换,如果利用联合体的话,一般都是通过位运算
//因为位运算是计算机中最擅长的,所有执行速度是最快的,也是嵌入式中的首选
//我们就是只通过这个来实现大端转小端
uint32_t swap_32_max(uint32_t val){
union duan{
uint32_t val;
uint8_t arr[4];
};
union duan u;
u.val=val;
return (u.arr[0]<<24)|(u.arr[1]<<16)|(u.arr[2]<<8)|u.arr[3];
//假设输入为val=0x12345678
//大端设备的话就是arr[0]=0x12 arr[1]=0x34 arr[2]=0x56 arr[3]=0x78
//(实际就是最后两位,这样写出来就是为了更好的观察其中位置的变化)
//arr[0]=0x00000012 arr[0] 0x00000012
//arr[1]=0x00000034 arr[1]<<8 0x00003400
//arr[2]=0x00000056 arr[2]<<16 0x00560000
//arr[3]=0x00000078 arr[3]<<24 0x78000000
//所以说通过u.arr[0]|(u.arr[1]<<8)|(u.arr[2]<<16)|(u.arr[3]<<24)=0x78563412
//假设输入为val=0x12345678
//小端设备下是arr[0]=0x78 arr[1]=0x56 arr[2]=0x34 arr[3]=0x12
//(实际就是最后两位,这样写出来就是为了更好的观察其中位置的变化)
//arr[0]=0x00000078 arr[0] 0x00000078
//arr[1]=0x00000056 arr[1]<<8 0x00005600
//arr[2]=0x00000034 arr[2]<<16 0x00340000
//arr[3]=0x00000012 arr[3]<<24 0x12000000
//所以说通过(u.arr[3]<<24)|(u.arr[2]<<16)|(u.arr[1]<<8)|u.arr[0]=0x12345678
}
//大小端的情况下arr存储的顺序正好和要转变之后所要的情况相反
//所以大小端互换的通用代码就是
uint32_t swap_32_min(uint32_t val){
union duan{
uint32_t val;
uint8_t arr[4];
};
union duan u;
u.val=val;
return (u.arr[3]<<24)|(u.arr[2]<<16)|(u.arr[1]<<8)|u.arr[0];
}
//类似的 64位也是同理
以上就是大小端互换的判断和互换,当然还有指针法,但是一般嵌入式都是采用位操作的形式来进行大小端互换,效率比较高。
大小端数据阅读是主要针对其中一个数据来进行大小端的阅读(而不是一堆数据一起,是对于每一个单独的个体来进行的),大小端转化的重要性就是在文件中,很多协议中,比如就是网络协议,设备之间的交互问题上,很多时候需要判断大小端,并且就是进行大小端转化就是可以达到一个通信目的。
字节对齐
字节对齐和大小端都是差不多的,大小端决定的是一个数据的读取顺序,但是字节对齐是决定着内存还有字节中的数据的位置分布的
#pragma pack(1) //这个就是代表着是以一字节进行对齐来处理的
//一般GCC系统,或者以c语言为底层的设备都是具备的
//字节对齐,可以决定着内部的数据存放是怎么样的
struct stu{
char ch;
int temp;
};
struct stu kk;
kk.ch='a'; //就是数字97
kk.temp=0x12345678;
//以1字节对齐的话,内部就是,
//大端设备: 0x61 0x12 0x34 0x56 0x78
//小端设备: 0x61 0x78 0x56 0x34 0x12
//此时结构体为5字节
#pragma pack(4) //要是以4字节来处理的话
//大端设备: 0x61 0x00 0x00 0x00 0x12 0x34 0x56 0x78
//小端设备: 0x61 0x00 0x00 0x00 0x78 0x56 0x34 0x12
//此时结构体为8字节
还有字节对齐大小可能会在结构体中产生不一样的结构,也是经常有坑的地方
#pragma pack(8)
struct stu{
char ch;
int temp;
};
//这里需要注意的就是,虽然系统中是8字节对齐
//但是结构体中的字节对齐是取决于,结构体中最大的非静态变量类型的字节大小和系统编排的最小值
//结构体中类型往往就是够用就好,所以当系统字节对齐为8时,结构体中的对其字节是4字节
//所以说结构体内存是8字节
#pragma pack(2)
//此时结构体内存分布就是6字节,因为系统编排内存就是2字节,内部最大非静态变量是4字节
//注:指针也算是非静态变量,且字节是和处理器相关的
//所以字节对齐为2字节
//但是其中大于2字节的类型,其类型大小不用发生改变,int 还是4字节,但是char类型需要补充1字节
通过上面的代码就会发现,要是字节对齐方式不同的设备进行交互就会产生乱码,所以说字节对齐和大小端这两个是设备交互的前提。
转载自 CSDN-专业IT技术社区
原文链接:https://blog.csdn.net/2501_93706491/article/details/159583258

